本文参考:
https://www.jianshu.com/p/9ee85fdad150
https://blog.csdn.net/xyu66/article/details/80044991
http://lidequan12345.blog.163.com/blog/static/28985036201303181045965/
https://blog.csdn.net/wangxiaopeng0329/article/details/53542606
《机器学习》周志华
————————————————————————————————————————————
评价指标指的就是用什么标准去评价你,评价对象为训练得到的学习器的泛化能力。评价一个模型的好坏需要三个东西,预测结果、真实结果和评价标准,前两者无需介绍,今天来介绍一下常用的评价标准。
一、回归
均方误差(MSE)
回归问题最常见的评价指标就是均方误差。给定数据 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) } D=\{(x_1,y_1),(x_2,y_2),...,(x_m,y_m)\} D={
(x1,y1),(x2,y2),...,(xm,ym)},其中 y i y_i yi为 x i x_i xi的真实标签。设 f f f为待评估的学习器,那么均方误差的表达式为:
E ( f ; D ) = 1 m ∑ i = 1 m ( f ( x i ) − y i ) 2 E(f;D)=\frac{1}{m}\sum^{m}_{i=1}(f(x_i)-y_i)^2 E(f;D)=m1i=1∑m(f(xi)−yi)2
对于数据分布 D D D和概率密度函数 p ( ) p() p(),均方误差又可描述为:
E ( f ; D ) = ∫ x , D ( f ( x ) − y ) 2 p ( x ) d x E(f;D)=\int_{x,D}(f(x)-y)^2p(x)dx E(f;D)=∫x,D(f(x)−y)2p(x)dx
均方根误差(RMSE)
就是均方误差开根号,没啥可介绍的,非要把mse开根号再作为一个指标的理由是有些时候便于描述数据。
R M S E = 1 m ∑ i = 1 m ( f ( x i ) − y i ) 2 RMSE=\sqrt{\frac{1}{m} \sum_{i=1}^{m}\left(f(x_{i})-{y}_{i}\right)^{2}} RMSE=m1i=1∑m(f(xi)−yi)2
平均绝对误差(MAE)
M A E = 1 m ∑ i = 1 m ∣ ( y i − y ^ i ) ∣ MAE=\frac{1}{m} \sum_{i=1}^{m}\left|\left(y_{i}-\hat{y}_{i}\right)\right| MAE=m1i=1∑m∣(yi−y^i)∣
R^2
先来看下表达式:
R 2 = 1 − ∑ ( y − f ( x i ) ) 2 ∑ ( y − y ‾ ) 2 R^{2}=1-\frac{\sum(y-f({x_i}))^{2}}{\sum(y-\overline{y})^{2}} R2=1−∑(y−y)2∑(y−f(xi))2
R 2 R^2 R2也叫拟合优度,用来描述回归对数据的拟合程度,定义为因变量y的总离差中能被自变量x所解释的占比。分母是真实标签总的离差平方和,分子是预测值与真实值离差的平方和,显然 R 2 R^2 R2是越大越好。
我们可以这样不恰当地理解 R 2 R^2 R2,它其实就是找了一个基点去判断预测结果的好坏,这个基点的值就是 y y y的均值,我们不妨把它认为是人工猜测的结果。那么 R 2 R^2 R2就是在说明通过自变量进行预测之后结果比猜好多少?(当然猜肯定不可能每个值都猜均值,只是个不恰当的比喻)
python代码实现
MSE=np.sum((y_preditc-y_test)**2)/len(y_test)
RMSE=MSE ** 0.5
MAE=np.sum(np.absolute(y_preditc-y_test))/len(y_test)
R2=1- mean_squared_error(y_test,y_preditc)/ np.var(y_test)
###sklearn应用
from sklearn.metrics import mean_squared_error #均方误差
from sklearn.metrics import mean_absolute_error #平方绝对误差
from sklearn.metrics import r2_score #R square
mean_squared_error(y_test,y_predict)
mean_absolute_error(y_test,y_predict)
r2_score(y_test,y_predict)
二、分类
错误率与精度
这俩比较简单,一个是预测错的数量比总数,一个是预测正确的数量比总数,二者和为1
E r r o r = 1 m ∑ i = 1 m ( f ( x i ) ≠ y i ) Error=\frac{1}{m}\sum^{m}_{i=1}(f(x_i)\neq y_i) Error=m1i=1∑m(f(xi)̸=yi) A c c = 1 m ∑ i = 1 m ( f ( x i ) = y i ) = 1 − E r r o r Acc=\frac{1}{m}\sum^{m}_{i=1}(f(x_i)=y_i)=1-Error Acc=m1i=1∑m(f(xi)=yi)=1−Error
查准率、查全率与F1
首先来看一下混淆矩阵

图中字母的含义为:
TP(True Positive): 真实为0,预测也为0
FN(False Negative): 真实为0,预测为1
FP(False Positive): 真实为1,预测为0
TN(True Negative): 真实为0,预测也为0
查准率定义:
P = T P T P + F P P=\frac{TP}{TP+FP} P=TP+FPTP
查准率一般是针对正例来说的,当然如果熟悉了它的定义和公式,完全可以推广到反例。数学表达式中分子为真正例,也就是说正例中你预测对的。分母为真正例加假正例,加起来的结果就是你模型认为的正例的总数。查准率的含义从名字就能体现出来,模型认为的正例中,有多少是对的,也就是你正例预测地准不准。查准率也称为准确率。
查全率定义:
R = T P T P + F N R=\frac{TP}{TP+FN} R=TP+FNTP
查全率的表达式的分子为真正率,分母为真正例加假反例,也就是真是标记中正例的数量。顾名思义,查全率的含义为所有正例中,你模型预测对了多少,也就是你正例预测地全不全。查全率也叫召回率,有些场合下
这一对儿指标一般来说是相互矛盾的,从原理上来说很好解释。当你注重查准率的时候,一定会把判断正例的标准变得严格,因为你更在乎判断的准不准,这种情况下就会有很多不那么容易辨认的正例没被认出来,自然查全率就会低。同样的,当你注重查全率时,就会把判断正例的标准变宽松,极端的例子就是把所有的样本都判断为正例,这样正例被查的非常全,但查准率自然就不可能高了。
F1定义:
F 1 = 2 ∗ P ∗ R P + R = 2 ∗ T P 样 本 总 数 + T P − T N F1=\frac{2*P*R}{P+R}=\frac{2*TP}{样本总数+TP-TN} F1=P+R2∗P∗R=样本总数+TP−TN2∗TP怎么来的?其实 F 1 F1 F1指标是查准率与查全率的调和平均,即:
1 F 1 = 1 2 ⋅ ( 1 P + 1 R ) \frac{1}{F 1}=\frac{1}{2} \cdot\left(\frac{1}{P}+\frac{1}{R}\right) F11=21⋅(P1+R1)将这个公式推导一下即可。这只是简单的调和平均,如果我们加权调和平均,就会得到一个有偏向的F1指标:
1 F β = 1 1 + β 2 ⋅ ( 1 P + β 2 R ) F β = ( 1 + β 2 ) × P × R ( β 2 × P ) + R \frac{1}{F_{\beta}}=\frac{1}{1+\beta^{2}} \cdot\left(\frac{1}{P}+\frac{\beta^{2}}{R}\right) \\F_{\beta}=\frac{\left(1+\beta^{2}\right) \times P \times R}{\left(\beta^{2} \times P\right)+R} Fβ1=1+β21⋅(P1+Rβ2)Fβ=(β2×P)+R(1+β2)×P×R从中可以看出,当 β = 1 \beta=1 β=1时退化为标准的F1,当 β > 1 \beta>1 β>1查全率有更大影响,当 β < 1 \beta<1 β<1时查准率有更大影响。
ROC与AUC:
ROC全称"受试者工作特征",ROC曲线的纵轴为真正例率(True Postive Rate,TPR),横轴是假正例率(False Postive Rate,FPR)。
T P R = T P T P + F N F P R = F P T N + F P \begin{aligned} \mathrm{TPR} &=\frac{T P}{T P+F N} \\ \mathrm{FPR} &=\frac{F P}{T N+F P} \end{aligned} TPRFPR=TP+FNTP=TN+FPFPTPR含义为所有正例中有多少预测对了,FPR的含义为所有反例中有多少被模型认成了正例。
ROC曲线的画法为将所有预测结果按可能性排序,排在前面的为正例的可能性最大,之后依此降低。依次将所有阈值作为分割点,计算真正例率和假正例率,然后在图中画出。
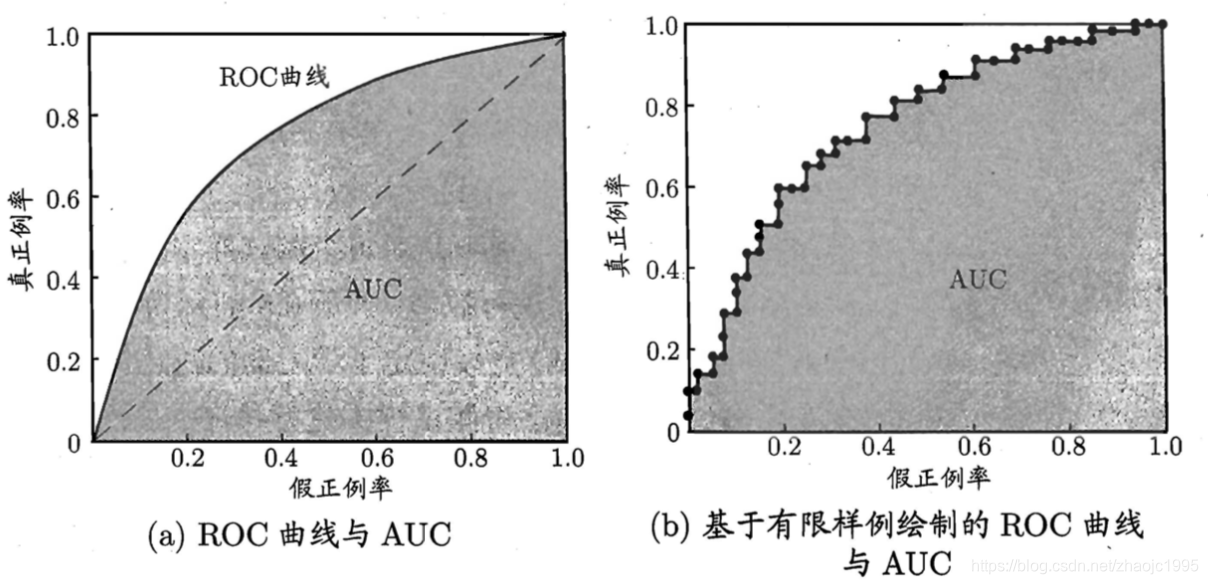
理想情况肯定是左图,但样本数是有限的,所以一般情况为右图。当一个模型的ROC曲线完全包裹另一个模型时,说明这个模型要更优。但万一不是完全包裹而是交叉呢?那么就用面积来做比较,也就是AUC(Area Under ROC Curve)。
三、聚类
主要分为内部指标和外部指标。外部指标指的是将聚类结果与“参考模型”相比较(一般认为参考模型是标准答案),内部指标就是不利用任何参考模型。
1、外部指标
直接偷懒引用西瓜书的定义了

Jaccard系数
J C = a a + b + c JC=\frac{a}{a+b+c} JC=a+b+ca
说白了就是交集比并集。
FM指数
F M I = a a + b ∗ a a + c FMI=\sqrt{\frac{a}{a+b}*\frac{a}{a+c}} FMI=a+ba∗a+ca
Rand指数
R I = 2 ( a + d ) m ( m − 1 ) = a + d C n s a m p l e s 2 RI=\frac{2(a+d)}{m(m-1)}=\frac{a+d}{C_{n_{samples}}^2} RI=m(m−1)2(a+d)=Cnsamples2a+d
上述性能结果取值都在 [ 0 , 1 ] [0,1] [0,1],值越大越好。
2、内部指标
DB指数(Davies-Bouldin Index,简称DBI)
D B = 1 k ∑ i = 1 k max j ≠ i ( C i ‾ + C j ‾ ∥ w i − w j ∥ 2 ) D B=\frac{1}{k} \sum_{i=1}^{k} \max_{ j \neq i}\left(\frac{\overline{C_{i}}+\overline{C_{j}}}{\left\|w_{i}-w_{j}\right\|_{2}}\right) DB=k1i=1∑kj̸=imax(∥wi−wj∥2Ci+Cj)
DB计算 任意两类别的类内距离平均距离(CP)之和除以两聚类中心距离 求最大值
DB越小意味着类内距离越小 同时类间距离越大
缺点:因使用欧式距离 所以对于环状分布 聚类评测很差
Dunn指数(Dunn Index,简称DI)
D V I = min 0 < m ≠ n < K { min ∀ x i ∈ Ω n ∀ x j ∈ Ω m { ∥ x i − x j ∥ } } max 0 < m ≤ K ∀ x i , x j ∈ Ω m { ∥ x i − x j ∥ } D V I=\frac{\min _{0<m \neq n<K}\left\{\min _{\forall x_{i} \in \Omega_{n} \atop \forall x_{j} \in \Omega_{m}}\left\{\left\|x_{i}-x_{j}\right\|\right\}\right\}}{\max _{0<m \leq K \forall x_{i}, x_{j} \in \Omega_{m}}\left\{\left\|x_{i}-x_{j}\right\|\right\}} DVI=max0<m≤K∀xi,xj∈Ωm{
∥xi−xj∥}min0<m̸=n<K{
min∀xj∈Ωm∀xi∈Ωn{
∥xi−xj∥}}
DVI计算 任意两个簇元素的最短距离(类间)除以任意簇中的最大距离(类内)
DVI越大意味着类间距离越大 同时类内距离越小
缺点:对离散点的聚类测评很高、对环状分布测评效果差
轮廓系数
单个样本点的轮廓系数计算方法如下:
s ( i ) = b ( i ) − a ( i ) max { a ( i ) , b ( i ) } s(i)=\frac{b(i)-a(i)}{\max \{a(i), b(i)\}} s(i)=max{
a(i),b(i)}b(i)−a(i)
计算样本 i i i到同簇其他样本的平均距离 a i a_i ai。 a i a_i ai 越小,说明样本 i i i越应该被聚类到该簇。将 a i a_i ai 称为样本 i i i的簇内不相似度
计算样本 i i i到其他某簇 C j _Cj Cj的所有样本的平均距离 b i j b_{ij} bij,称为样本 i i i与簇 C j C_{j} Cj的不相似度。定义为样本 i i i的簇间不相似度
所有样本的 s i s_i si的均值称为聚类结果的轮廓系数,是该聚类是否合理、有效的度量。