总述:
为了评估机器学习算法在某项任务中好坏,需要我们设计方法去度量性能,比如,在分类任务中,我们经常衡量模型的精度(accuracy),即正确分类数据与全部分类数据的比值。与之相对应,我们去测量错误分类数据在全部分类数据比例,称之为错误率(error rate),也常将错误率称为0-1损失期望。
机器学习算法是在实际环境中运行的,也就是说,机器学习所面临的数据是未知的。生活告诉我们,实践才能出真知,但未来总是复杂多变的,庄子曾说过“吾生也有涯,而知也无涯,以有涯随无涯,殆已。”告诉我们要从已知中去追寻未知。因此我们需要“假造”一些未知数据,我们称之为测试数据集(test set of data),我们将训练好的机器学习算法拿到这些测数据集上进行性能测量,然后我们就“自欺欺人”的宣称我们设计的算法如何的好。测试数据也是已知数据的一部分,实际这部分数据我们首先密封起来,只在最终的性能测试时才用。
举例:
拿课程作为类比,平时做的练习题或者家庭作业就是我们的训练数据(trainning set of data),老师组织的月考、期中考,我们称之为验证数据,最后参加的期末考试我们称之为测试数据,这三部分数据全是已有的数据,其中训练数据只用来训练,学生(学习算法)的目标是在这部分数据上不断提高性能,而老师(算法调整人员)会使用验证数据监控学生的学习情况,然后去调整学生的学习方式,当老师认为该学生已经无法再提高时,就是用测试数据模拟未知数据对学生进行最后的性能测试。
一、查全率和查准率
错误率和精度是最常用的度量方式,但在特定的任务中,我们还需要一些额外的度量方式,比如进行信息检索时,我们经常需要关心“检索的信息中有多少是用户感兴趣的”以及“用户感兴趣的信息有多少被检索出来了”这两类问题,而此时,我们引入查准率(precision)与查全率(recall)
为了更好介绍查准率和查全率,以二分类问题为例子,我们需要将分类器预测结果分为以下4种情况。
- <1>真正例(True Positive,TP),分类器预测1,真实类标为“1”的分类数据。
- <2>假正例(False Positive,FP),分类器预测1,真实类标为“0”的分类数据。
- <3>真反例(True Negative,TN),分类器预测0,真实类标为“0”的分类数据。
- <4>假反例(False Negative,FN),分类器预测0,真实类标为“1”的分类数据
而TP+FP+TN+FN = 数据总量,如下表所示为混淆矩阵(Confusion Matrix)
| 真实情况 | 预测结果 | |
| 正例 | 反例 | |
| 正例 | TP(真正例) | FN(假反例) |
| 反例 | FP(假正例) | TN(真反例) |
如上表,
准确率(Accuracy),表示正确分类的测试实例的个数占测试实例总数的比例,计算公式为:
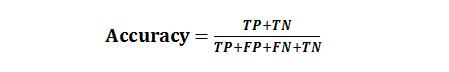
查准率(Precision),也称精确率,表示正确分类的正例个数占分类为正例的实例个数的比例:
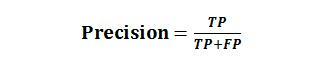
查全率(Recall),也称召回率,表示正确分类的正例个数占实际正例个数的比例:
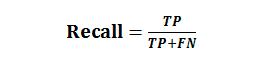
查准率和查全率是一对“鱼”与“熊掌”,一把来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。
例如,如果想将垃圾邮件都选取出来,可以将所有邮件都标签为垃圾邮件,那么查全率就接近于1,但这样查准率就会比较低;如果希望分类垃圾邮件的查准率足够高,那么可以让分类器尽可能挑选最有把握的垃圾邮件,但这样往往会有大量的垃圾邮件成为漏网之鱼,此时查全率就会比较低。
需要注意的是,性能度量也依赖于所需完成任务的应用场景。任务场景不同,度量手段也不同,如果性能度量选取不当,对于该任务可能是毁灭级的。比如我们让机器完成指纹识别任务,但应用在超市中和应用在安全机构部门的指纹识别系统,其度量方式完全不同。在某个超市会员系统中,需要识别用户的指纹以确定用户是否为会员,然后对部分商品进行打折或者抽奖服务,此时我们并不关心指纹识别的精准度,假设一个会员用户总是被识别错误,那么该用户就会非常恼火,超市很可能会失去一个老顾客。相反,将一个非会员顾客识别错误,其损失就没那么高,或许还有可能获得一个新会员,因此该任务更关心查全率,也就是期望所有会员都要被识别出来。但如果指纹识别应用到安全部门,用于识别员工的身份,此时我们就更关心识别员工的正确性,因此机器只会在最有“把握”的情况下才允许员工通过,此时我们更关心查准率。我们或许情愿对员工识别错误100次,也不愿意放过一个非员工,或许此时机器学习可能“非常不好用”,但安全性得到了报障。
二、P-R曲线、平衡点和F1度量
1、P-R曲线
在很多情形下,我们可根据学习器的预测结果对样例进行排序,排在前面的是学习器认为“最可能”是正例的样本,排在最后的是学习器认为“最不可能”是正例的样本。按此顺序设置不同的阈值,逐个把样本作为正例进行预测,则每次可以计算出当前的查准率、查全率。以查准率为纵轴、查全率为横轴作图,就得到了查准率-查全率曲线,简称“P-R曲线”,显示该曲线的图称为“P-R图”。

P-R图直观地显示出学习器在样本总体上的查全率、查准率。在进行比较时,若一个学习器的P-R曲线被另一个学习器的曲线完全“包住”,则可断言后者的性能优于前者,例如上图中学习器A的性能优于学习器C;如果两个学习器的P-R曲线发生了交叉,例如图1中的A和B,则难以一般性地断言两者孰优孰劣,只能在具体的查准率或查全率条件下进行比较。然而,在很多情形下,人们往往仍然希望把学习器A与B比出个高低。这时,一个比较合理的判断依据是比较P-R曲线下面积的大小,它在一定程度上表征了学习器在查准率和查全率上取得相对“双高”的比例。但这个值不太容易估算,因此,人们设计了一些综合考虑查准率、查全率的性能度量,比如BEP度量、F1度量。
2、平衡点(BEP)
“平衡点”(Break-Even-Point,简称BEP)就是这样一个度量,它是“查准率 = 查全率”时的取值,例如上图中学习器C的BEP是0.64,而基于BEP的比较,可认为学习器A优于B。
3、F1度量
BEP曲线还是过于简化了些,更常用的是F1度量。我们先来谈谈F1度量的由来是加权调和平均,
计算公式:F1 = 2 * F * R / ( F + R )
在一些应用中,对查准率和查全率的重视程度有所不同。例如在商品推荐系统中,为了尽可能少打扰用户,更希望推荐内容确实是用户感兴趣的,此时查准率更重要;而在逃犯信息检索系统中,更希望尽可能少漏掉逃犯,此时查全率更重要。
F1度量的一般形式是,能让我们表达出对查准率/查全率的不同偏好,它定义为公式如下所示
其中,β>0度量了查全率对查准率的相对重要性。
- β=1时,退化为标准的F1,查全率与查准率重要程度相同;
- β>1时,查全率有更大影响;
- β<1时,查准率有更大影响。
三、ROC曲线和AUC(度量分类中的非均衡性)
1、ROC曲线
TPR(True Positive Rate)表示在所有实际为正例(阳性)的样本中,被正确地判断为正例的比率,即:
TPR=TP/(TP + FN)
FPR( False Positive Rate)表示在所有实际为反例(阴性)的样本中,被错误地判断为正例的比率,即:
FPR=FP/(FP + TN)
ROC曲线是以FPR作为X轴,TPR作为Y轴。FPR越大表明预测正例中实际负例越多,TPR越大,预测正例中实际正例越多。ROC曲线如下图所示:

2、ROC曲线
AUC值(Area Unser the Curve)是ROC曲线下的面积,AUC值给出的是分类器的平均性能值。使用AUC值可以评估二分类问题分类效果的优劣,计算公式如下:

一个完美的分类器的AUC为1.0,而随机猜测的AUC为0.5,显然AUC值在0和1之间,并且数值越高,代表模型的性能越好。
Reference:
《深度学习实战》杨云 杜飞著
《机器学习》周志华著
