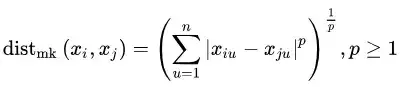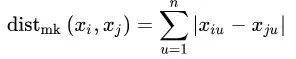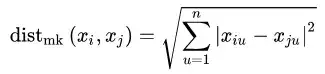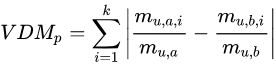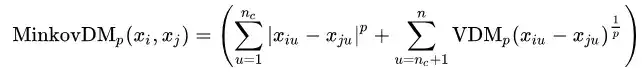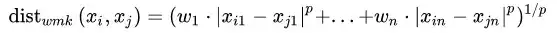在无监督学习中,训练样本的标记是没有指定的,通过对无标记样本的训练来探索数据之间的规律。其中应用最广的便是聚类,聚类试图把一群未标记数据划分为一堆不相交的子集,每个子集叫做”簇“,每个簇可能对应于一个类别标签,但值得注意的是,这个标签仅仅是我们人为指定强加的,并不是数据本身就存在这样的标签。例如音乐软件对音乐的曲分或者流派进行聚类,可以划分为伤感,轻快等一系列标签,但是这个曲分只是人为加上的,音乐本身并不知道自己被分为了什么曲分。
具体的性能度量有两类,一类是外部指标,与某个专家给定的参考模型进行比对,另一类是内部指标,只考虑自己聚类之后的结果。
外部指标需要一个参考模型,这个参考模型通常是由专家给定的,或者是公认的参考模型比如公开数据集。对于聚类的结果所形成的簇集合(这里叫做簇C),对于参考模型的簇集合(这里叫做D),对这两个模型结果的样本进行两两配对比较,可得到如下显而易见的数据。
a
=
∣
S
S
∣
,
S
S
=
(
x
i
,
x
j
)
∣
λ
i
=
λ
j
,
λ
i
∗
=
λ
j
∗
,
i
<
j
a=|SS|,SS={(x_i,x_j)|\lambda_i=\lambda_j,\lambda_i^*=\lambda_j^*,i<j}
a = ∣ S S ∣ , S S = ( x i , x j ) ∣ λ i = λ j , λ i ∗ = λ j ∗ , i < j
b
=
∣
S
D
∣
,
S
D
=
(
x
i
,
x
j
)
∣
λ
i
=
λ
j
,
λ
i
∗
=
/
 
λ
j
∗
,
i
<
j
b=|SD|,SD={(x_i,x_j)|\lambda_i=\lambda_j,\lambda_i^*{=}\mathllap{/\,}\lambda_j^*,i<j}
b = ∣ S D ∣ , S D = ( x i , x j ) ∣ λ i = λ j , λ i ∗ = / λ j ∗ , i < j
c
=
∣
D
S
∣
,
D
S
=
(
x
i
,
x
j
)
∣
λ
i
=
/
 
λ
j
,
λ
i
∗
=
λ
j
∗
,
i
<
j
c=|DS|,DS={(x_i,x_j)|\lambda_i{=}\mathllap{/\,}\lambda_j,\lambda_i^*=\lambda_j^*,i<j}
c = ∣ D S ∣ , D S = ( x i , x j ) ∣ λ i = / λ j , λ i ∗ = λ j ∗ , i < j
c
=
∣
D
D
∣
,
D
D
=
(
x
i
,
x
j
)
∣
λ
i
=
/
 
λ
j
,
λ
i
∗
=
/
 
λ
j
∗
,
i
<
j
c=|DD|,DD={(x_i,x_j)|\lambda_i{=}\mathllap{/\,}\lambda_j,\lambda_i^*{=}\mathllap{/\,}\lambda_j^*,i<j}
c = ∣ D D ∣ , D D = ( x i , x j ) ∣ λ i = / λ j , λ i ∗ = / λ j ∗ , i < j
对这里的abcd,不考虑一个样本属于多个簇的情况,因此每个样本都只能出现在一个集合中,所以a+b+c+d=m(m-1)/2。(m为样本总数)
常用来表示集合之间的相似性和差异性,常常被定义为集合交集大小与集合并集大小的比值,因此也常被叫做并交比。其公式为
J
C
=
a
a
+
b
=
c
JC=\frac{a}{a+b=c}
J C = a + b = c a
F
M
I
=
(
a
a
+
b
)
∗
(
a
a
+
c
)
FMI=\sqrt{(\frac{a}{a+b})*(\frac{a}{a+c})}
F M I = ( a + b a ) ∗ ( a + c a )
R
I
=
2
(
a
+
d
)
m
(
m
−
1
)
RI=\frac{2(a+d)}{m(m-1)}
R I = m ( m − 1 ) 2 ( a + d )
内部指标则只考虑聚类之后这些簇之间的效果,通常用距离来度量.
a
v
g
(
C
)
=
2
∣
C
∣
(
∣
C
∣
−
1
)
∑
1
≤
i
≤
j
≤
∣
C
∣
d
i
s
t
(
x
i
,
x
j
)
avg(C)=\frac{2}{|C|(|C|-1)} \sum_{\mathclap{1\le i\le j\le {|C|}}}dist(x_i,x_j)
a v g ( C ) = ∣ C ∣ ( ∣ C ∣ − 1 ) 2 1 ≤ i ≤ j ≤ ∣ C ∣ ∑ d i s t ( x i , x j )
d
i
a
m
(
C
)
=
m
a
x
1
≤
i
≤
j
≤
∣
C
∣
d
i
s
t
(
x
i
,
x
j
)
diam(C)=max_{{1\le i\le j\le {|C|}}} dist(x_i,x_j)
d i a m ( C ) = m a x 1 ≤ i ≤ j ≤ ∣ C ∣ d i s t ( x i , x j )
d
m
i
n
(
C
i
,
C
j
)
=
m
i
n
x
i
∈
C
i
,
x
j
∈
C
j
d
i
s
t
(
x
i
,
x
j
)
d_{min}(C_i,C_j)=min_{x_i\in{C_i},x_j\in{C_j}}dist(x_i,x_j)
d m i n ( C i , C j ) = m i n x i ∈ C i , x j ∈ C j d i s t ( x i , x j )
d
c
e
n
(
x
i
,
x
j
)
=
d
i
s
t
(
x
i
,
x
j
)
d_{cen}(x_i,x_j)=dist(x_i,x_j)
d c e n ( x i , x j ) = d i s t ( x i , x j )
avg©:簇C样本间的平均距离
这些簇间的距离指标也可以导出几个常见的性能度量内部指标,DB指数,Dunn指数。
D
B
I
=
1
k
∑
i
=
1
k
m
a
x
j
≠
i
(
a
v
g
(
C
i
)
+
a
v
g
(
C
j
)
d
c
e
n
(
u
i
,
u
j
)
)
DBI=\frac{1}{k}\displaystyle\sum_{i=1}^k max_{j\ne{i}}(\frac{avg(C_i)+avg(C_j)}{d_{cen}(u_i,u_j)})
D B I = k 1 i = 1 ∑ k m a x j ̸ = i ( d c e n ( u i , u j ) a v g ( C i ) + a v g ( C j ) )
D
I
=
m
i
n
1
≤
i
≤
k
(
m
i
n
j
≠
i
(
d
m
i
n
(
C
i
,
C
j
)
m
a
x
1
≤
l
≤
k
d
i
s
t
(
C
l
)
)
)
DI=min_{1\le{i}\le{k}}{(min_{j\ne i}(\frac{d_{min}(C_i,C_j)}{max_{1\le l\le k}dist(C_l)}))}
D I = m i n 1 ≤ i ≤ k ( m i n j ̸ = i ( m a x 1 ≤ l ≤ k d i s t ( C l ) d m i n ( C i , C j ) ) )
计算簇之间的相似性和差异性时常常要使用距离来进行度量,内部指标也都是以距离度量为基础的。
对于有序属性,我们最常使用的是闵科夫斯基距离
令
m
u
,
a
m_{u,a}
m u , a
令
m
u
,
a
,
i
m_{u,a,i}
m u , a , i