专业术语加强
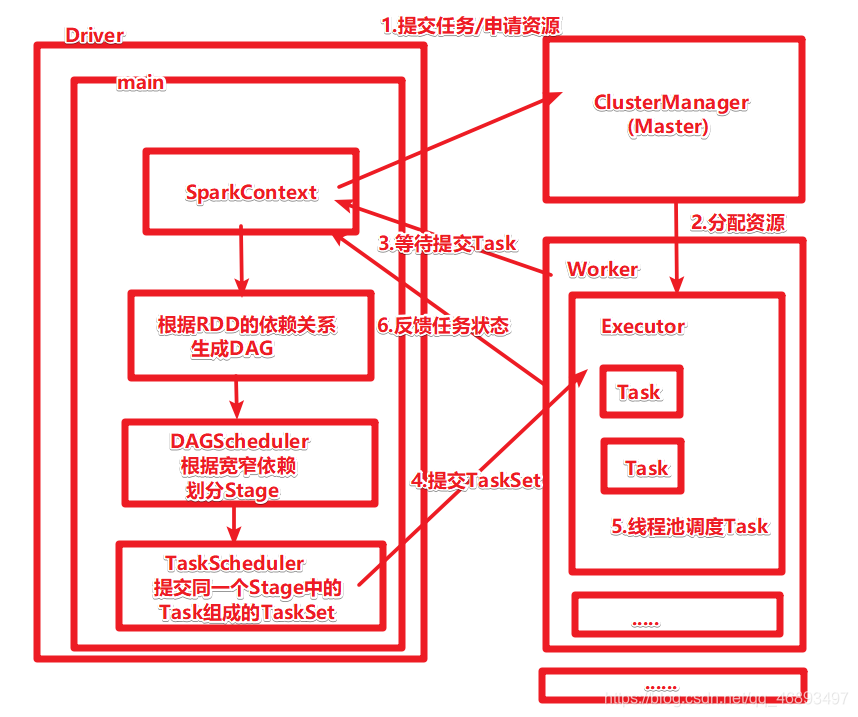
Application/App:Spark应用程序
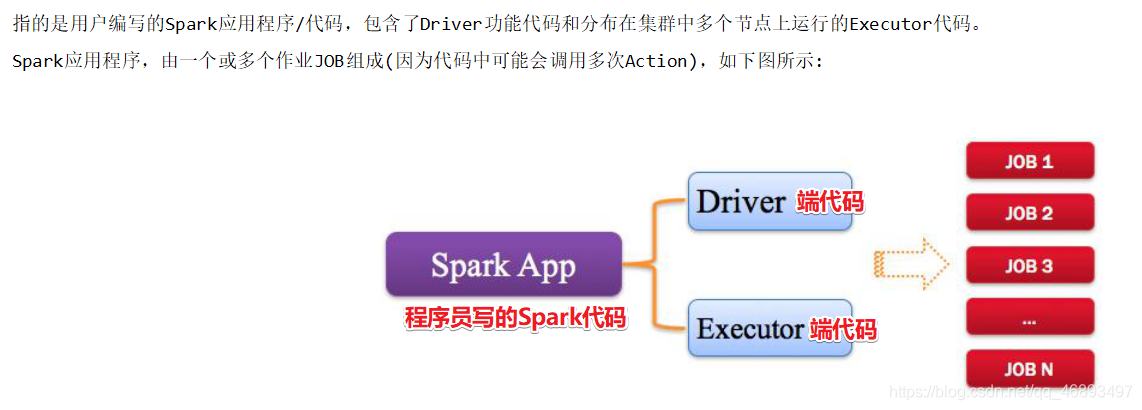
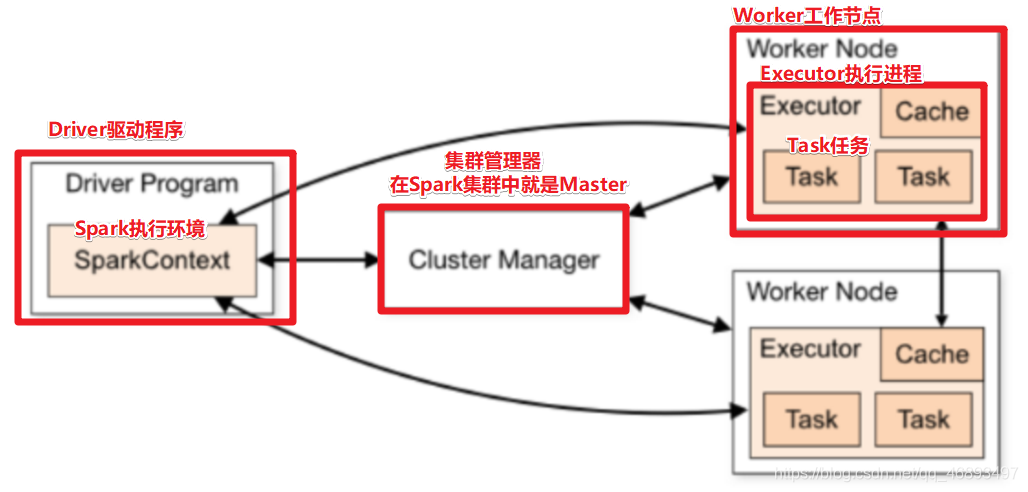
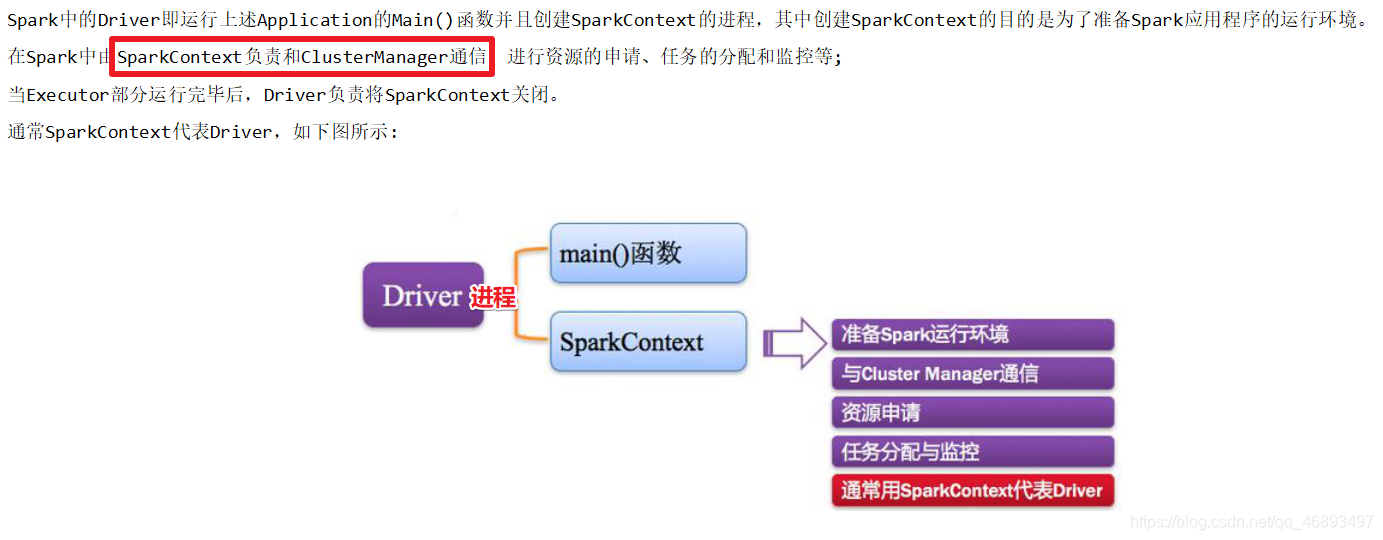
Driver:驱动程序
- 会由Driver进程运行main方法和创建SparkContext执行环境对象
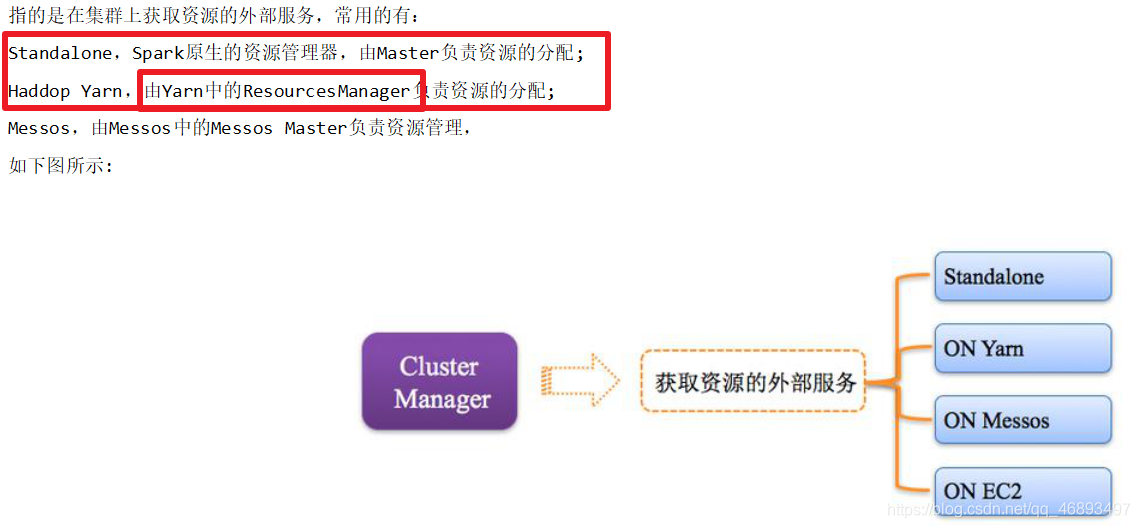
ClusterManager-资源管理器Master/ResourceManager
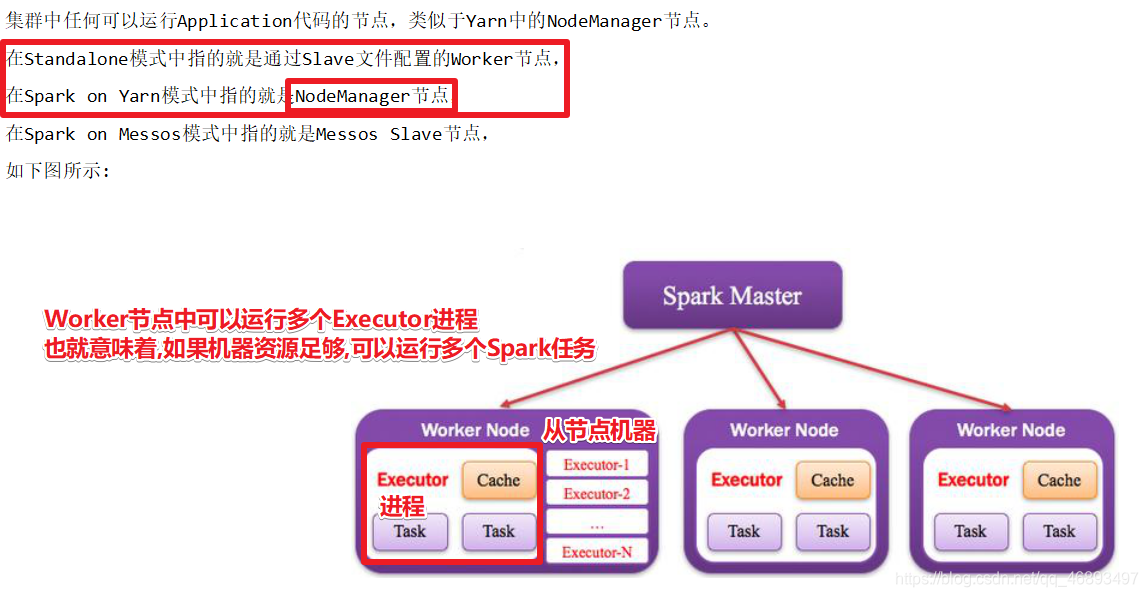
从节点-Worker/NodeManager
- Worker中可以运行多个Executor
- 每个Spark应用有自己独立的一批Executor
- 也就是多个Spark任务间是进程隔离的
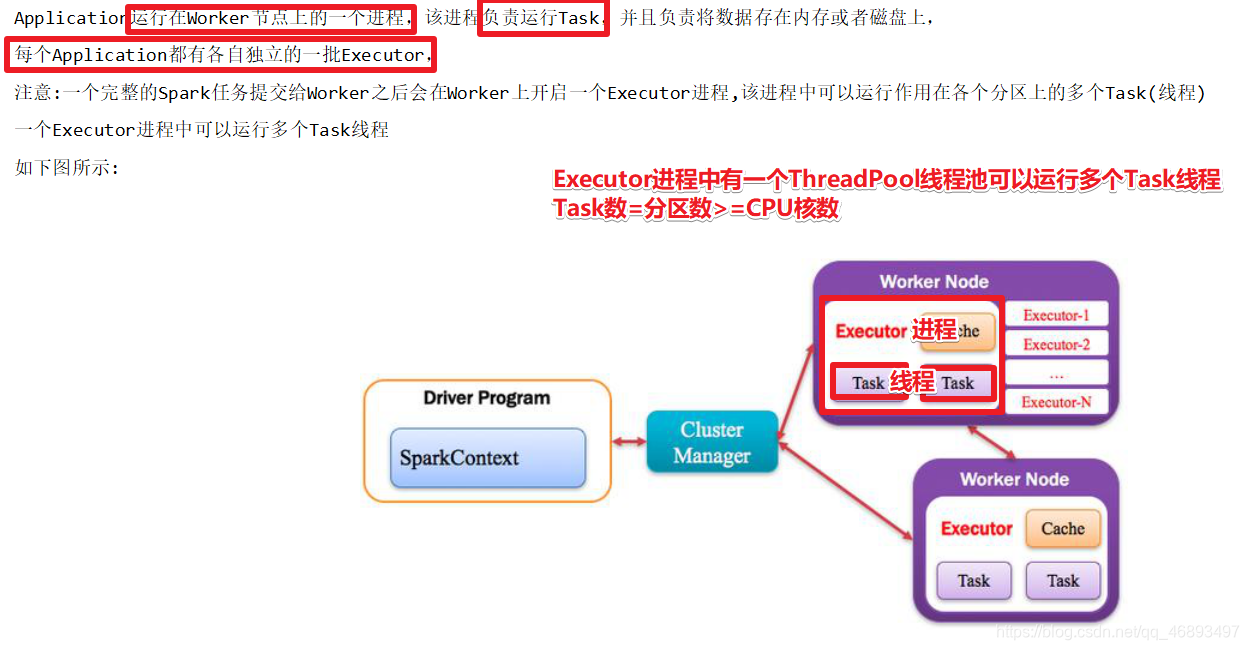
Executor:执行器/执行进程
- 每个Spark应用程序拥有各个独立的一批Executor
- 每个Executor中有可以运行多个Task由线程池进行调度执行这些Task
- 每个Task运行计算RDD的一个分区上的一系列操作
- Task数量=分区数量 >= CPU核数
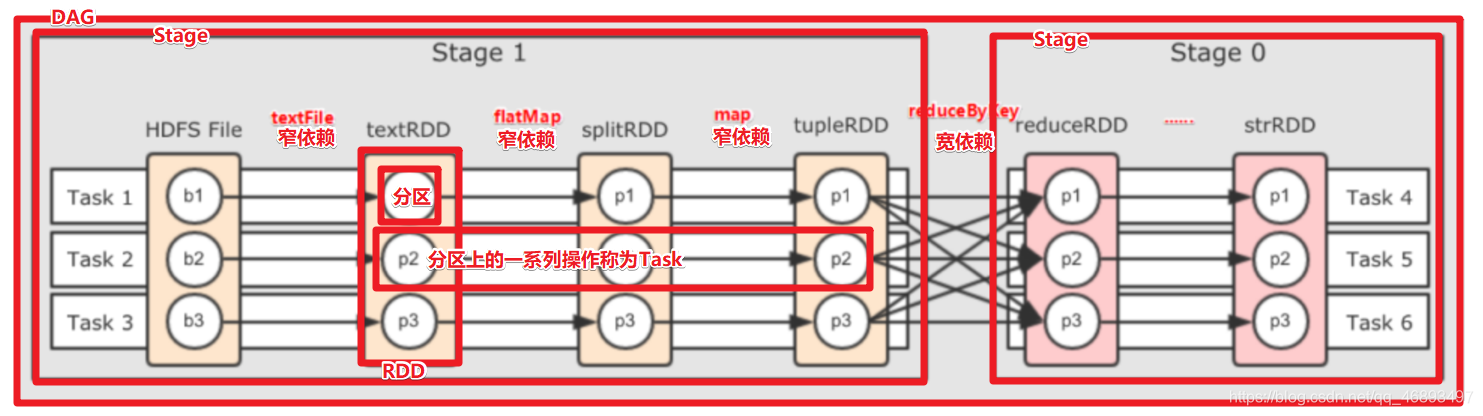
RDD:弹性分布式数据集
- RDD的五大属性:
- 分区列表 (
数据从哪来) - 最佳位置 (
在哪算) - 分区器/分区函数(默认hash,也可以自定义) (
怎么分区) - 计算函数(
怎么计算) - 依赖关系(
rdd的依赖关系是什么)
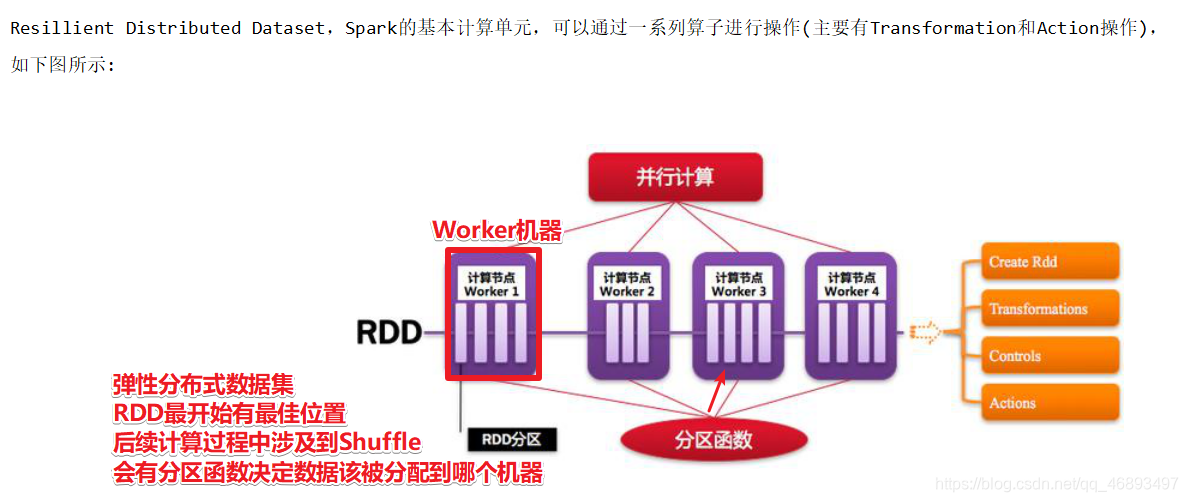
- 分区列表 (
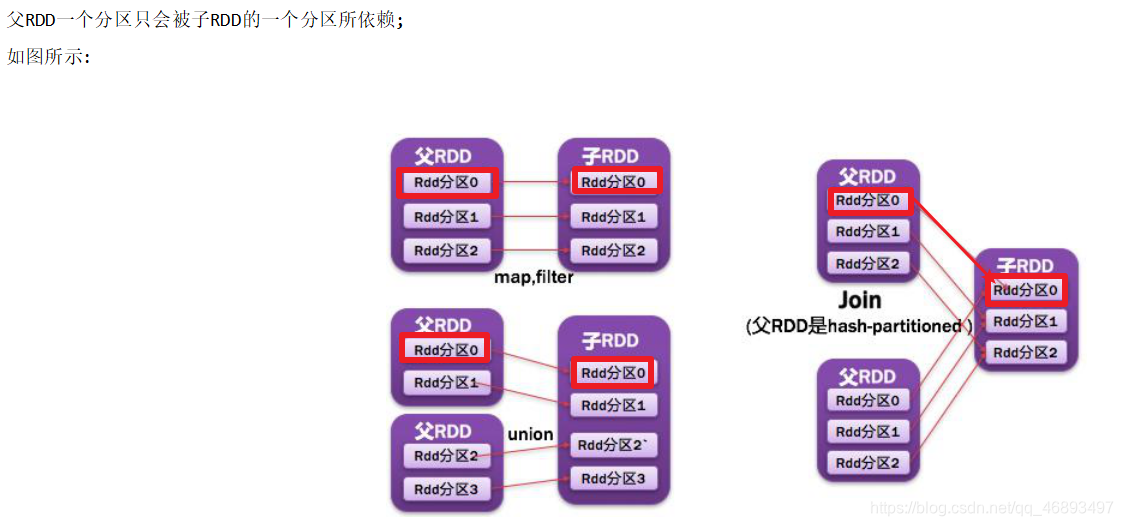
NarrowDependency窄依赖
- 如:map/flatmap/filter/union/join
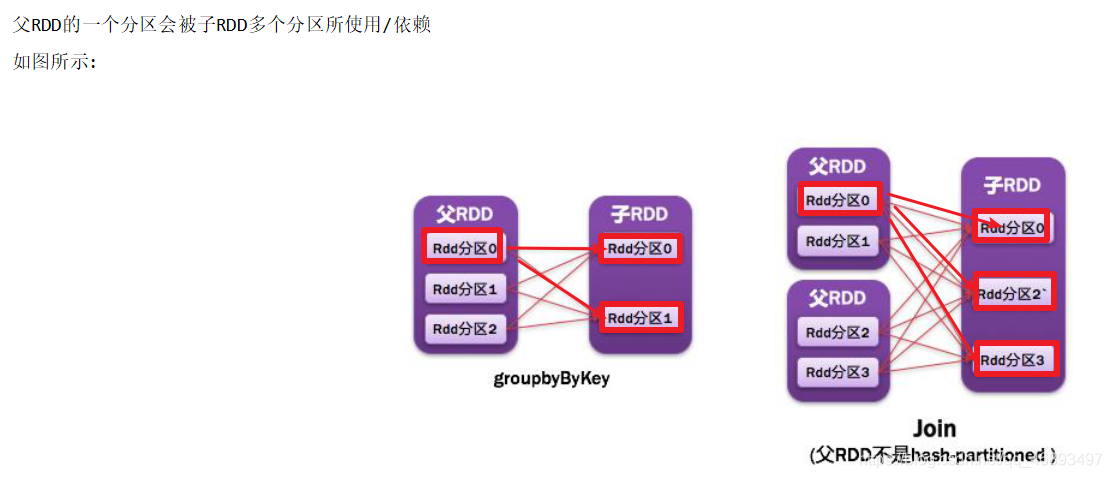
ShuffleDependency宽依赖
- 如: groupBy(xxx)/groupByKey/reduceByKey/join
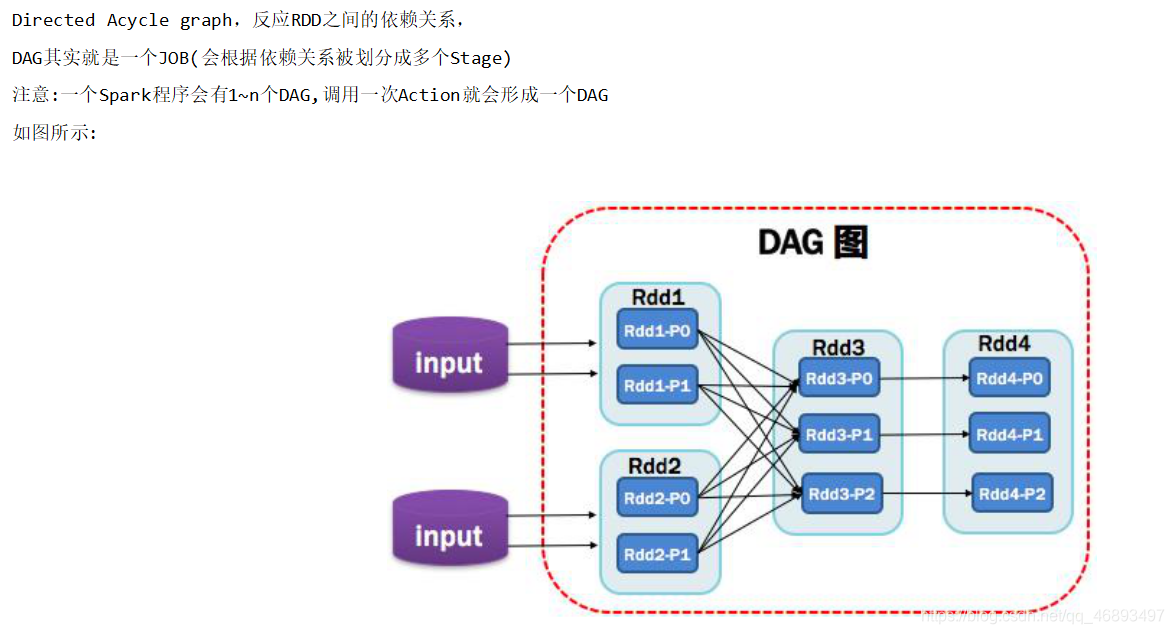
DAG有向无环图
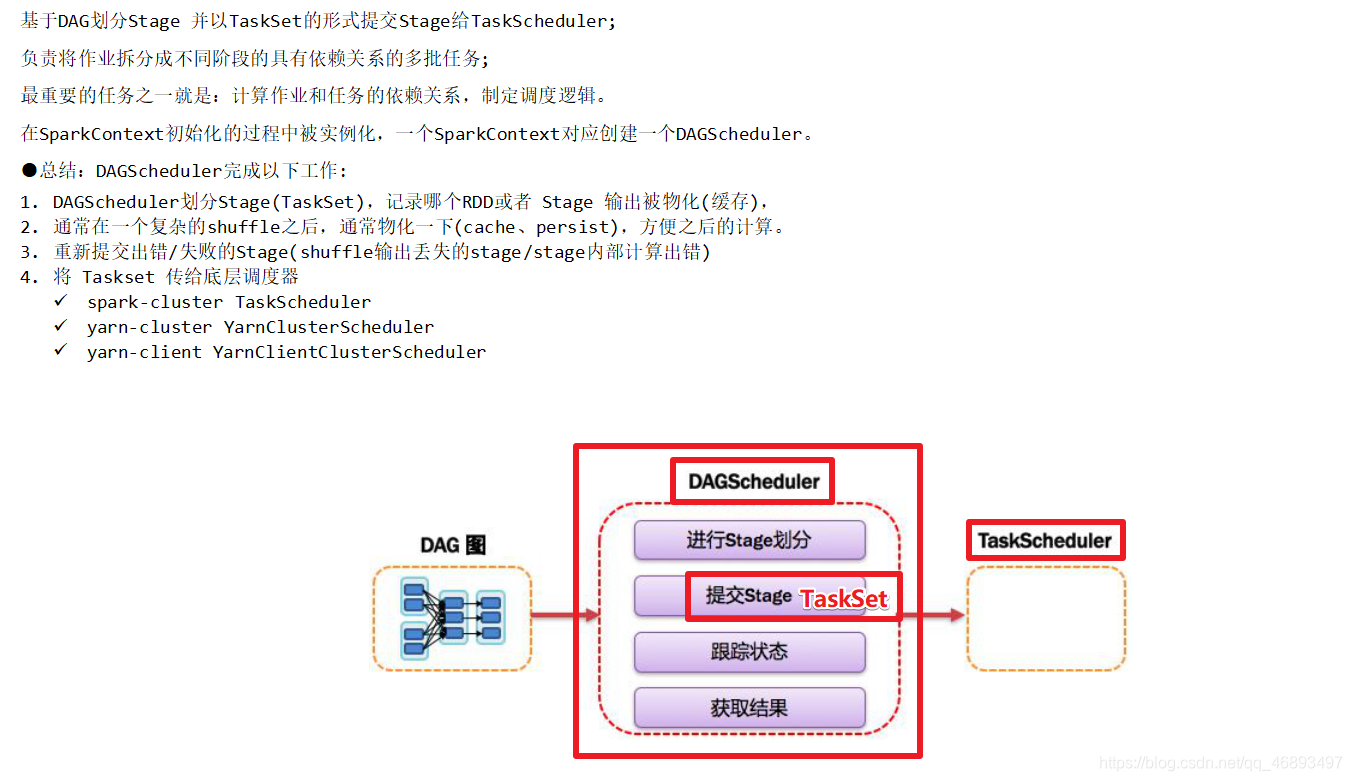
DAGScheduler[了解]
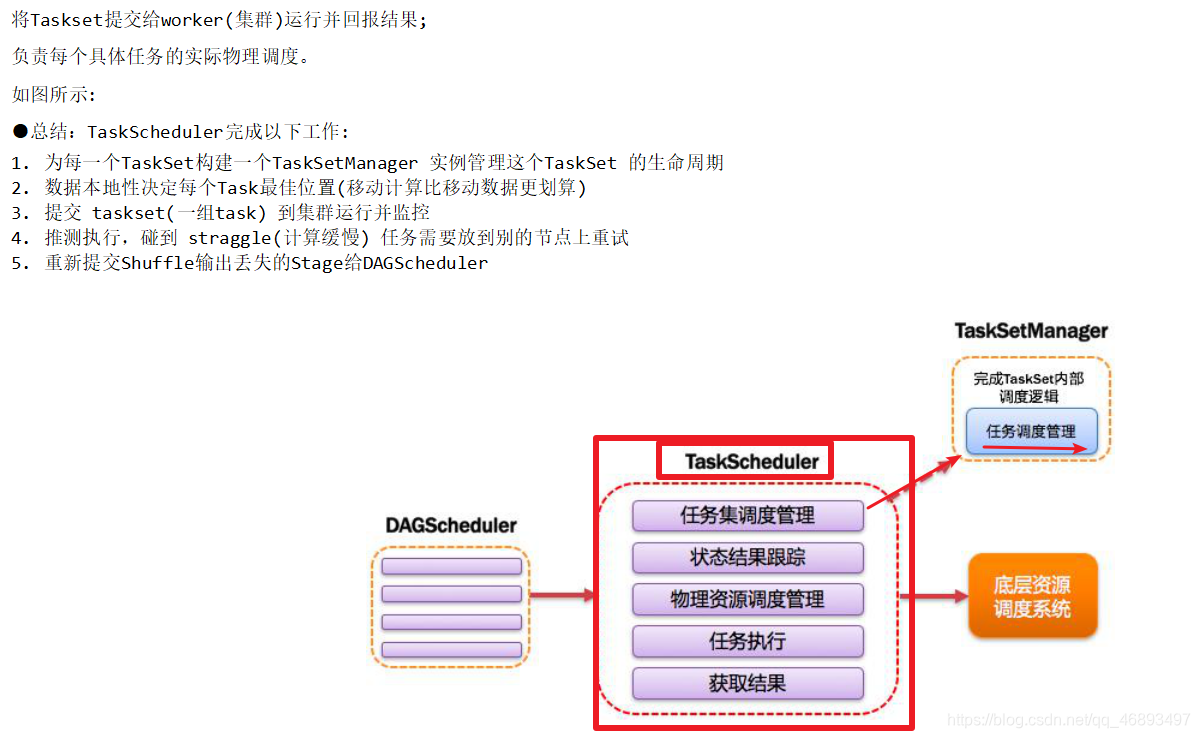
TaskScheduler[了解]
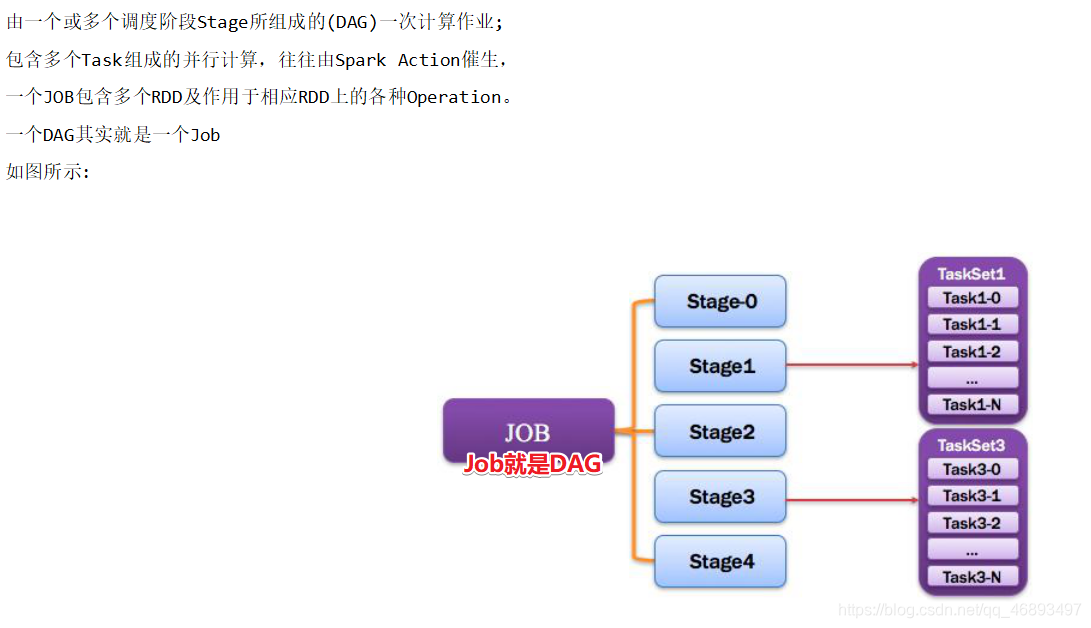
Job
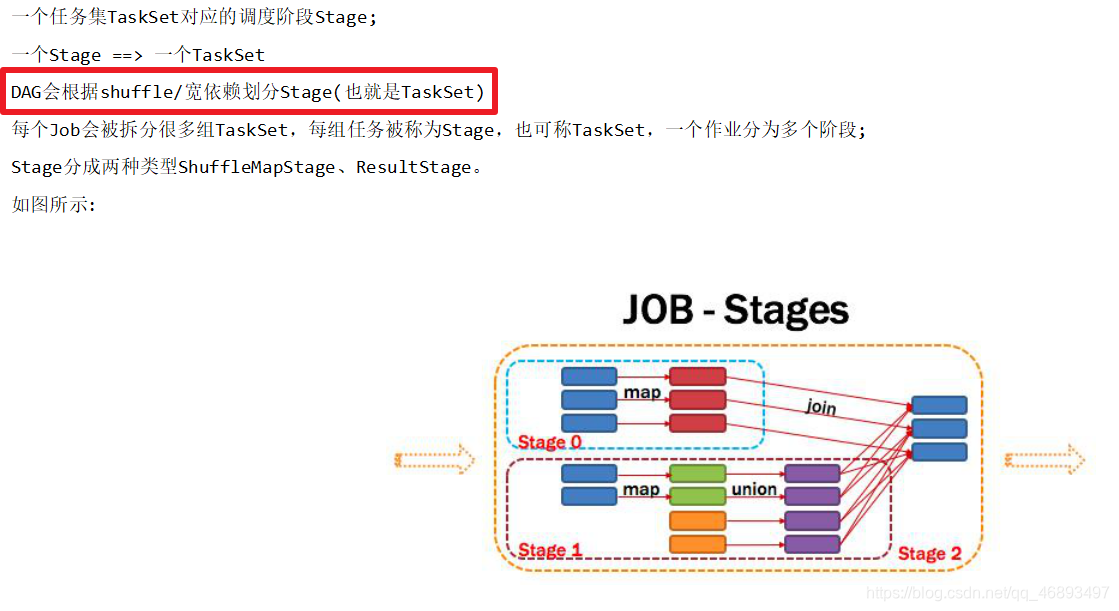
Stage
- DAGScheduler根据宽依赖划分Stage
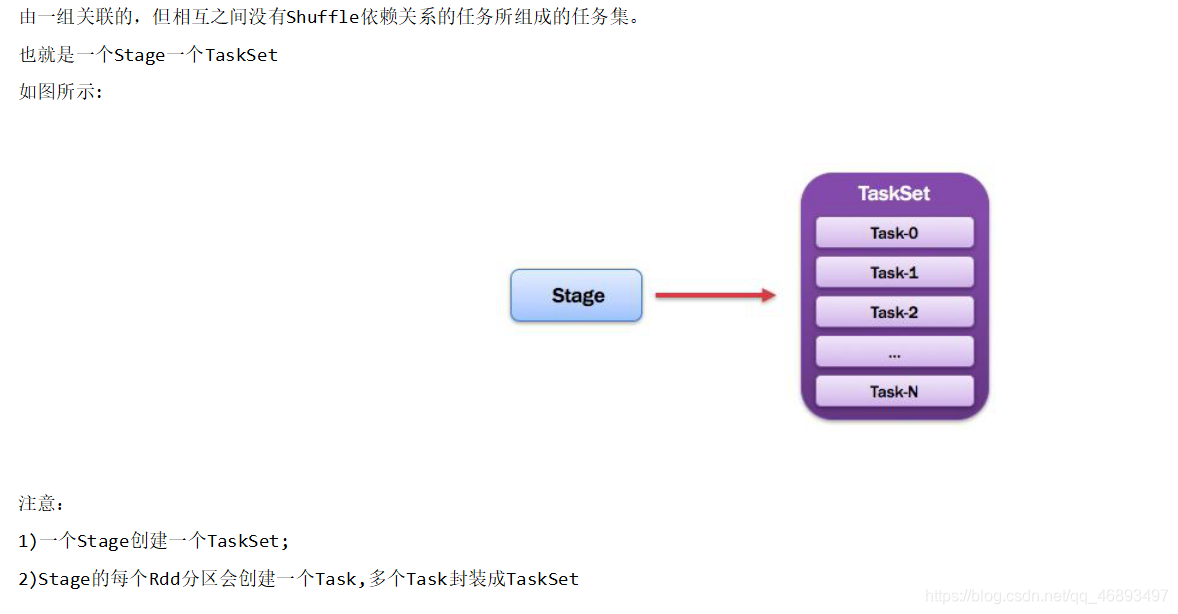
TaskSet
Task
- 同一个Stage中的同一个分区上的一系列操作
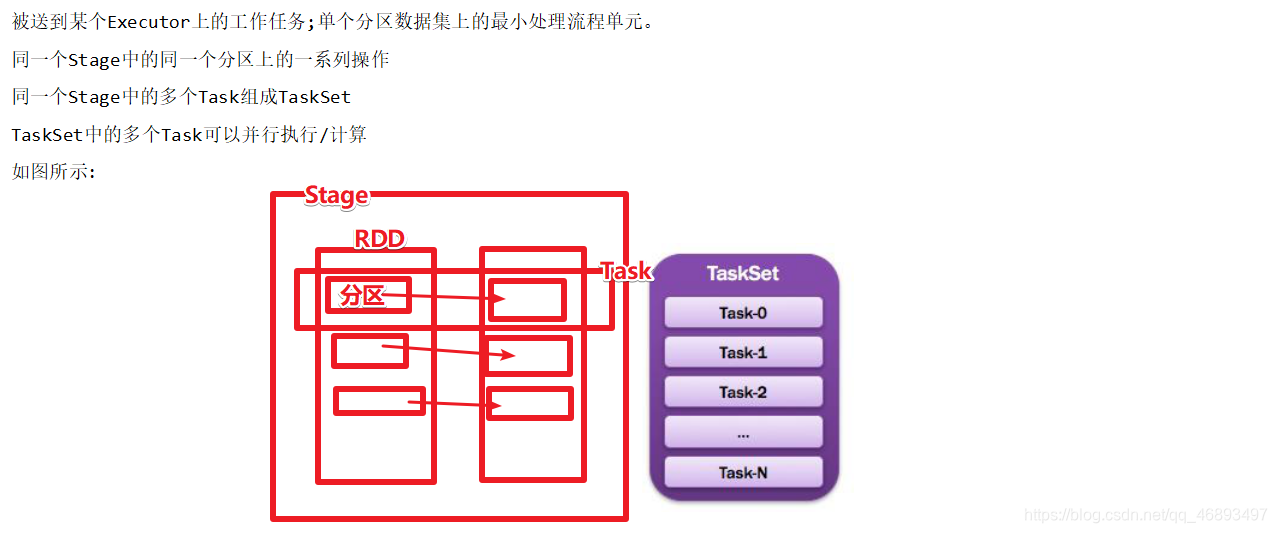
整体图示