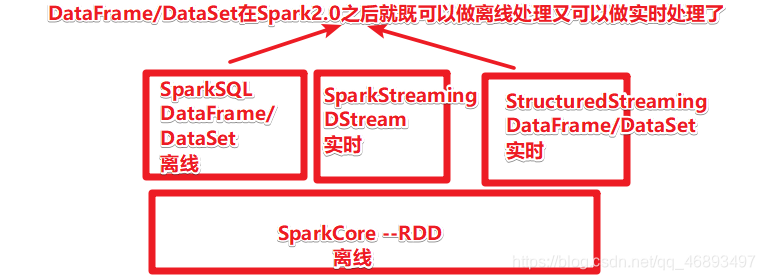
SparkCore
- 离线
- 环境:
SparkContext
- 简称sc
- new SparkConf().setAppName(“wc”).setMaster(“local[*]”) new SparkContext(conf)
数据抽象
RDD--弹性分布式数据集合--RDD里面不存数据,只记录5大属性
RDD五大主要特征
分区列表--数据集从哪来最佳位置列表--在哪计算合适分区器--如何分区计算函数--怎样的函数计算依赖关系--计算函数的RDD的依赖关系
RDD数据源
- 文本文件
- 对象文件
- 数据库
- 本地文件/hdfs文件
- sequence文件
创建RDD
外部存储系统的数据集创建(本地文件系统/hadoop支持的数据集)
val fileRDD: RDD[String] =sc.textFile(文件路径,分区数)
- 已有
RDD调用RDD方法(Transformations方法)返回一个新的RDD
val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
val intRDD1 =sc.parallelize(Array(1,2,3,4,5,6,7,8),分区数)
val intRDD2 = sc.makeRDD(List(1,2,3,4,5,6,7,8),分区数)
RDD算子分类
Transformations:转换操作,返回值为新的RDD,只会记录转换操作和依赖关系,不会立即执行
map(func)=>RDD
filter(func)=>RDD
- 每一个输入元素经过func计算,然后
返回 值为true的输入元素
flatMap(func)=>RDD
map之后压平,func返回一个序列,不是单一元素
mapPartitions(func)=>RDD
独立运行在每一个分区上,即func的函数类型必须是Iterator[T] => Iterator[U]
- mapPartitionsWithIndex(func)=>RDD
- 独立运行在某个分区上,func的函数类型必须是(Int, Interator[T]) => Iterator[U]
sample(withReplacement,function,seed)=>RDD --根据fraction指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed用于指定随机数生成器种子
union(otherDataset)=>RDD
- intersection(otherDataset)=>RDD
distinct([numTasks])=>RDD
keys或values
mapVaules
- groupByKey([numTasks])=>RDD
- (k,v)类型的RDD调用,返回(K,Iterator[V])的RDD
- reduceByKey(func,[numTasks])
- (k,v)类型的RDD调用,使用指定的reduce函数,将相同的key的值进行聚合
- aggregateByKey(zeroValue)(seqOp, combOp, [numTasks])
- sortByKey([ascending], [numTasks])
- 在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD
sortBy(func,[ascending], [numTasks])
- 类似sortByKey,但更灵活,默认ture升序,字典排序可以x=>x+""
- join(otherDataset, [numTasks])
- 在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD
- leftOuterJoin
- RightOuterJoin
cache/persist
- 缓存/持久化,适合该RDD后面经常被用到,默认MEMORY_ONLY,将RDD以非序列化方式存储在JVM中,若内存不够,则某些分区不会缓存会重新计算
checkpoint
- 设置检查点,在sc中设置检查点目录,调用后将结果存入该目录
cogroup(otherDataset, [numTasks]) --在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable,Iterable))类型的RDD
- cartesian(otherDataset)
- pipe(command, [envVars])
coalesce(numPartitions)
- 重新分区,默认只能减少分区(底层shuffle=false),注意:重分区的是新生成的RDD,原RDD不变
repartition(numPartitions)
- 重新分区,
底层调用coalesce方法(传参shuffle=true),注意:重分区的是新生成的RDD,原RDD不变,适合提高并行度或者合并小文件
Actions:动作操作,无返回值或返回值不是RDD(例collect/saveAsTextFile)
reduce(func)
- 注意:区分
reduceByKey(为transformation算子)的算子分类
collect()
- 以数组形式返回数据集的所有元素,适合小数据量,注意:只计算外层集合
- collectAsMap()
count()
first()
take(n)
top(n)
- 将数据拉回Driver进行排序再取前TopN(最大的前n个),不适合大数据量
- takeOrdered(n,[ordering])
- saveAsTextFile(path)
- 将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本
- saveAsSequenceFile(path)
- 将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。
- saveAsObjectFile(path)
- 将数据集的元素,以 Java 序列化的方式保存到指定的目录下
- countByKey()
- 针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。
foreach(func)
- 在数据集的每一个元素上,运行函数func进行更新。
foreachPartition(func)
- 在数据集的每一个分区上,运行函数func,例如保存数据到数据库,明显比foreach要好很多,减少连接次数
特别提出来:统计操作
count
- mean
- sum
- 求和,比如求平均,可以很方便的先groupByKey,然后mapValues(v=>{v.sum/v.size})
max
min
- variance
- sampleVariance
- stdev
- sampleStdev
- stats
RDD宽窄依赖
宽依赖
父RDD的一个分区会被子RDD的多个分区所依赖,与划分Stage阶段有关
窄依赖
父RDD的一个分区只会被子RDD的一个分区所依赖,可以并行计算`
- 本质就是有没有shuffle(因为它会涉及到数据交互跨网络传输)
SparkSQL
- 离线
- 环境:
SparkSession
- 简称spark
- SparkSession.builder.appName(“wc”).master(“local[*]”).getOrCreate(),可以.sparkContext获取sc
数据交互
- 普通文本
- json
- parquet
- csv
- MySQL
数据抽象
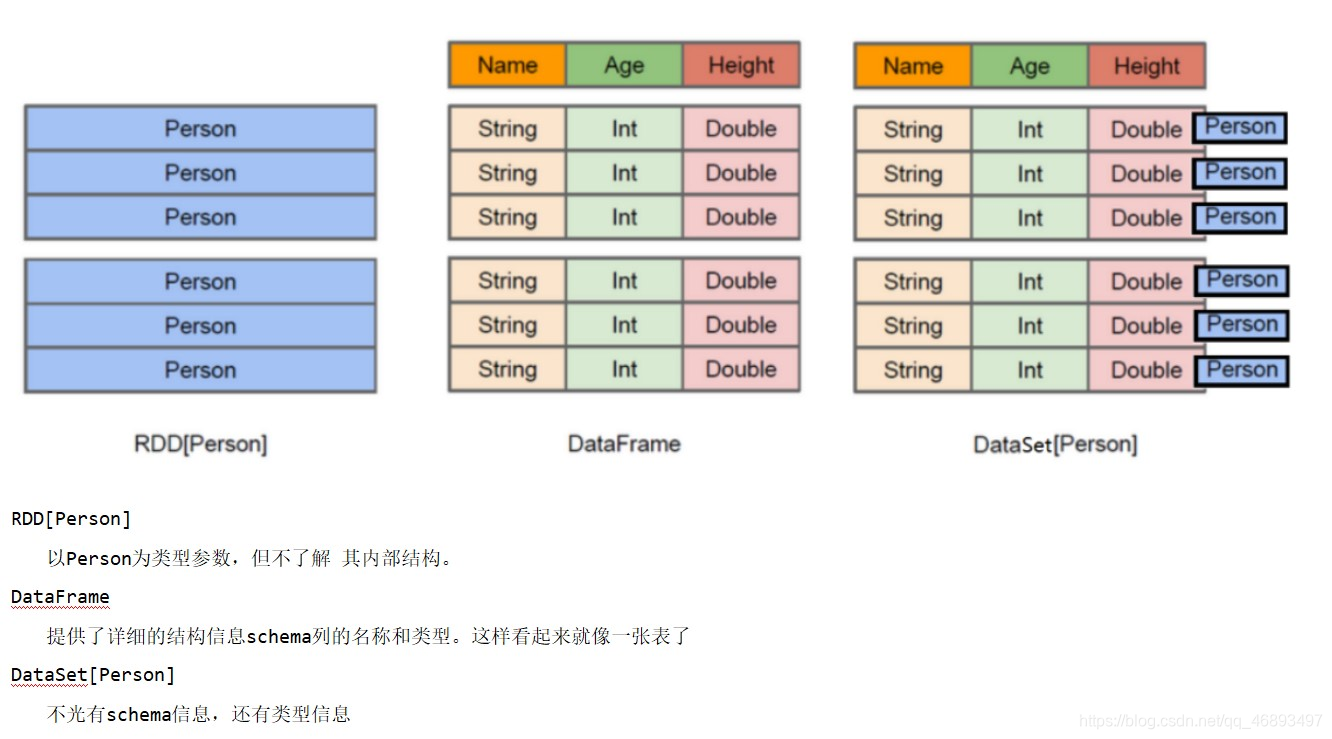
DataFrame
DataFrame = RDD - 泛型 + Schema(约束) + SQL操作 + 优化- 生成
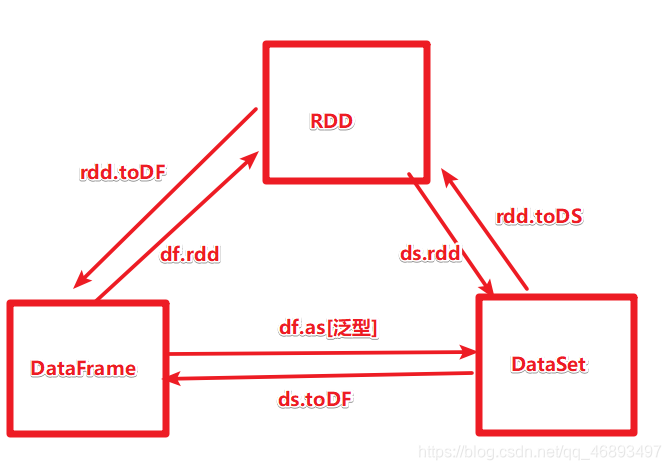
rdd.toDF/ds.todf
spark.read.text("文本路径")
spark.read.json("文本路径")
spark.read.parquet("文本路径")
show()
Dataset
DataSet = DataFrame + 泛型DataSet = RDD + Schema(约束) + SQL操作 + 优化- 生成
rdd.tods/df.as[泛型]
spark.read.textFile("文本路径")
....
show()
- 底层都是RDD的封装,可以理解成
分布式的表,所以要转换的话需要考虑加Schema或者泛型
怎么用
- DSL
- 领域特定查询语言,和SparkCore的API基本相同
- SQL
- 结果化查询语言,先.createOrReplaceTempView(“表名”),在.sql(“sql语句”),在.show()展示
自定义函数
- UDF
- DSL风格是spark.udf.register(“注册函数的名称”,函数)
- SQL风格是functions.udf(函数)
- UDAF
- UDTF
SparkStreaming
- 实时
- 环境:StreamingContext
- new StreamingContext(sc,Seconds(5)) //指定微批处理的划分间隔
数据抽象
- DStream(Discretized Stream,离散数据流)
本质是一系列时间上连续的RDD(微批处理)
API分类
Transformations
无状态转换:每个批次的处理不依赖之前批次map(func)
- 对DStream中的各个元素进行func函数操作,然后返回一个新的DStream
flatMap(func)
- 与map方法类似,只不过各个输入项可以被输出为零个或多个输出项
filter(func)
- 过滤出所有函数func返回值为true的DStream元素并返回一个新的DStream
union(otherStream)
- 将源DStream和输入参数为otherDStream的元素合并,并返回一个新的DStream.
reduceByKey(func, [numTasks])
- 利用func函数对源DStream中的key进行聚合操作,然后返回新的(K,V)对构成的DStream
join(otherStream, [numTasks])
- 输入为(K,V)、(K,W)类型的DStream,返回一个新的(K,(V,W)类型的DStream
- transform(func)
- 过RDD-to-RDD函数作用于DStream中的各个RDD,可以是任意的操作,从而返回一个新的RDD
有状态转换:当前批次的处理需要使用之前批次的数据或者中间结果。
UpdateStateByKey(func)
reduceByKeyAndWindow(方法,窗口长度,滑动间隔)
Output/Action
- print() --打印到控制台
- saveAsTextFiles(prefix, [suffix])
- 保存流的内容为文本文件,文件名为"prefix-TIME_IN_MS[.suffix]".
- saveAsObjectFiles(prefix,[suffix])
- 保存流的内容为SequenceFile,文件名为 “prefix-TIME_IN_MS[.suffix]”.
- saveAsHadoopFiles(prefix,[suffix])
- 保存流的内容为hadoop文件,文件名为"prefix-TIME_IN_MS[.suffix]".
- foreachRDD(func)
StructuredStreaming
- 实时
- 环境:SparkSession
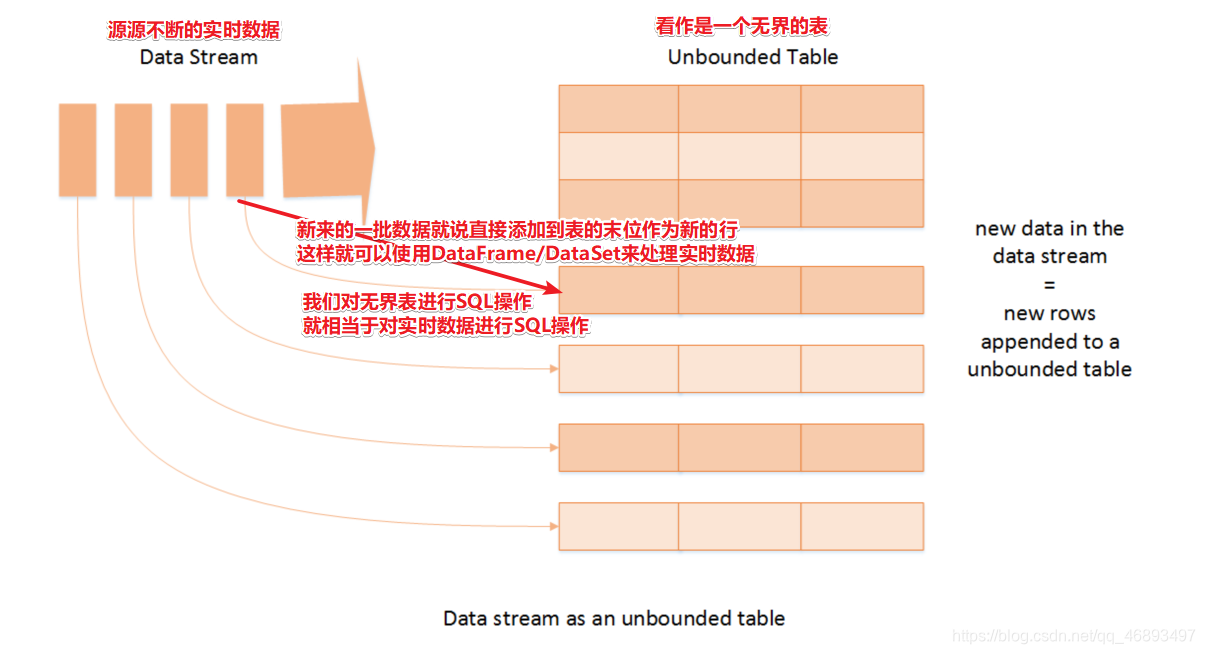
- 因为数据抽象还是DataFrame/Dataset,调用spark.readStream做流处理
数据抽象
- DataFrame/Dataset
底层原理是一个无界表- 图解