在线教育TopN讲师统计-★★★★★
- 数据
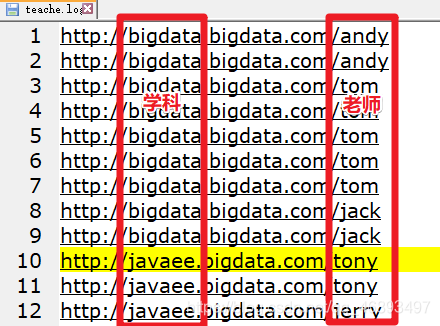
- teache.log
- 每一行数据表示该学科的该老师被学生点击访问过
需求
- 1.统计所有学科中最受欢迎的老师的TopN排行榜–对所有老师做WordCount即可
- 2.统计每个学科最受欢迎的老师的TopN排行榜–按照学科进行分组,再组内排序
准备工作-字符串切割测试
package cn.hanjiaxiaozhi.exercise
/**
* Author hanjiaxiaozhi
* Date 2020/7/29 14:30
* Desc
*/
object URLSplitTest {
def main(args: Array[String]): Unit = {
val url = "http://javaee.bigdata.com/tony"
/*val arr: Array[String] = url.split("[/]")
println(arr.toBuffer)//ArrayBuffer(http:, , javaee.bigdata.com, tony)*/
/*val arr: Array[String] = url.split("[.]")
println(arr.toBuffer)//ArrayBuffer(http://javaee, bigdata, com/tony)*/
val arr: Array[String] = url.split("[/]") //ArrayBuffer(http:, , javaee.bigdata.com, tony)
val arr2: Array[String] = arr(2).split("[.]")//ArrayBuffer(javaee,bigdata,com)
val subject: String = arr2(0)
val teacher: String = arr(3)
println(subject,teacher)
val index: Int = url.lastIndexOf("/")
println(url.substring(index+1))
}
}
代码实现-1-所有学科老师TopN-RDD
- 实现:直接spark取出老师的数据,映射成(老师,1),分组聚合,排序
package cn.hanjiaxiaozhi.exercise
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
/**
* Author hanjiaxiaozhi
* Date 2020/7/29 14:24
* Desc 在线教育TopN讲师统计
* 1.统计所有学科中最受欢迎的老师的TopN排行榜--对所有老师做WordCount即可
* 代码实现-1-所有学科老师TopN-RDD
*/
object OnlineEduAnalysis {
def main(args: Array[String]): Unit = {
//1.准备环境-直接获取SparkSession,然后通过SparkSession可以获取SparkContext,这样就可以统一RDD和DataFrame/DataSet的环境
val spark: SparkSession = SparkSession.builder().appName("OnlineEduAnalysis").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.加载数据
val logFileRDD: RDD[String] = sc.textFile("file:///D:\\data\\spark\\teache.log")
//3.处理数据-取出日志中的老师
/*
val url = "http://javaee.bigdata.com/tony"
val arr: Array[String] = url.split("[/]") //注意:按照/切割会有4个元素,老师是索引为3的元素
println(arr.toBuffer)//ArrayBuffer(http:, , javaee.bigdata.com, tony)
*/
val teacherRDD: RDD[String] = logFileRDD.map(url => {
val arr: Array[String] = url.split("[/]")
arr(arr.length-1)
//url.split("[/]")(3)
})
//4.统计分析
val teacherAndOne: RDD[(String, Int)] = teacherRDD.map((_,1))//每个老师记为1
val teacherAndCount: RDD[(String, Int)] = teacherAndOne.reduceByKey(_+_)//分组+聚合
val result: RDD[(String, Int)] = teacherAndCount.sortBy(_._2,false) //排序
//5.输出结果
result.take(5).foreach(println)
/*
(tom,15)
(jerry,9)
(tony,6)
(jack,6)
(lucy,4)
*/
}
}
代码实现-2-各个学科老师TopN-RDD
package cn.hanjiaxiaozhi.exercise
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
/**
* Author hanjiaxiaozhi
* Date 2020/7/29 14:24
* Desc 在线教育TopN讲师统计
* 2.统计每个学科最受欢迎的老师的TopN排行榜--按照学科进行分组,再组内排序
* 代码实现-2-各个学科老师TopN-RDD
*/
object OnlineEduAnalysis2 {
def main(args: Array[String]): Unit = {
//1.准备环境-直接获取SparkSession,然后通过SparkSession可以获取SparkContext,这样就可以统一RDD和DataFrame/DataSet的环境
val spark: SparkSession = SparkSession.builder().appName("OnlineEduAnalysis").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.加载数据
val logFileRDD: RDD[String] = sc.textFile("file:///D:\\data\\spark\\teache.log")
//3.处理数据-取出日志中的学科和老师并记为1: ((学科,老师),1)
/*
val url = "http://javaee.bigdata.com/tony"
val arr: Array[String] = url.split("[/]") //ArrayBuffer(http:, , javaee.bigdata.com, tony)
val arr2: Array[String] = arr(2).split("[.]")//ArrayBuffer(javaee,bigdata,com)
val subject: String = arr2(0)
val teacher: String = arr(3)
println(subject,teacher)
或者
val index: Int = url.lastIndexOf("/") //s.indexOf("x")是查询x在s中的索引 ,lastIndexOf倒着查
println(url.substring(index+1))//老师
*/
//subjectAndTeacherTupleAndOne: RDD[((学科, 老师), 1)]
val subjectAndTeacherTupleAndOne: RDD[((String, String), Int)] = logFileRDD.map(url => {
val arr: Array[String] = url.split("[/]") //ArrayBuffer(http:, , javaee.bigdata.com, tony)
val arr2: Array[String] = arr(2).split("[.]") //ArrayBuffer(javaee,bigdata,com)
val subject: String = arr2(0)
val teacher: String = arr(3)
((subject, teacher), 1)
})
//subjectAndTeacherTupleAndOne.take(5).foreach(println)
// ((bigdata,andy),1)
//目标统计每个学科最受欢迎的老师的TopN排行榜
//4.先按照(学科, 老师)分组聚合
val subjectAndTeacherTupleAndCount: RDD[((String, String), Int)] = subjectAndTeacherTupleAndOne.reduceByKey(_+_)
//subjectAndTeacherTupleAndCount.take(5).foreach(println)
/*
((bigdata,jack),6)
((bigdata,tom),15)
((php,lucy),4)
((javaee,tony),6)
...
*/
//目标统计每个学科最受欢迎的老师的TopN排行榜,如:
// ((bigdata,tom),15) 组内第1
// ((bigdata,jack),6) 组内第2
//也就是要组内排序
//5.按照学科进行分组
//groupedRDD: RDD[(学科, [((学科, 老师), 数量),((学科, 老师), 数量),((学科, 老师), 数量)...])]
//groupedRDD: RDD[(bigdata, [((bigdata, jack), 6),((bigdata, tom), 15),((bigdata, xx), xx)...])]
//groupedRDD: RDD[(javaee, [((javaee, tony), 6),((javaee, xx), xx)...])]
val groupedRDD: RDD[(String, Iterable[((String, String), Int)])] = subjectAndTeacherTupleAndCount.groupBy(_._1._1)
//6.将groupedRDD的数据中的同一个学科的数据按照数量进行排序
//然后得到排好序的各个学科的数据:[(学科, [(老师, 数量),(老师, 数量),(老师, 数量)...])]
//也就是要对groupedRDD的value进行排序并操作
//result: RDD[(学科, List[(老师, 数量)])]
val result: RDD[(String, List[(String, Int)])] = groupedRDD.mapValues(iter => {
//进来的iter是同一个学科的数据,也就说只需要对iter中每个元组的数量进行了排序,也就是对同一个学科内的数据进行了排序
//排好序的sortedList: List[((学科, 老师), 数量)]
val sortedList: List[((String, String), Int)] = iter.toList.sortBy(_._2).reverse.take(5) //取各个学科按照老师被访问数量逆序排序结果的前N个
//外面groupedRDD中的key已经有学科信息了,所以这里可以直接返回List[(老师, 数量)]
//List[(老师, 数量)]
val tuples: List[(String, Int)] = sortedList.map(t => {
(t._1._2, t._2)
})
tuples
})
//7.输出结果
//主要看各个学科内部的数据顺序是否ok
result.collect().foreach(println)
/*
(javaee,List((jerry,9), (tony,6)))
(php,List((lucy,4)))
(bigdata,List((tom,15), (jack,6), (andy,2)))
*/
}
}
代码实现-3-各个学科老师TopN-RDD-优化
- 实现:自定义分区器,实现自己想要的分区规则,在reduceByKey的时候就直接按照学科去分组并做之前的聚合,减少一次groupBykey宽依赖
package cn.hanjiaxiaozhi.exercise
import org.apache.spark.{
Partitioner, SparkContext}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
import scala.collection.mutable
/**
* Author hanjiaxiaozhi
* Date 2020/7/29 14:24
* Desc 在线教育TopN讲师统计
* 2.统计每个学科最受欢迎的老师的TopN排行榜--按照学科进行分组,再组内排序
* 代码实现-3-各个学科老师TopN-RDD-优化
*/
object OnlineEduAnalysis3 {
def main(args: Array[String]): Unit = {
//1.准备环境-直接获取SparkSession,然后通过SparkSession可以获取SparkContext,这样就可以统一RDD和DataFrame/DataSet的环境
val spark: SparkSession = SparkSession.builder().appName("OnlineEduAnalysis").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.加载数据
val logFileRDD: RDD[String] = sc.textFile("file:///D:\\data\\spark\\teache.log")
//3.处理数据-取出日志中的学科和老师并记为1: ((学科,老师),1)
/*
val url = "http://javaee.bigdata.com/tony"
val arr: Array[String] = url.split("[/]") //ArrayBuffer(http:, , javaee.bigdata.com, tony)
val arr2: Array[String] = arr(2).split("[.]")//ArrayBuffer(javaee,bigdata,com)
val subject: String = arr2(0)
val teacher: String = arr(3)
println(subject,teacher)
或者
val index: Int = url.lastIndexOf("/") //s.indexOf("x")是查询x在s中的索引 ,lastIndexOf倒着查
println(url.substring(index+1))//老师
*/
//subjectAndTeacherTupleAndOne: RDD[((学科, 老师), 1)]
val subjectAndTeacherTupleAndOne: RDD[((String, String), Int)] = logFileRDD.map(url => {
val arr: Array[String] = url.split("[/]") //ArrayBuffer(http:, , javaee.bigdata.com, tony)
val arr2: Array[String] = arr(2).split("[.]") //ArrayBuffer(javaee,bigdata,com)
val subject: String = arr2(0)
val teacher: String = arr(3)
((subject, teacher), 1)
})
//subjectAndTeacherTupleAndOne.take(5).foreach(println)
// ((bigdata,andy),1)
//目标统计每个学科最受欢迎的老师的TopN排行榜
/*
//4.先按照(学科, 老师)分组聚合--按照(学科,老师)进行分组再聚合--宽依赖
val subjectAndTeacherTupleAndCount: RDD[((String, String), Int)] = subjectAndTeacherTupleAndOne.reduceByKey(_+_)
//5.按照学科进行分组--按照学科进行分组--宽依赖
val groupedRDD: RDD[(String, Iterable[((String, String), Int)])] = subjectAndTeacherTupleAndCount.groupBy(_._1._1)
*/
//分析过程:重点!
//之前的第4和第5步需要按照指定的key进行分组都是宽依赖/shuffle依赖
//而我们之前学习过宽依赖/shuffle依赖需要跨网络传输,需要消耗性能,所以应该尽量避免/减少宽依赖/shuffle依赖
//问题1:该减少上面的哪一个操作呢?是reduceByKey还是groupBy?
//上面的操作中,reduceByKey默认是按照key(学科,老师)进行分组的,groupBy是按照指定的key学科进行分组的
//如果我们能统一下,在reduceByKey的时候就直接按照学科去分组并做之前的聚合的话,那么后面的groupBy就不需要了!
//所以:问题1的答案是:减少groupBy操作,保留reduceByKey
//问题2:如何减少?--如何让reduceByKey的时候就直接按照学科去分组?
//reduceByKey默认是按照key(学科,老师)的hash分区的,我们需要使用自定义分区器,
//让reduceByKey使用学科进行分区,将同一学科的数据分到同一个分区中去
//4先获取所有的学科,然后告诉分区器有哪些学科
val subjects: Array[String] = subjectAndTeacherTupleAndOne.map(_._1._1).distinct().collect()
//5创建一个可以根据学科进行分区的分区器
val partition = new SubjectPatitioner(subjects)
//6.然后将该分区器传递给reduceByKey,然后reduceByKey可以根据学科进行分区
val subjectAndTeacherTupleAndCount: RDD[((String, String), Int)] = subjectAndTeacherTupleAndOne.reduceByKey(partition,_+_)
//代码走到这里,就完成了reduceByKey按照key(学科,老师)进行聚合,按照自定义分区的规则,也就是按照学科进行分区
//也就是各个分区中的数据就是同一个学科的数据!
//subjectAndTeacherTupleAndCount.sortBy()
//7.直接对各个分区的数据进行排序,就是对各个学科的数据进行排序
//mapPartitions比map高
//类似
//foreachPartiton比foreach高
val result: RDD[((String, String), Int)] = subjectAndTeacherTupleAndCount.mapPartitions(iter => {
//当前这一次进来的iter中的数据就是当前分区的数据,也就是同一个学科的数据
//直接对每一次进来iter中的数据进行排序就是对每一个学科中的数据进行排序
val sortedList: List[((String, String), Int)] = iter.toList.sortBy(_._2).reverse.take(5)
sortedList.toIterator
//比如在这里可以返回[学科,[(老师,数量),(老师,数量),(老师,数量)]]
})
//主要看各个学科内部的数据顺序是否ok
result.collect().foreach(println)
/*
* ((javaee,jerry),9)
* ((javaee,tony),6)
* ((php,lucy),4)
* ((bigdata,tom),15)
* ((bigdata,jack),6)
* ((bigdata,andy),2)
*/
}
/**
* 自定义一个能够按照学科进行分区的分区器,能够根据key将相同学科的数据分到同一个分区中去
* 也就是相同的学科,返回相同的分区编号
* @param subjects
*/
class SubjectPatitioner(subjects: Array[String]) extends Partitioner {
//准备一个集合用来存放学科和分区编号的对应关系,也就哪个学科对应哪个分区编号
val subjectAndPartitionNumMap = mutable.Map[String,Int]()
var partitionNum:Int = 0
for(s<- subjects){
subjectAndPartitionNumMap.put(s,partitionNum)
partitionNum += 1
}
//返回分区数量有多少个
override def numPartitions: Int = subjects.length
//根据key返回分区编号
override def getPartition(key: Any): Int = {
val t: (String, String) = key.asInstanceOf[(String, String)]
val subject: String = t._1
subjectAndPartitionNumMap(subject)//根据key中的学科返回分区编号
}
}
}
代码实现-4-各个学科老师TopN-SparkSQL
package cn.hanjiaxiaozhi.exercise
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.{
DataFrame, SparkSession}
/**
* Author hanjiaxiaozhi
* Date 2020/7/29 14:24
* Desc 在线教育TopN讲师统计
* 2.统计每个学科最受欢迎的老师的TopN排行榜--按照学科进行分组,再组内排序
* 代码实现-4-各个学科老师TopN-SparkSQL
*/
object OnlineEduAnalysis4 {
def main(args: Array[String]): Unit = {
//1.准备环境-直接获取SparkSession,然后通过SparkSession可以获取SparkContext,这样就可以统一RDD和DataFrame/DataSet的环境
val spark: SparkSession = SparkSession.builder().appName("OnlineEduAnalysis").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
import spark.implicits._
//2.加载数据
val logFileRDD: RDD[String] = sc.textFile("file:///D:\\data\\spark\\teache.log")
//3.处理数据-取出日志中的学科和老师: (学科,老师)
//subjectAndTeacher: RDD[(学科, 老师)]
val subjectAndTeacher: RDD[(String, String)] = logFileRDD.map(url => {
val arr: Array[String] = url.split("[/]") //ArrayBuffer(http:, , javaee.bigdata.com, tony)
val arr2: Array[String] = arr(2).split("[.]") //ArrayBuffer(javaee,bigdata,com)
val subject: String = arr2(0)
val teacher: String = arr(3)
(subject, teacher)
})
//4.将RDD转为DF
val subjectAndTeacherDF: DataFrame = subjectAndTeacher.toDF("subject", "teacher")
subjectAndTeacherDF.show(10, false)
/*
* +-------+-------+
* |subject|teacher|
* +-------+-------+
* |bigdata|andy |
* |bigdata|andy |
* |bigdata|tom |
* |bigdata|tom |
* |bigdata|tom |
* .....
*/
//5.完成需求:
//需求-1.统计所有学科中最受欢迎的老师的TopN排行榜--对所有老师做WordCount即可
//注册表
subjectAndTeacherDF.createOrReplaceTempView("t_log")
//编写sql
val sql =
"""
|select subject,teacher,count(*) counts
|from t_log
|group by subject,teacher
|order by counts desc
|""".stripMargin
val allResultDF: DataFrame = spark.sql(sql)
allResultDF.show(false)
/*
* +-------+-------+------+
* |subject|teacher|counts|
* +-------+-------+------+
* |bigdata|tom |15 |
* |javaee |jerry |9 |
* |bigdata|jack |6 |
* |javaee |tony |6 |
* |php |lucy |4 |
* |bigdata|andy |2 |
* +-------+-------+------+
*/
//需求-2.统计每个学科最受欢迎的老师的TopN排行榜--按照学科进行分组,再组内排序
//======================SQL风格======================
//注册表
allResultDF.createOrReplaceTempView("t_allResultDF")
//编写sql
val sql2 =
"""
|select subject,teacher,counts,row_number() over(partition by subject order by counts desc) rn
|from t_allResultDF
|having rn < 3
|""".stripMargin //注意对row_number结果进行过滤得用having
spark.sql(sql2).show(false)
/*
* +-------+-------+------+---+
* |subject|teacher|counts|rn |
* +-------+-------+------+---+
* |javaee |jerry |9 |1 |
* |javaee |tony |6 |2 |
* |bigdata|tom |15 |1 |
* |bigdata|jack |6 |2 |
* |php |lucy |4 |1 |
* +-------+-------+------+---+
*/
//======================DSL风格======================
import org.apache.spark.sql.functions._
//要在原来的allResultDF的3列之后再加一列rn,应该使用withColumn
allResultDF.withColumn(
"rn", //列名
row_number().over(Window.partitionBy("subject").orderBy($"counts".desc)) //该列如何计算--通过row_number开窗函数
).filter($"rn" < 2).show(false)
/*
* +-------+-------+------+---+
* |subject|teacher|counts|rn |
* +-------+-------+------+---+
* |javaee |jerry |9 |1 |
* |bigdata|tom |15 |1 |
* |php |lucy |4 |1 |
* +-------+-------+------+---+
*/
}
}