文章目录
论文:Learning Convolutional Neural Networks for Graphs
作者:Mathias Niepert, Mohamed Ahmed, Konstantin Kutzkov
美国印第安纳州普渡大学统计系和计算机科学系
来源: ICML 2016
论文链接:
Arxiv: https://arxiv.org/abs/1605.05273
论文PPT:http://www.matlog.net/icml2016_slides.pdf
GitHub代码:https://github.com/seiya-kumada/patchy-san
GitHub上搜索Patchy-san可以找到由seiya-kumada提交的代码,代码虽然不是原作者公布,但是也可以参考
1 背景
核心思想:把graph转换成标准CNN可输入的样子,而不是GCN那样改CNN的结构去适应graph。
先看下CNN的卷积方式:
卷积计算分两步:

- a:确定感受野(红色节点是感受野的中心)
- b:将感受野按照空间位置从左到右,从上到下的顺序映射为一个和卷积核一样大小的vector,然后再进行向量的內积运算
2 PATCHY-SAN模型
Node Sequence Selection - 根据节点排序选择要进行卷积的节点
首先对于输入的一个Graph,首先从图结构中选择固定个数(w)的nodes。w相当于图像的宽度。选出的node就是我们将要做卷积操作的小矩形的中心node。换句话说,就是w的个数也是我们针对这个图结果做的卷积操作的个数。如下图所示,w=6,意味着我们需要从图结果中选择6个node做卷积操作:
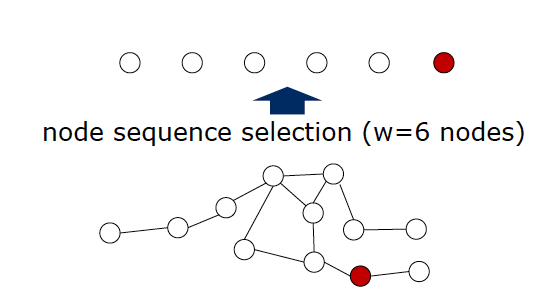
那么具体如何进行nodes的选择?实际上,paper当中说根据graph当中的node的排序label进行选择,但是本文并没有对如何排序有更多的介绍。主要采取的方法是:centrality,也就是中心化的方法,越处于中心位置的点越重要。在图论和网络分析中,中心性(Centrality)是判断网络中节点重要性/影响力的指标。具体的,有点度中心性(degree centrality)、中介中心性(betweenness centrality)、接近中心性(closeness centrality)、特征向量中心性(eigenvector centrality)。
在图论和网络分析中,中心性(Centrality)是判断网络中节点重要性/影响力的指标:
- 点度中心性(degree centrality):在无向网络中,可以用一个节点的度数来衡量中心性。这一指标背后的假设是:重要的节点就是拥有更多的连接节点。例如,在一个社交网络中,点度中心性网络中的“名人”,相当于一个人的好友数或者粉丝数,那么这个值越多,说明社会关系越多,影响力就越强。
- 中介中心性(betweenness centrality):计算网络中任意两个节点的所有最短路径,如果这些最短路径中有很多条都经过了某个节点,那么就认为这个节点的Betweenness Centrality高。例如,在一个计算机网络图中,交换机或者路由器就是中介中性较大的节点。
- 接近中心性(closeness centrality):如果节点到图中其他节点的最短距离之和越小,那么它的接近中心性就越高。相比中介中心性,接近中心性更接近几何上的中心位置。点度中心性仅仅利用了网络的局部特征,即节点的连接数有多少,但一个人连接数多,并不代表他/她处于网络的核心位置。接近中心性和中介中心性一样,都利用了整个网络的特征,即一个节点在整个结构中所处的位置。接近中心性高的节点一般扮演的是八婆的角色(gossiper)。他们不一定是名人,但是乐于在不同的人群之间传递消息。
- 特征向量中心性(eigenvector centrality):在特征向量中心度算法中,其认为与具有高得分的节点相连接比与具有低得分的节点相连接所得的贡献更大。
当然,这只是一种node的排序和选择的方法,其存在的问题也是非常明显的。Paper并没有在这次的工作当中做详细的说明。
Neighborhood Assembly - 找到Node的领域,确定感受野
第二步是Neighborhood Assembly,即对于选出来的每个节点逐个构建邻域,方法很简单就是BFS,先搜索直接相邻的一级邻域,再搜索下一级邻域,直到找到超过k个邻居,然后使用这超过k个的邻居构成下一步图规范化的候选集。
Graph Normalization - 图规范化过程
假设上一步Neighborhood Assemble过程当中一个node得到一个邻域nodes总共有N个。那么N的个数可能和k不相等的。因此,normalize的过程就是要对他们打上排序标签进行选择,并且按照该顺序映射到向量当中。
如果这个node的邻域nodes的个数不足的话,直接全部选上,不够补上哑节点(dummy nodes),但还是需要排序;如果数目N超过则需要按着排序截断后面的节点。如下图所示,表示从选node到求解出receptive filed的整个过程。Normalize进行排序之后就能够映射到一个vector当中了。因此,这一步最重要的是对nodes进行排序。
上图表示对任意一个node求解它的receptive filed的过程。这里的卷积核的大小为4,因此最终要选出来4个node,包括这个node本身。因此,需要给这些nodes打上标签(labeling)。当然存在很多的方式,那么怎样的打标签方式才是最好的呢?文中采用的是The Weisfeiler-Lehman algorithm/betweenness centrality来对节点打标签。如上图所示,其实从这7个nodes当中选出4个nodes会形成一个含有4个nodes的graph的集合。作者认为:在某种标签下,随机从集合当中选择两个图,计算他们在vector空间的图的距离和在graph空间图的距离的差异的期望,如果这个期望越小那么就表明这个标签越好!具体的表示如下:
得到最好的标签之后,就能够按着顺序将node映射到一个有序的vector当中,也就得到了这个node的receptive field。
Convolutional Architecture - 卷积网络结构
文章使用的是一个2层的卷积神经网络,将输入转化为一个向量vector之后便可以用来进行卷积操作了。具体的操作如下图所示。
首先最底层的灰色块为网络的输入,每一个块表示的是一个node的感知野(receptive field)区域,也是前面求解得到的4个nodes。其中an表示的是每一个node的数据中的一个维度(node如果是彩色图像那就是3维;如果是文字,可能是一个词向量……这里表明数据的维度为n)。粉色的表示卷积核,核的大小为4,但是宽度要和数据维度一样。因此,和每一个node卷季后得到一个值。卷积的步长(stride)为4,表明每一次卷积1个node,stride=4下一次刚好跨到下一个node。(备注:paper 中Figure1 当中,(a)当中的stride=1,但是转化为(b)当中的结构后stride=9)。卷积核的个数为M,表明卷积后得到的特征图的通道数为M,因此最终得到的结果为V1……VM,也就是图的特征表示。有了它便可以进行分类或者是回归的任务了。
CNN的卷积核通道数 = 卷积输入层的通道数
CNN的卷积输出层通道数(深度)= 卷积核的个数
3 实验
数据集和实验结果:
在社交网络数据集上的实验结果:
4 小结
优点:
- 不需要设计图核
- 在多个数据集上优于图核方法(速度和精度)
- 可以整合节点和边的特征(离散和连续)
- 支持可视化
缺点:
- 在较小的数据集上容易过度拟合
- 从设计图核转向调整超参数
- 图的规范化不是学习的一部分