背景
该篇文章从gossip协议中获得启发,旨在设计一个去中心化的联邦训练算法
Gossip协议
概要
gossip协议又称epidemic协议,是基于流行病传播方式的节点或者进程之间交换信息的协议,在分布式系统中被广泛使用,经常被用来确保网络中所有节点的数据一样。我们可以利用gossip协议的这个特性来完成传统FL中的upload和download过程,达到取代中央服务器的作用
协议执行过程
gossp过程由种子节点发起,当一个种子节点有状态需要更新到网络中的其他节点时,它会随机的选择周围几个节点散播消息,收到消息的节点也会重复该过程,直至最终网络中所有的节点都收到了消息。这个过程可能需要一定的时间,由于不能保证某个时刻所有节点都收到消息,但是理论上最终所有节点都会收到消息,因此它是一个最终一致性协议
具体过程:
- 种子节点周期性地散播消息
- 被感染节点随机选择N个邻接节点散播消息【假定fan-out(扇出)设置为6,每次最多往6个节点散播】
- 节点只接收消息不反馈结果
- 每次散播消息都选择尚未发送过的节点进行散播
- 收到消息的节点不再往发送节点散播:A -> B,那么B进行散播的时候,不再发给 A
协议的通信方式
节点之间的通信方式主要有三种:
- Push:发起信息交换的节点 A 随机选择联系节点 B,并向其发送自己的信息,节点 B 在收到信息后更新比自己新的数据
- Pull:发起信息交换的节点 A 随机选择联系节点 B,并从对方获取信息
- Push&Pull:发起信息交换的节点 A 向选择的节点 B 发送信息,同时从对方获取数据,用于更新自己的本地数据
Segmented Gossip Aggregation
如果将传统gossip照搬到FL中来,每次两个节点之间将模型作为消息传播会造成严重的通信瓶颈。为了解决这个问题,作者对节点上的模型进行分段,然后每次每两个节点之间传输模型的时候只传输其中的一部分模型,这样子可以将通信开销分摊到多个通信链路上
Segmented Pulling
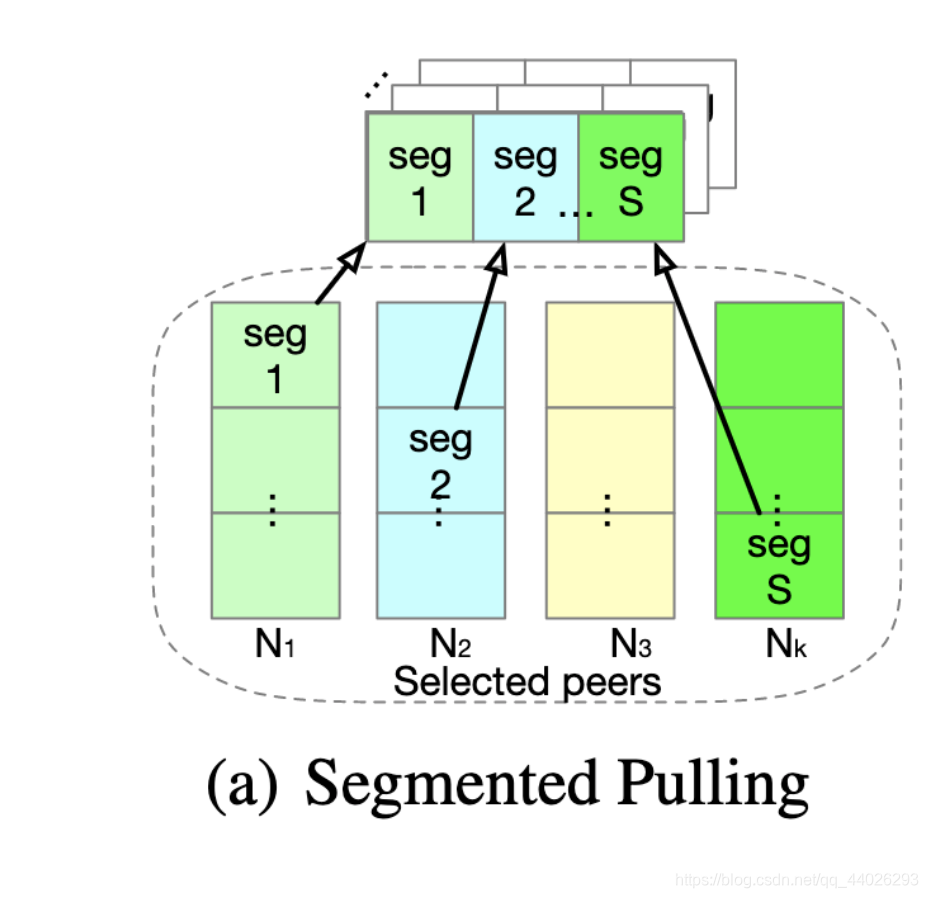
假设模型被分段为 S S S个片段:
W = ( W [ 1 ] , W [ 2 ] , . . . , W [ S ] ) W = (W[1],W[2],...,W[S]) W=(W[1],W[2],...,W[S])
对于每一个片段 l l l,一个节点在进行pull操作的时候会选择一个peer节点 j l j_l jl然后拉取其片段 l l l对应的模型片段 W j l [ l ] W_{j_l}[l] Wjl[l],当一个节点拉取了 S S S个模型片段的时候,这些片段组合成的模型可以写作:
W ′ = ( W j 1 [ 1 ] , W j 2 [ 2 ] , . . . , W j l [ S ] ) W' = (W_{j_1}[1],W_{j_2}[2],...,W_{j_l}[S]) W′=(Wj1[1],Wj2[2],...,Wjl[S])
如下图所示:
Model Replica
一个节点可以对随机选取 R R R个peer节点发去pull请求,总共发起 R × S R\times S R×S个pull请求,然后对这些片段进行模型的聚合,如下图所示:
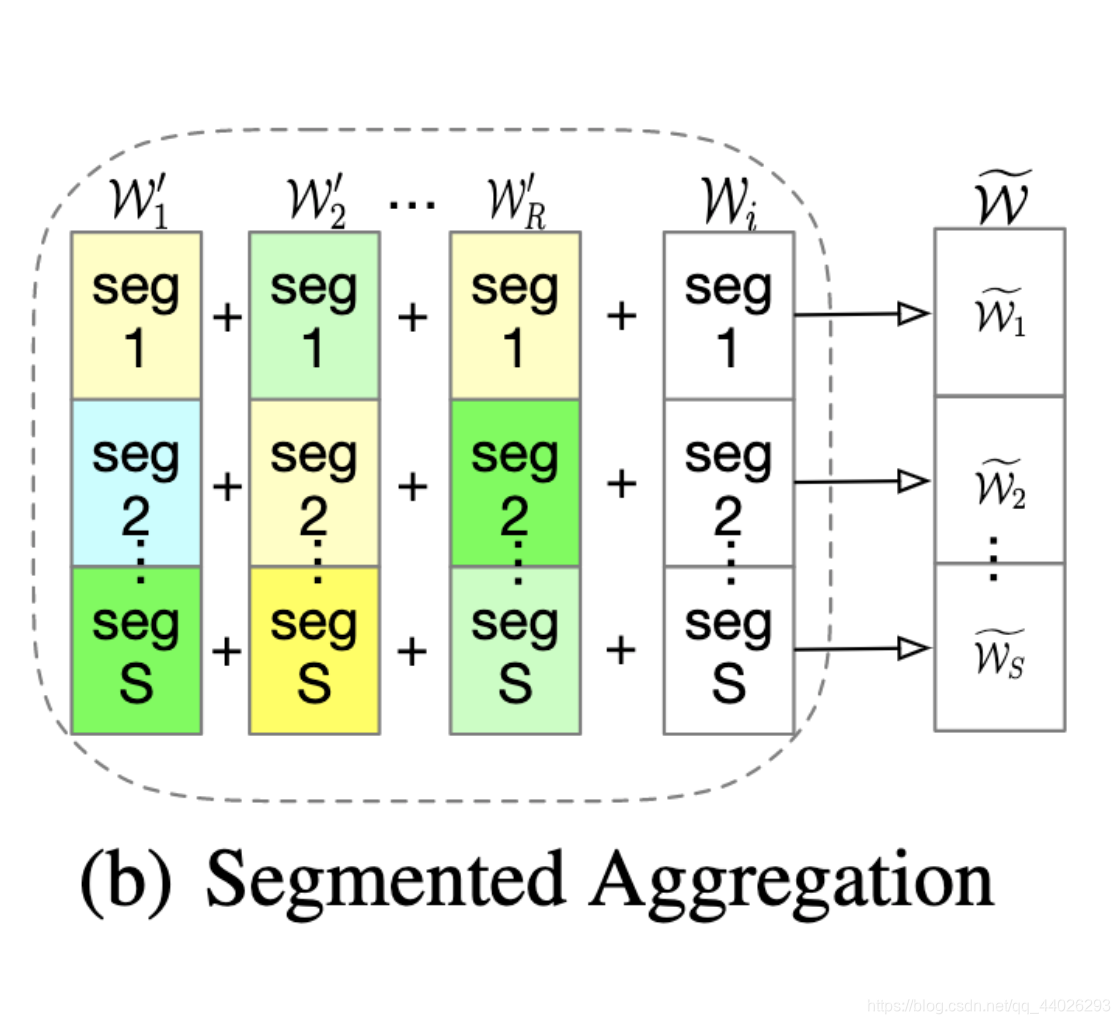
Segmented Aggregation
假设一个节点的 R R R个peer节点的 R R R个mixed model为 W 1 ′ , W 2 ′ , . . . , W R ′ W'_1,W'_2,...,W'_R W1′,W2′,...,WR′。对于每一个模型片段 l l l来说,我们有 R R R个mixed model和一个local model需要聚合。令 P l P_l Pl表示对应片段的节点集合, D j D_j Dj表示节点上的数据集,那么对于模型片段 l l l的聚合方式为:
W ~ [ l ] = ∑ j ∈ P l ∣ D j ∣ W j [ l ] ∑ j ∈ P l ∣ D j ∣ \widetilde{W}[l] = \frac{\sum_{j \in P_l}|D_j|W_j[l]}{\sum_{j \in P_l}|D_j|} W [l]=∑j∈Pl∣Dj∣∑j∈Pl∣Dj∣Wj[l]
因为gossip协议是一个最终一致性协议,因此最后所有节点上的模型都是一样的
算法流程
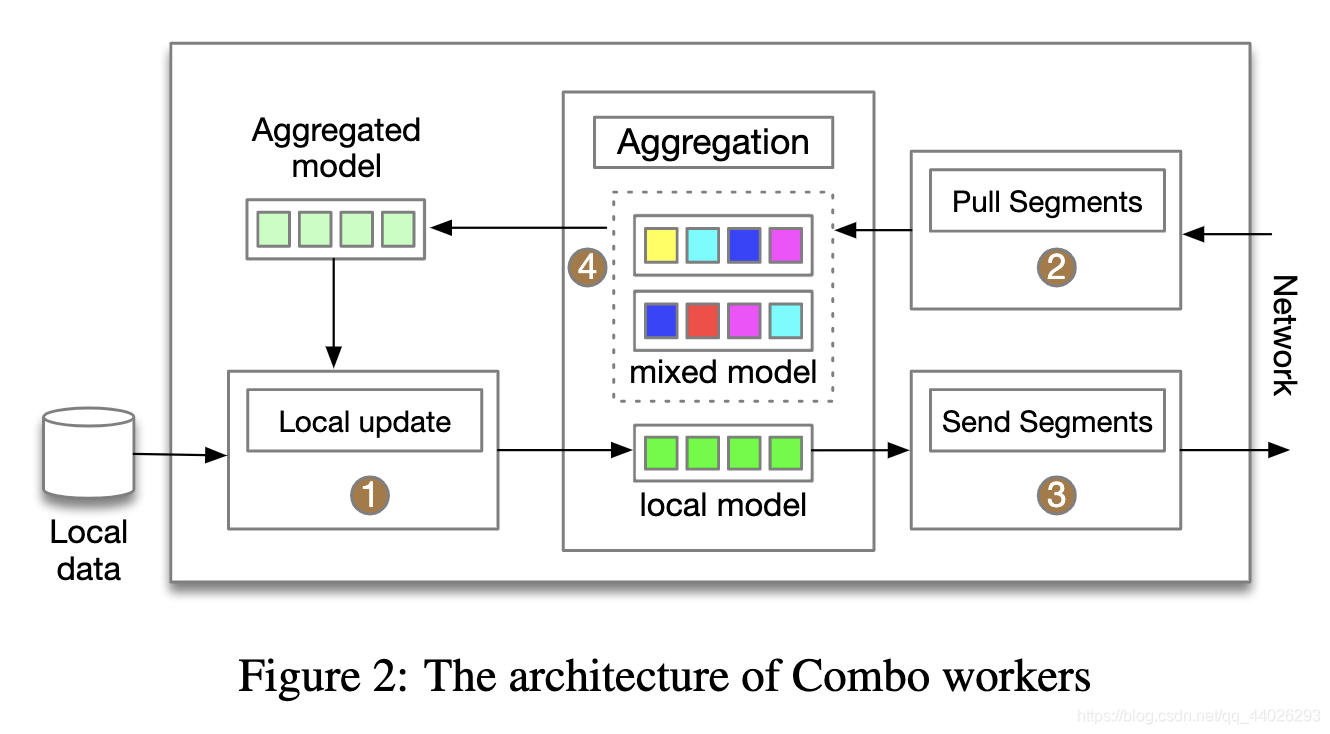
整个算法流程如下:
- Local Update:每个节点用本地数据训练最新拉取之后聚合得到的模型,得到训练之后的新模型
- Segments Pulling:每个节点随机选择 R R R个peer节点,然后随机发送 S × R S\times R S×R个pull请求到其他的peer节点
- Segments Sending:当一个节点收到pull请求的时候,会返回训练好的模型片段
- Model Aggregation:当一个节点收齐 R × S R\times S R×S个模型片段时,便对这些模型进行聚合得到新的模型
训练的流程图如下:
总结
这片文章所讲述的去中心化FL主要有两个核心点:
- gossip协议:使用gossip协议来完成模型的聚合,并通过传染病传播的形式来完成各个节点的“共识”,即最后使得每个节点上的模型相同
- segmentation:如果每次都传输完整的模型,由于通信的瓶颈很容易造成明显的延迟,文章的思想是将模型分段,然后将整个模型的开销分散到多个链路上去,可以提高系统的响应速度,但是总的通信开销并没有减少
改论文所使用的方法虽然确实可以实现去中心化的联邦,但是会大大增大通信的开销。从总体上看,我觉得还是能带来一些不错的启发性思想