文章目录
论文信息
FASTGNN: A Topological Information Protected Federated Learning Approach forTraffic Speed Forecasting

摘要
Federated learning has been applied to various tasks in intelligent transportation systems to protect data privacy through decentralized training schemes. The majority of the state-of-the-art models in intelligent transportation systems (ITS) are graph neural networks (GNN)-based for spatial information learning. When applying federated learning to the ITS tasks with GNN-based models, the existing frameworks can only protect the data privacy; however, ignore the one of topological information of transportation networks. In this article, we propose a novel federated learning framework to tackle this problem. Specifically, we introduce a differential privacy-based adjacency matrix preserving approach for protecting the topological information. We also propose an adjacency matrix aggregation approach to allow local GNN-based models to access the global network for a better training effect. Furthermore, we propose a GNN-based model named attention-based spatial-temporal graph neural networks (ASTGNN) for traffic speed forecasting. We integrate the proposed federated learning framework and ASTGNN as FASTGNN for traffic speed forecasting. Extensive case studies on a real-world dataset demonstrate that FASTGNN can develop accurate forecasting under the privacy preservation constraint.
联合学习已被应用于智能交通系统中的各种任务,以通过分散的训练方案保护数据隐私。智能交通系统(ITS)中最先进的模型的主要优点是基于图神经网络(GNN)的空间信息学习。当将前馈学习应用于基于GNN模型的ITS任务时,现有的框架只能保护数据隐私;然而,忽略了传输网络的拓扑信息。在本文中,我们提出了一种新的分布式学习框架来解决这个问题。具体地,我们引入了一种基于差分隐私的邻接矩阵保护方法来保护拓扑信息。我们还提出了一种邻接矩阵聚合方法,允许基于局部GNN的模型接入全局网络,以获得更好的训练效果。此外,我们提出了一种基于GNN的模型,称为基于注意力的时空图神经网络(ASTGNN),用于交通速度预测。我们将所提出的联合学习框架和ASTGNN集成为FASTGNN,用于交通速度预测。对真实世界数据集的大量案例研究表明,FASTGNN可以在隐私保护约束下进行准确的预测。
Contributions
- 我们提出了一种拓扑信息保护的FL框架FASTGNN,用于交通速度预测概率。该框架利用先进的时空技术集成了基于 GNN 的预测器。这样的框架可以通过不同组织在本地训练模型来提供强大的隐私保护交易速度预测,而无需原始数据和拓扑信息交换。
- 在提出的FL框架中,我们引入了一种基于DP的邻接矩阵保留方法,以保护拓扑信息。我们还开发了一种邻接矩阵聚合机制来生成一个保留的全局网络邻接矩阵。这两种方法保证了我们的框架在隐私和性能之间实现权衡。
- 对真实世界的交通数据集进行了一系列全面的案例研究,以证明所提出的FASTGNN框架的有效性。
PRELIMINARY
Traffic Speed Forecasting on Transportation Networks
一个交通网络可以用无向图表示,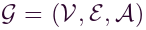 ,其中,V 是节点集,我们将每个节点定义为路段,E 是边的集合,A是G 的邻接矩阵。∀ vi, vj ∈ V, 如果vi, vj是有连接的,则Aij = 1,否则为0。将 G 上观察到的流量速度表示为图范围的特征矩阵 X ,令Xt在时间t处的交通速度观察,因此可以将问题定义为学习一个函数f(·),给定历史交通流量
,其中,V 是节点集,我们将每个节点定义为路段,E 是边的集合,A是G 的邻接矩阵。∀ vi, vj ∈ V, 如果vi, vj是有连接的,则Aij = 1,否则为0。将 G 上观察到的流量速度表示为图范围的特征矩阵 X ,令Xt在时间t处的交通速度观察,因此可以将问题定义为学习一个函数f(·),给定历史交通流量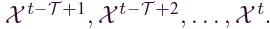 预测后续时间戳的交通流量
预测后续时间戳的交通流量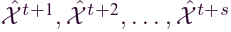 。
。
Federated Learning on Transportation Networks
在本文中,我们构建了用于交通网络上交通速度预测的 FL 框架。我们将“global-network”G定义为一个地区的整个交通网络。这个领域被几个组织(例如公司、政府)划分。令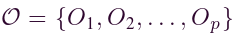 表示组织集,其中 p 是组织的数量。令
表示组织集,其中 p 是组织的数量。令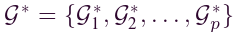 表示局部网络集。这些组织各自的数据库是Di,它们从其运营的本地网络收集流量速度数据。特别的,我们有
表示局部网络集。这些组织各自的数据库是Di,它们从其运营的本地网络收集流量速度数据。特别的,我们有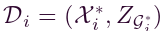 ,其中,
,其中, 分别表示从本地网络收集的历史交通流量数据和拓扑信息。
分别表示从本地网络收集的历史交通流量数据和拓扑信息。
此外,本文基于组织之间没有重叠区域和数据,即对于任何两个组织i和j,Di∩ Dj = ∅。我们的目标是在云中训练一个强大的模型,该模型可以使用来自 Di 的本地流量速度数据预测全局网络范围的流量速度。尽管如此,出于隐私考虑,这些组织被禁止共享其运营的本地网络的原始流量数据和拓扑信息(即他们只能访问本地网络)。
为了在上述隐私约束下实现我们的目标,需要在 FL 框架中采用安全参数聚合机制 (SPAM)。具体而言,由每个组织 Oi 构建的基于图的深度学习模型 Mi 利用来自 Di 的本地训练数据和相应本地网络 G∗i 的拓扑信息计算一组更新的模型参数φi。在所有组织完成参数更新后,其规范参数将上传到云中。全局模型最终通过聚合这些上传的参数来开发。
METHODOLOGY
Attention-Based Spatial-Temporal Graph Neural Networks
针对全网流量速度预测问题,提出ASTGNN作为局部预测模型。如图所示,ASTGNN由特征嵌入模块、空间依赖性捕获模块、时间依赖性捕获模块和预测输出模块四个模块组成。
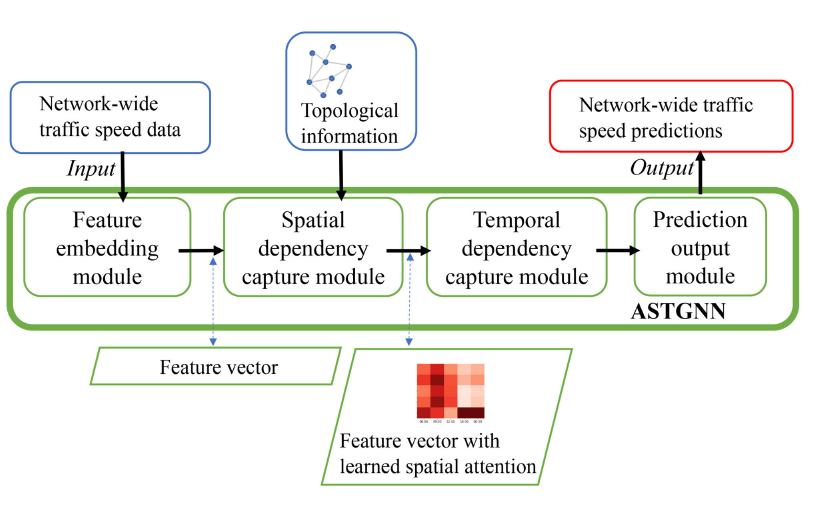
特征嵌入模块
特征嵌入模块将输入的时间序列数据转换为特征向量,之后可由空间依赖性捕获模块进行处理。具体来说,给定时间序列值为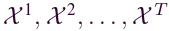 的序列(长度 = T),每个特征向量可以表述为:
的序列(长度 = T),每个特征向量可以表述为:
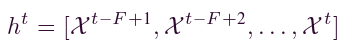
其中ht是时间 t 处的网络范围特征向量; F 是向量的维度,其物理含义等效于过去的窗口大小。这意味着我们实际上将一系列序列数据嵌入到特征向量中,其长度与过去的窗口大小相同。通过这种方式,我们可以获得特征向量序列 h1, h2, . . . , hT。
空间依赖性捕获模块
空间依赖性捕获模块用于利用交通网络中不同路段(节点)之间的空间依赖性(图)。我们通过跟随图注意力网络(GAT)来构建该模块,该网络利用注意力机制获得空间相关性。本模块的操作步骤可描述为以下步骤。
- 我们从计算注意力分数开始。对于任何有序的节点对(vi,vj)∈ V,从vj 感知到 vi 的注意力得分可以表述为:
 。其中
。其中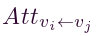 表示注意力得分,hti 和 htj 分别是节点 vi 和 vj 在时间 t 的特征向量,W是可以将特征向量转换为更高维度 Fh 的权重矩阵,concat(·) 表示串联操作,a是权重向量,T 表示转置操作。
表示注意力得分,hti 和 htj 分别是节点 vi 和 vj 在时间 t 的特征向量,W是可以将特征向量转换为更高维度 Fh 的权重矩阵,concat(·) 表示串联操作,a是权重向量,T 表示转置操作。 - 随后,我们使用激活函数来规范注意力得分并获得注意力效率,可以表示为
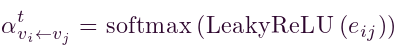 。其中,
。其中,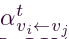 表示注意系数,LeakyReLU(·) 表示LeakyReLU激活函数,softmax(·) 表示 softmax激活函数。
表示注意系数,LeakyReLU(·) 表示LeakyReLU激活函数,softmax(·) 表示 softmax激活函数。 - 接下来,我们过滤得到的注意力系数,仅对连接的节点对存活注意力系数,可以公式化为
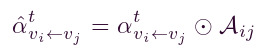 。其中Aij是邻接矩阵 A 中节点 vi 和 vj 的条目,我们可以推断,当 Aij = 1 时,注意力系数仍然存在,否则被丢弃(即等于 0)。
。其中Aij是邻接矩阵 A 中节点 vi 和 vj 的条目,我们可以推断,当 Aij = 1 时,注意力系数仍然存在,否则被丢弃(即等于 0)。 - 最后,利用注意力系数更新节点vi的特征向量,可以表述为:
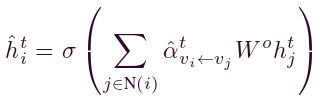 。其中,
。其中,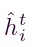 是节点vi 在t时刻的更新特征向量,被视为该模块的输出,N(i)是节点vi紧邻节点的集合,Wo是权重矩阵。
是节点vi 在t时刻的更新特征向量,被视为该模块的输出,N(i)是节点vi紧邻节点的集合,Wo是权重矩阵。
时间依赖性捕获模块
时态依赖关系捕获模块旨在了解数据的潜在时态依赖关系。我们在这个模块中使用了两层GRU神经网络。GRU引入了一组门控单元和细胞状态来处理输入信息,可以解决学习过程中的梯度消失问题。门口单元有两种类型,即复位门r和更新门z。给定输入数据 xt,1 隐藏层输出 htg 可以由下式计算:
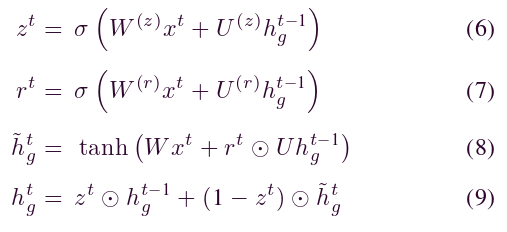
预测输出模块
该模块中集成了一个完全连接的层,以生成期货时间戳的流量速度。这种由全连接层进行的线性变换公式为:
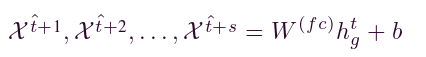
其中,W(fc)是将时态模块中GRU的隐藏输出映射到s预测输出的权重矩阵,b是偏置。
Federated Learning Framework for ASTGNN
如图所示,每个组织运行一个ASTGNN作为本地模型,其输入是来自其本地流量数据库的交通速度数据和拓扑信息。在组织端实现基于DP的邻接矩阵保持算法,保护本地拓扑信息。云服务器负责聚合保存的本地拓扑信息和ASTGNN模型参数,并广播聚合后的拓扑信息。相关算法的详细阐述可以在下面看到。
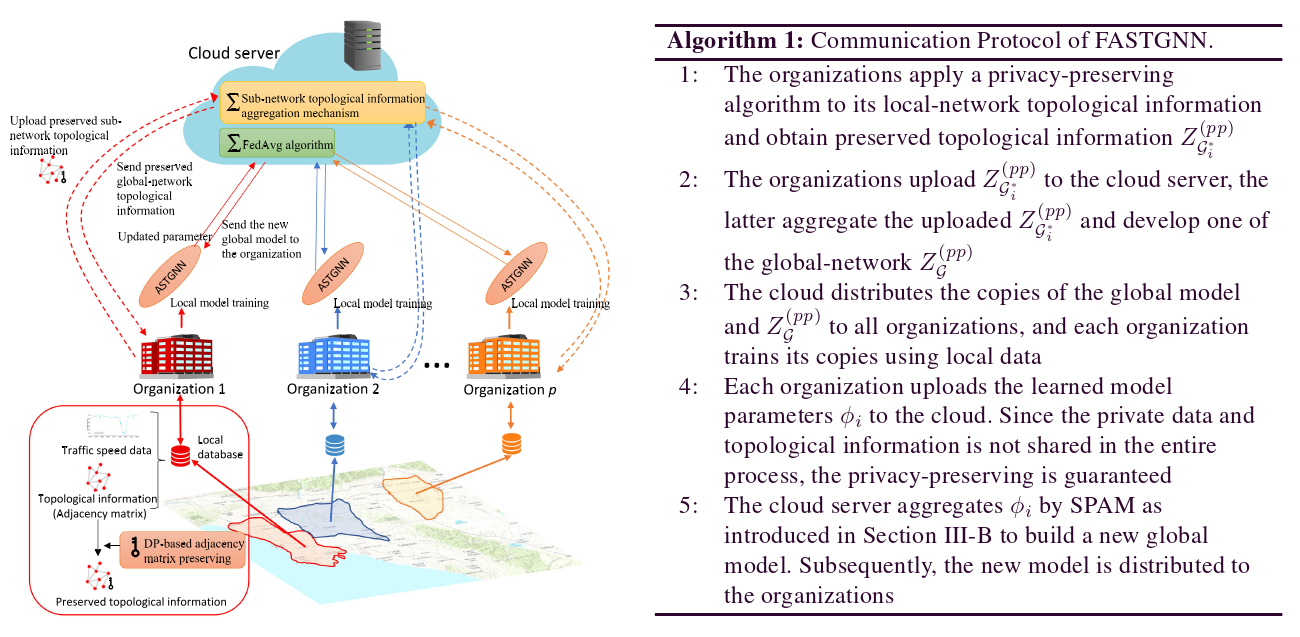
- FASTGNN Communication Protocol
如第 III-B 节中所定义,每个组织只能访问自己的流量数据和本地网络拓扑信息以进行本地模型的训练。仅使用本地网络拓扑信息训练局部模型的一个问题是,本地网络不包含 ASTGNN 计算注意力系数的所有基本拓扑信息。这个问题可能会导致最终的低学习效果(相关的实验比较将在V-C节中演示)。因此,必须将全局网络的拓扑信息馈送到局部模型以获得更好的结果。为了在不损害本地网络拓扑信息的隐私性的情况下实现这一目标,我们提出了一种算法1中所示的FL通信协议。
然后详细介绍了拓扑信息隐私保护算法、本地网络拓扑信息聚合机制、SPAM和整个FL过程。
- DP-Based Adjacency Matrix Preserving
在本文中,我们将局部网络的邻接矩阵作为拓扑信息的载体。我们引入了一种基于DP的方法,为邻接矩阵提供隐私保护,同时保持其在ASTGNN学习过程中的实用性。给定要保护的邻接矩阵 A,算法如下所示:
(1)生成两个高斯随机矩阵 和
和 其中 M 是随机投影的数量。通过这种方式,R(p)和R(q)的每个条目都从高斯分布中独立采样。
其中 M 是随机投影的数量。通过这种方式,R(p)和R(q)的每个条目都从高斯分布中独立采样。
(2)计算投影矩阵 A(p),A(p)=A R(p)通过这样做,A的每一行从高维RN投影到低维RM
(3)扰动 A(p)与高斯随机矩阵 R(q) ,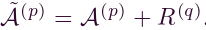
扰动矩阵 被视为保留的原始邻接矩阵 A 之一。邻接矩阵的顶部特征向量主要用于基于GNN的模型来计算空间相关性。
被视为保留的原始邻接矩阵 A 之一。邻接矩阵的顶部特征向量主要用于基于GNN的模型来计算空间相关性。
采用步骤i中所述的随机投影保留了A的顶部特征向量,这为保留的邻接矩阵在后续ASTGNN预测器中的有效性提供了保证。此外,该算法使我们能够涉及少量的随机扰动,这进一步提高了扰动矩阵的效用。在这项工作的案例研究中,我们凭经验设置M = 10和σ = 0.5。
- Local-Network Topological Information Aggregation Mechanism
FASTGNN通信协议的步骤ii要求云服务器聚合上传的Z(pp)G。因此,我们提出一种邻接矩阵聚合机制。给定一组上传的受保护的本地网络邻接矩阵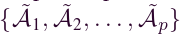 ,其中 p 是涉及的本地网络的数量,它们对应的大小为
,其中 p 是涉及的本地网络的数量,它们对应的大小为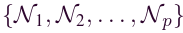 。由于这些矩阵的大小不同,我们首先使用矩阵对齐方法使它们具有相同的大小,同时保留自己的拓扑信息。具体如图所示,我们使用零填充将它们的维度与全局网络的大小对齐,从而获得一组对齐矩阵。
。由于这些矩阵的大小不同,我们首先使用矩阵对齐方法使它们具有相同的大小,同时保留自己的拓扑信息。具体如图所示,我们使用零填充将它们的维度与全局网络的大小对齐,从而获得一组对齐矩阵。
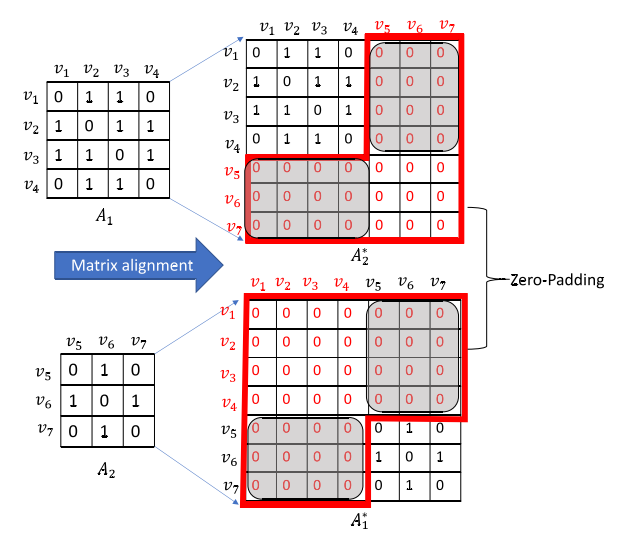
此外,考虑到不同局部网络(如图3所示的阴影区域)之间的连通性对于学习注意力的重要性,我们为它们构建了一个随机连接。具体来说,我们使用IV-B2节中介绍的方法生成一个与阴影区域大小相同的高斯随机矩阵,并对称地替换原始部分。最后,通过将对齐矩阵相加得到聚合保留的邻接矩阵,可以表述为
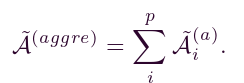
4. Learning Process of FASTGNN
在 FASTGNN 中,我们使用 FedAvg 算法作为SPAM来聚合上传的参数并得到全局模型。
最后,如算法 2 所示,FASTGNN 中每一轮的整个学习过程包括三个步骤:

(1)云服务器广播带有初始参数的全局模型以及受保护的全局网络邻接矩阵到每个组织。
(2)每个组织通过本地数据训练并更新全局模型参数。
(3)服务器通过联邦平均算法聚合每个组织训练的模型参数得到新的全局模型。
- Theoretical Discussion of DP-Based Adjacency Matrix Preserving on Model Performance
许多现有的研究表明,DP算法添加到数据中的噪声可能导致退化的学习,并进一步影响模型性能。在我们提出的方法中,噪声被添加到邻接矩阵而不是数据中。在每个局部模型的学习过程中,采用聚合DP处理的全局邻接矩阵-A(聚合)仅过滤(4)中所述的注意力系数。由于 ̃A(聚合)近似于二元矩阵(即 (0,1)-矩阵)经过 DP 处理和聚合,因此注意力系数的值不会受到显着影响。因此,可以保证有希望的最终模型性能。此外,现有的性能损失是由于在邻接矩阵上处理和聚合DP后,原始全局拓扑与新全局拓扑之间的差异。