前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、数据重塑和轴向旋转
1、层次化索引
层次化索引是pandas重要的一个功能,可以在一个轴上拥有多个索引。
多重索引:
s = pd.Series(np.arange(1,10),index=[['a','a','a','b','b','c','c','d','d'],[1,2,3,1,2,3,1,2,3]])
s
结果:

可以通过unstack方法可以将Series变成一个DataFrame,下图左边是Series示意图,右边是DataFrame的形式,Series通过unstack方法变成一个DataFrame可能会产生缺失值。

用unstack方法可以将Series变成一个DataFrame结果如下:

如果想要转回Series:s.unstack().stack()
2、DataFrame的层次化索引
定义一个DataFrame的多层索引:
data = pd.DataFrame(np.arange(12).reshape(4,3),index=[['a','a','b','b'],[1,2,1,2]])
data
对行做了两次的索引,外层就是a,b,然后分别对外层做一个索引,结果如下:

对行和列都做了两次的索引,代码和结果如下:
data = pd.DataFrame(np.arange(12).reshape(4,3),index=[['a','a','b','b'],[1,2,1,2]],columns=[['A','A','B'],['Z','X','C']])
data
#给行和列的索引名称
data.index.names=['row1','row2']
data.columns.names=['col1','col2']
data
#对索引调整顺序
data.swaplevel('row1','row2')
#转置
data.T

从上图我们可以知道每一个值都是4个索引而决定的。
对于DataFrame表时,set_index可以吧列变成索引,reset_index是吧索引变成列的,对于每一个索引就是一个元组。
二、数据分组,分组运算
GroupBy:实现数据分组和分组运算,和数据透视表类似,只对数字型进行运算。工作原理类似于下图:

根据一个变量进行分组具体操作步骤如下:
group = w.gruopby(w['产地'])#按电影产地进行分组
group.mean()#对所有的数值型数据都进行平均数计算
#对具体的某一列进行计算
w['评分'].groupby(w['年代']).mean()#计算每年的平均评分
根据多个变量进行分组具体操作步骤如下:
w.groupby([w['产地'],w['年代']]).mean()
#获得每个地区,每一年的电影评分的均值
w['评分'].groupby([w['产地'],w['年代']]).mean()
三、离散化处理
在我们实际的分析中,对于等级的数据我们不关心它的绝对取值,而是关心它的区间和级别。对于离散化可以称为分组、区间化。pandas中有一个函数cut()函数
pd.cut(x,bins,right=True,labels=None,retbins=False,precision=3,include_lowest=False)其中:
x:需要离散化的数据
bins:分组依据
right=True:是不是要包括右端点,默认情况是包括
include_lowest=False:是不是要包括左端点,默认情况是不包括
labels=None:定义区间的标签
对电影评分进行离散化:
w['评分等级'] = pd.cut(w['评分'],[0,3,5,7,9,10],labels=['E','D','C','B','A'])
结果如下:

根据投票人数来刻画电影的热门:
#先定义bins
bins = np.percentile(w['投票人数'],[0,20,40,60,80,100])#按百分比分区间
w['热门程度'] = pd.cut(w['投票人数'],bins,labels=['E','D','C','B','A'])
w[:5]
结果如下:

四、合并数据集
1、append
append就是把两个数据集上下拼接在一起,用的不是很多。
#先拆分
w_usa = w[w.产地=='美国']
w_china = w[w.产地=='中国大陆']
#合并
w_china.append(w_usa)
2、merge
pd.merge(left,right,how=‘inner’,on=None,left_on=None,right_on=None,left_index=False,right_index=False,sort=True,suffixes=(’_x’,’_y’),copy=True,indicator=False)其中:
left:对象
right:另一个对象
how:通过什么方式保留,默认是内在连接,有左,右,外在。
on:要加入的列(名称)。必须在左、右综合对象中能够找到的。如果左右找不到,就 left_on和right_on来确定。
left_on:从左边的综合使用作为键列。可以是列名或者数组的长度等于综合长度。
right_on:从正确的综合,作为键列,可以是列名或者数组的长度等于综合长度。
left_index:如果是True,则使用索引(标签)从左综合作为其链接键。在与多重(层次)的综合,级别数匹配链接从右综合的数目
right_index:与left_index做法相似
sort:综合通过连接键按字典顺序对结果进行排序。默认是True,设置为False将提高性能极大地在数多情况下。
suffixes:字符串后缀并不适用重叠列的元组。默认值(’_x’,’_y’)。
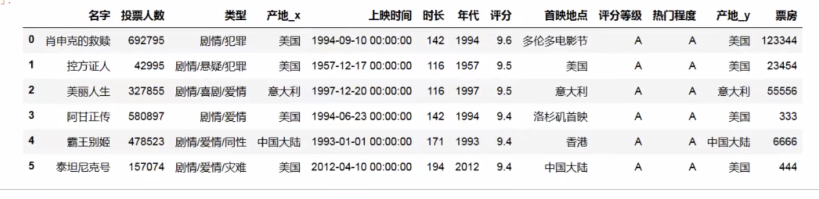
下面是选6个热门电影进行操作:
w1 = w.loc[:5]#选取前6行
w2 = w.loc[:5]['名字','产地']
w2['票房'] =[123344,23454,55556,333,6666,444]
#打乱数据
w2 = w2.sample(frac=1)
w2.index = range(len(w2))
#合并
pd.merge(w1,w2,how='inner',on='名字')
合并结果如下:
3、concat
concat可以把多个数据集进行批量的合并。
w1 = w[:10]
w2 = w[100:110]
w3 = w[200:210]
ww = pd.concat([w1,w2,w3],axis=0)#默认axis=0是增加行数