深度学习基础
1. 什么是感知机?如何训练感知机?
感知机,也就是单个神经元。可以理解为广义线性回归 Y = f(WX + B);即它可以接收信号X,并加上偏值,通过一个激活函数输出。但是单个感知机的能力很弱(从它只能处理二分类线性可分问题可以看出),因此,我们可以引入多个神经元,多层神经元来提高它的能力。(多个多层神经元构成神经网络。)
训练感知机的方法就是利用梯度下降法,反向传播。因此我们需要一个loss,即输出值和真实值之间的距离,并使用梯度下降法在训练中不断缩小他们的差距。(loss=(y-y‘)^2+正则化项)
对于神经网络模型:Linear -> ReLu -> Linear -> MSE(Loss function)来说,反向传播就是根据链式法则对求导,用输出误差的均方差(MSE)对模型的输出求导,并将导数传回上一层神经网络,用于它们来对w、b和x(上上层的输出)求导,再将x的导数传回到它的上一层神经网络,由此将输出误差的均方差通过递进的方式反馈到各神经网络层。
2. 什么是激活函数,它有什么用?
在神经网络中,我们希望神经元之间传递的信息是不同的,是经过加工处理过的。如果我们不使用激活函数,用线性函数直接输出到下一层神经元,那整个神经网络的运作等同于单个感知机,因为每个神经元直接把信息传递给下一个神经元。因此,激活函数在每一个神经元中起到很大的作用。
激活函数给神经元起到了非线性能力。我们知道我们认识的很多函数实际上都不是线性的,什么三角函数什么幂函数等等。我们希望神经网络能够处理所有的函数,因此使用激活函数,给神经元提供非线性能力,让他们也能够处理非线性问题。
3. 激活函数有哪些?该如何选择?
(1)sigmoid函数:这是最早使用的激活函数之一,它可以将输入的数值挤压到0-1之间。越接近0表示该神经元没被激活,越接近1表示该神经元被激活。但是它存在的问题就是,它的函数是饱和函数,也就是它在数值较大或者较小的时候,曲线非常平坦,梯度越来越小,甚至为0。我们需要神经网络在训练中通过反向传播不断更新权重,当梯度为0的时候,就会造成权重不更新,造成梯度弥散问题,因此我们在隐藏层中一般不用sigmoid。如果输出希望是0-1的数值时候(适用于二分类问题),可以将sigmoid使用在输出层。

(2)tanh函数:tanh是在sigmoid基础上的改进,将压缩范围调整为-1-1之间。它和sigmoid的区别就是它是0均值的。但是缺点和sigmoid一样,都是饱和函数。会造成梯度弥散问题。因此只能在输出层处理二分类问题。

(3)Relu函数:目前最常用的激活函数,它的公式很简单,不像上面两个函数都带指数函数因此计算慢。relu输入小于0的时候为0,大于0的时候是本身。由此带来的问题就是,当输入为负的时候,输出值就为0,使得后面的输入都为0。导致神经网络中很多神经元坏死。

(4)LeakyRelu函数:改进了Relu当输入为负的时候,输出为0的问题。当输入为负值的时候,给定一个较小的斜率。这样就避免了神经元在传播的途中坏死的问题。
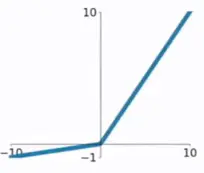
(5)softmax函数:用于多分类输出。它可以生成不同类别的概率。(即多个类别分别的概率,概率和为1。)
(6)线性函数(不激活):处理回归问题的输出。
(7)mish函数:最近yoloV4里面大量使用了mish函数,mish与relu得区别就在于,mish比relu得函数更加平滑,并且允许在负值上有轻微得梯度变化。
mish引入得一个激活函数得思想就是平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化。

4. 卷积神经网络和全连接神经网络有什么区别?
- 我们知道神经元可以接收信息,并对信息进行处理后输出。
- 如果我们需要对一张图片输入进神经元,在全连接神经网络中,我们要对整张图片逐个像素全部输入,并得到一个特征值。计算慢,而且对所有的信息全盘接收。实际上我们并不需要那么多信息,例如我们要判断照片里人的位置,但实际上照片里有许多地方是背景信息,所以我们并不需要全部的信息,只需要有人的那一部分信息就能提取出人的特征,背景信息提取出来的反而是噪声。
- 并且全连接每个输入都必须有个参数W,而输入越多,参数量越大,计算量也就越大,并且全连接网络需要固定输入的数量。但是全连接有一个好处就是,可以避免信息量的丢失。
- 卷积神经网络就是解决这样一个问题。我们知道卷积运算可以提取特征,即通过不同的卷积核就可以提取出图片的特征。(图像卷积运算) 我们看一张图片,肯定不会一个像素一个像素去看,我们会一块一块的去看。例如看一张集体照,我们要找自己认识的人,那么就会一个人一个人看有没有认识的。卷积也是这样一个道理,逐行逐列通过卷积核扫描,得到一张特征图,特征图上面的特征就包含着这个图上的信息(背景,人,物)。这张特征图就是该神经元的输出。而卷积核是通过神经网络自己学习调整。
- 卷积利用的图像局部性的特点。特征图每个像素就相当于图像上每个局部特征的输出,整个特征图就是多个输出。与全连接不同的是,全连接全盘接收只输出一个特征。
- 卷积神经网络的好处:w和b的共享,每个神经元参数量的减少,也就大大减少了计算量。
- 全卷积神经网络可以任意尺寸输入。
5. 卷积后特征图的尺寸如何计算?
由于卷积核一般都是大于1的,因此在边界时候往往不能进行卷积。所以即使按步长为1进行卷积,得到的特征图也会比原图小。所以我们可以在卷积前对原图进行padding填充。因此卷积后的特征图的尺寸就与卷积核、步长、padding有关。
new_width=(old_width−F+2×P)/S+1
new_height=(old_height−F+2×P)/S+1
F为卷积核的大小,P为padding,S为步长。
6. 什么是感受野?有什么用?
感受野就是卷积后输出特征图上的某个特征点的位置代表前面特征图(图片)上多大的范围。
(找了个图,来源这里,这里也详细介绍了感受野的概念和实例)可以看到经过五次卷积后,一个像素的感受野就有原图像上10 * 10的范围那么大。

感受野有什么用呢?
一般task要求感受野越大越好,如图像分类中最后卷积层的感受野要大于输入图像,网络深度越深感受野越大性能越好
密集预测task要求输出像素的感受野足够的大,确保做出决策时没有忽略重要信息,一般也是越深越好
目标检测task中设置anchor要严格对应感受野,anchor太大或偏离感受野都会严重影响检测性能
7. 如何扩大感受野?
- 卷积神经网络的网络层次越深,感受野越大。
- 池化:池化的实质是进行特征降维,使得网络更加关注某些特征。(换句话说就是把特征图缩小,同时放大了感受野。)
- 空洞卷积(在低计算量的情况下,扩大了感受野):本质也是增加了网络层次。
8. 池化的方式以及作用有哪些?
- 池化的方式:最大池化;平均池化;自适应池化(保持输出的形状)。
- 池化的作用:特征不变形(使得网络更加关注某些特征:最大池化);特征降维(把特征图缩小,扩大感受野);在一定程度上防止过拟合;平均池化还可以作为图像缩放。(平均池化丢失的信息少)
9. 什么是过拟合,如何防止过拟合?
过拟合:表示神经网络模型在训练集上的表现很好,但是泛化能力比较差,在测试集上表现不好。
神经网络对训练集过拟合,也就是这个神经网络只认识训练集中的数据,换个数据它就不认识了。就比如,同一张试卷,我做了十遍上百遍,答案都倒背如流,但是换了一张试卷我就蒙圈了。这也就是说,我们在训练神经网络的时候,数据集的泛化能力越大越好。我们考试不也是题目刷得越多,各种各样的题目都刷,考试得能力就越强。同样得道理,神经网络在学习得时候也是如此。
因此防止过拟合,首先可以从数据入手。
防止过拟合的方法:
- 数据:增大数据集(这里要更多的提供各种不同样式的数据集,尽量提高数据集的泛化能力);数据增强(本质也是扩增数据集)。
如果我们已经有了足够多的训练数据,但是我们训练的模型还是会发生过拟合的话,那就有可能是我们的模型过于复杂了,导致模型对一些数据中的一些噪声都进行了和好的拟合。模型只是对部分数据产生过拟合,我们可以在保证模型能够正确的拟合出数据中的规则的同时,又能适当的降低模型的复杂度,减少模型对抽样误差的拟合程度。适当的降低模型的复杂度,不仅能很好降低模型的过拟合程度,同时也能提高模型的训练速度以及运行速度。
- 网络优化:①正则化:在损失函数中引入正则化项来降低模型的复杂度,从而有效的防止模型发生过拟合现象。② dropout(随机丢掉一些神经元,使网络变笨。)
10. 什么是梯度弥散、梯度暴涨?如何防止?
梯度弥散:由于导数的链式法则,连续多层小于1的梯度相乘会使梯度越来越小,最终导致某层梯度为0。
梯度爆炸:由于导数的链式法则,连续多层大于1的梯度相乘会使梯度越来越大,最终导致梯度太大的问题
我们在训练神经网络的时候,使用的是梯度下降法。所以就希望梯度保持稳定,如果梯度消失了,那么会导致网络前几层的参数不再更新,神经元也就停止运作;如果梯度爆炸了,会使得权重过大,导致网络不稳定,甚至可能使得网络崩溃。
防止梯度暴涨、弥散的措施
梯度暴涨:
① 更换激活函数,例如使用relu这样梯度稳定的函数;
② 对权重使用正则化,压低权重;
③ 梯度截断,当梯度超过一定阈值时候,降低它的数值。
梯度弥散:
① BatchNorm:将输出的权重标准正态分布化;(只能在训练时候用,要记得设置训练状态和测试状态。)BN算法对训练集的BatchSize数量敏感。
② 更换激活函数。
11. 如何发现是否发生了梯度暴涨或者梯度弥散?
- 可以在训练时将每层的权重、训练的损失和梯度打印出来;
- 梯度暴涨的时候,损失可能会变成NAN,或者发生显著变换(波动明显),梯度快速增大;
- 梯度弥散的时候,查看每层网络的权重,如果权重在某一层停止更新,或者损失不降低,但是权重越来越趋近平滑,梯度很接近于0。
12. 什么是残差网络,为什么要引入残差网络?
- 我们知道,随着网络的层次变深。容易出现的一个问题就是,梯度弥散和梯度爆炸。即使通过一些正则化解决,也还会存在模型退化的问题,即准确率反而更低。
- 模型会退化。显然,信息在传播的过程中是有损失的,所以越深的网络能够学到的信息就越少,所以就更难训练。因此残差网络就是用来解决模型退化的问题。
- 残差网络的本质就是将输入的信息作为残差加入到输出的结果中,从而降低信息在神经网络中丢失。(要求输出和输出同尺寸)
13. 1 * 1 和 3 * 3 的卷积核有什么区别,1 * 1的卷积核有什么用?
- 在卷积神经网络中,我们利用卷积来扩充特征通道数,因此不管是1 * 1 还是 3 * 3 的卷积核 ,都可以使得特征信息在通道层面上充分混合。
- 但是 1 * 1 在像素层面上是逐个像素卷积,因此在像素层面上没有充分混合。所以它的计算量要比3 * 3的卷积核小。
- 因此,我们可以使用1 * 1的卷积核对特征进行降维(降低通道数),在用3 * 3的卷积核进行运算,这样就能使得特征在像素层面和通道层面上都得到充分融合,且运算量比降维前的3 * 3卷积还小。
- ( 1 * 1的卷积核一般只用来升维和降维:控制通道数 )

14. 卷积神经网络常用的优化子结构网络有哪些?
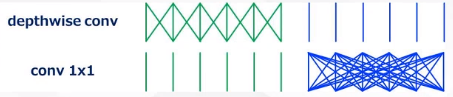
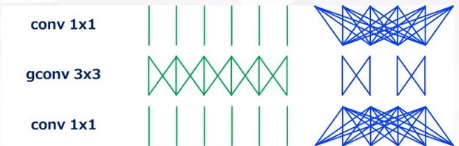
(1)分离卷积:主要使用在通道上,卷积在扩增通道时候相当于在输入输出通道数上施行全连接,因此它的计算量比较大。所以在施行通道分离,对局部数据进行连接,从而降低计算量。(类似于卷积利用了数据的局部性)
缺陷:通道之间的关联会分离(信息上的交流变少),即通道之间混合不充分,参数量降低了,网络会变笨。

下面是不同分组下的同个卷积操作的计算量:
from torch import nn
import thop
import torch
conv = nn.Conv2d(4,20,3,1) # 通道上无分组
conv_g1 = nn.Conv2d(4,20,3,1,groups=2) # 通道上分两组
conv_g2 = nn.Conv2d(4,20,3,1,groups=4) # 通道上分四组
x = torch.randn(1,4,112,112) # 模拟输入
t1 = thop.clever_format(thop.profile(conv,(x,)),"%.3f")
t2= thop.clever_format(thop.profile(conv_g1,(x,)),"%.3f")
t3 = thop.clever_format(thop.profile(conv_g2,(x,)),"%.3f")
print(t1,t2,t3) # 8.954M/740B 4.598M/380B 2.420M/200B
(2)通道混洗:从(1)我们知道,直接使用分离卷积会使网络变笨。本质原因就是通道层面上混合不充分,因此可用1 * 1的卷积进行通道混洗的方式对通道进行充分混合。(如下图所示,本质就是为了让通道之间信息交流)

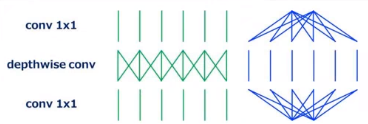
(3)MobileNetV1:我们希望在计算量降低的前提条件下,卷积神经网络能够在像素层面和通道层面上都充分融合。因此,可以先用3 * 3的卷积,并且通道上一对一分组卷积(depthwise_conv),再用1 * 1的卷积对通道进行充分融合。这样就能够降低计算量,并且特征充分融合。
优点:① 计算量降低;② 网络层次更深(提高抽象能力)。
缺点:可能出现参数量太少,网络变弱。(MobileNetV2)
(4)MobileNetV2:(改进版本的mobileNetV1)
附网络结构以及pytorch代码:

import torch
from torch import nn
# 配置
config = [
[-1, 32, 1, 2],
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1]
]
class Block(nn.Module):
def __init__(self, p_c, i, t, c, n, s):
super().__init__()
self.i = i
self.n = n
_s = s if i == n - 1 else 1 # 判断是否是最后一次重复,最后一次重复步长为2
_c = c if i == n - 1 else p_c # 判断是否是最后一次重复,最后一次重复负责通道变换为下层的输出
_p_c = p_c * t # 输入通道通道扩增倍数
self.layer = nn.Sequential(
nn.Conv2d(p_c, _p_c, 1, _s, bias=False),
nn.BatchNorm2d(_p_c),
nn.ReLU6(),
nn.Conv2d(_p_c, _p_c, 3, 1, padding=1, groups=_p_c, bias=False),
nn.BatchNorm2d(_p_c),
nn.ReLU6(),
nn.Conv2d(_p_c, _c, 1, 1, bias=False),
nn.BatchNorm2d(_c)
)
def forward(self, x):
if self.i == self.n - 1:
return self.layer(x)
else:
return self.layer(x) + x
class MobilenetV2(nn.Module):
def __init__(self, config):
super().__init__()
self.input_layer = nn.Sequential(
nn.Conv2d(3, 32, 3, 2, 1, bias=False),
nn.BatchNorm2d(32),
nn.ReLU6()
)
self.blocks = []
p_c = config[0][1]
for t, c, n, s in config[1:]:
for i in range(n):
self.blocks.append(Block(p_c, i, t, c, n, s))
p_c = c
self.hidden_layer = nn.Sequential(*self.blocks)
self.ouput_layer = nn.Sequential(
nn.Conv2d(320, 1280, 1, 1, bias=False),
nn.BatchNorm2d(1280),
nn.ReLU6(),
nn.AvgPool2d(7, 1),
nn.Conv2d(1280, 10, 1, 1, bias=False)
)
def forward(self, x):
h = self.input_layer(x)
h = self.hidden_layer(h)
h = self.ouput_layer(h)
h = h.reshape(-1, 10) # 这里直接做个形状变换
return h
if __name__ == '__main__':
net = MobilenetV2(config)
y = net(torch.randn(1, 3, 224, 224))
print(y.shape)
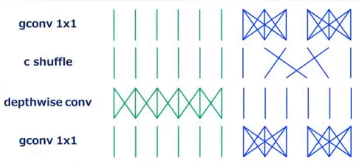
(5)ShuffleNet:
(6)ResNet(Bottleneck):将数据有损压缩,再恢复。(网络在不断训练中,实际上数据丢失的部分会越来越趋向于丢掉一些不重要的信息,保留重要信息。)
又称为自编码器、瓶颈结构,为了减少压缩时候信息的丢失,可以在输入输出上连接一个残差结构。(保证层数更深时,网络不会退化)
优点:降低计算量;层次更深,模型更聪明,精度也提升。
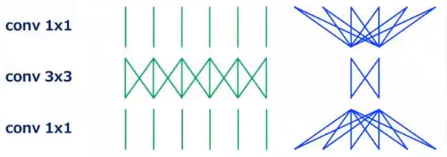
(7)ResNeXt:Rexnet的改进版本。(通道数比较多的情况)
(8)Inception:
主要思路是:如何使用一个密集成分来近似或者代替最优的局部稀疏结构。
(9)SqueezeNet:SqueezeNet详细解读
(10)EfficientNet:速度与精度的结合 - EfficientNet 详解
15. 什么是损失函数,损失函数有哪些?
深度学习中神经网络的目的就是为了使预测结果无限接近真实结果。损失就是用来描述预测样本与真实样本之间的距离的。
深度学习中损失函数是整个网络模型的“指挥棒”, 通过对预测样本和真实样本标记产生的误差反向传播指导网络参数学习。
常用的损失函数:L1损失(MAE)、L2损失(MSE)、SMOOTH_L1损失。
(1)L1损失:
平均绝对误差(MAE)是另一种常用的回归损失函数,它是目标值与预测值之差绝对值的和,表示了预测值的平均误差幅度,而不需要考虑误差的方向,范围是0到∞。
优点:对任何输入的数值,都有着固定的梯度,不会导致梯度暴涨,具有稳健性。
缺点:在中心点是折点,不能求导,而且会导致梯度振荡。
(2)L2损失:
均方误差(MSE)是回归损失函数中最常用的误差,它是预测值与目标值之间差值的平方和。
优点:函数连续光滑,每个点都可以求导,具有较为稳定的解,不会造成梯度振荡。
缺点:在输入的数值较大,即较远处的时候,梯度过大,容易形成梯度暴涨的问题,不稳健。对异常点敏感。
(3)smooth L1:
smoothL1损失对离群点(异常点)更加鲁棒,相比于L2损失函数,其对离群点(指的是距离中心较远的点)、异常值(outlier)不敏感,可控制梯度的量级使训练时不容易跑飞。综合了L1,L2损失的优点,避免了它们的缺点。

(4)其他损失设计:① focalloss,② Centerloss,③ circle-loss,④ softmax(Asoftmax、arcface、AM-softmax)