前言
我们来用手写数字这个入门案例,拿它来熟悉一下pytorch
正文
讲解链接如下:
https://www.bilibili.com/video/BV1fA411e7ad?p=13
本文代码的网络结构与视频讲解结构不同的是,本文将网络换成了LeNet网络
实现代码:
import numpy as np
import os
import torch
import torchvision
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 定义超参数
Epochs = 3
learning_rate = 0.01
batch_size_train = 64
batch_size_test = 1000
# 1、准备数据集(其中0.1307和0.3081是MNIST数据集的全局平均值和标准偏差)
train_loader = DataLoader(MNIST(root='./data/', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.1307,), (0.3081,))
])), batch_size=batch_size_train, shuffle=True)
test_loader = DataLoader(MNIST(root='./data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.1307,), (0.3081,))
])), batch_size=batch_size_test, shuffle=True)
# 查看一下test_loader的size与target
example = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(example) #读取
print(example_data.shape)
# print(example_targets)
# 2、构建网络,此处用手写数字的LeNet网络结构
class MnistNet(nn.Module):
def __init__(self):
super(MnistNet, self).__init__()
self.conv1 = nn.Sequential(nn.Conv2d(1, 6, 3, 1, 2), nn.ReLU(),
nn.MaxPool2d(2, 2))
self.conv2 = nn.Sequential(nn.Conv2d(6, 16, 5), nn.ReLU(),
nn.MaxPool2d(2, 2))
self.fc1 = nn.Sequential(nn.Linear(16 * 5 * 5, 120),
nn.BatchNorm1d(120), nn.ReLU())
self.fc2 = nn.Sequential(
nn.Linear(120, 84),
nn.BatchNorm1d(84),
nn.ReLU(),
nn.Linear(84, 10))
def forward(self, input):
x = self.conv1(input)
x = self.conv2(x)
x = x.view(x.size()[0], -1) #对参数实现扁平化(便于后面全连接层输入)
x = self.fc1(x)
out = self.fc2(x)
return F.log_softmax(out)
# 初始化网络与优化器
model = MnistNet()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 已存在模型则加载模型
if os.path.exists("./model/model.pkl"):
model.load_state_dict(torch.load("./model/model.pkl"))
optimizer.load_state_dict(torch.load("./model/optimizer.pkl"))
# 3、训练
def train(epoch):
for idx, (input, target) in enumerate(train_loader):
optimizer.zero_grad() # 手动将梯度设置为零,因为PyTorch在默认情况下会累积梯度
output = model(input)
loss = F.nll_loss(output, target) # 得到交叉熵损失
loss.backward()
optimizer.step() #梯度更新
if idx % 50 == 0:
print('Train Epoch: {} idx:{}\tLoss: {:.6f}'.format(
epoch, idx, loss.item()))
# 模型的保存
if idx % 100 == 0:
torch.save(model.state_dict(), './model/model.pkl')
torch.save(optimizer.state_dict(), './model/optimizer.pkl')
# 4、模型评估(测试)
def test():
loss_list = []
acc_list = []
for idx, (input, target) in enumerate(test_loader):
with torch.no_grad(): #测试无需进行梯度下降操作
output = model(input)
cur_loss = F.nll_loss(output, target)
loss_list.append(cur_loss)
predict = output.max(dim=-1)[-1]
cur_acc = predict.eq(target).float().mean()
acc_list.append(cur_acc)
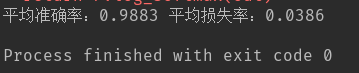
print("平均准确率:%.4f" % np.mean(acc_list), "平均损失率:%.4f" % np.mean(loss_list))
if __name__ == '__main__':
for i in range(3):
train(i)
test() # 评估
用训练的模型进行评估(测试)