第一章 :状态化流处理概述
数据处理框架
把数据处理框架分为两类
- 事物型处理:企业日常运营业务中的各类应用
- 企业资源规划(ERP),客户关系管理(CRM)还有一些基于Web的应用
- 独立的数据处理层:也就是应用程序本身:连接外部用户或者服务,处理操作传入的数据,每次操作都会访问数据库读取或者更新状态
- 数据存储层:事物型数据库,外部操作就会访问这个数据库
- 这种“单点”在扩容更新会有问题,现在用微服务——解耦,接口通信,部署到不同的容器中
- 企业资源规划(ERP),客户关系管理(CRM)还有一些基于Web的应用
- 分析型处理
- 需要对不同类型的数据进行联合分析的时候,建一个数据仓库(专门处理分析查询),将事务性数据库中的数据拷贝到仓库中就是ETL (提取-转换-加载)
- 对于数据仓库就需要定期整合报告或者ad-hoc query(即席查询),过程中就用到了Hadoop生态的组件,完成数据仓库和一系列操作,代替关系型数据库,用HDFS
- 在建立数仓和对数仓中的数据进行分析的过程就用到了流处理技术
状态化处理
- 事件流当中对于跨记录转换都需要状态,每次处理新事件的时候能够读写之前的状态
- Flink用的就是内存和内嵌式数据库作为状态存储,定期备份
- 像Kafka这种日志系统和Flink相连,部署在Flink上的流处理应用进行事件的分析处理
- 几种流处理应用
- 事件驱动型:通过事件触发不同的业务逻辑,进行后续的操作;类似于微服务架构的模式,不同的应用之间通过日志系统通信了,而且访问本地状态的速度要比访问数据库更快
- 数据管道:低延时的ETL
- 流式分析:不用像数仓或者Hadoop那样批处理来分析数据,实时分析,还有实时SQL
运行例子
配置好java;Flink的tar包官网上下载解压,配置环境变量
1.启动集群
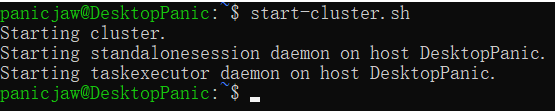
没有配置环境变量的话到Flink的bin包下使用start命令即可
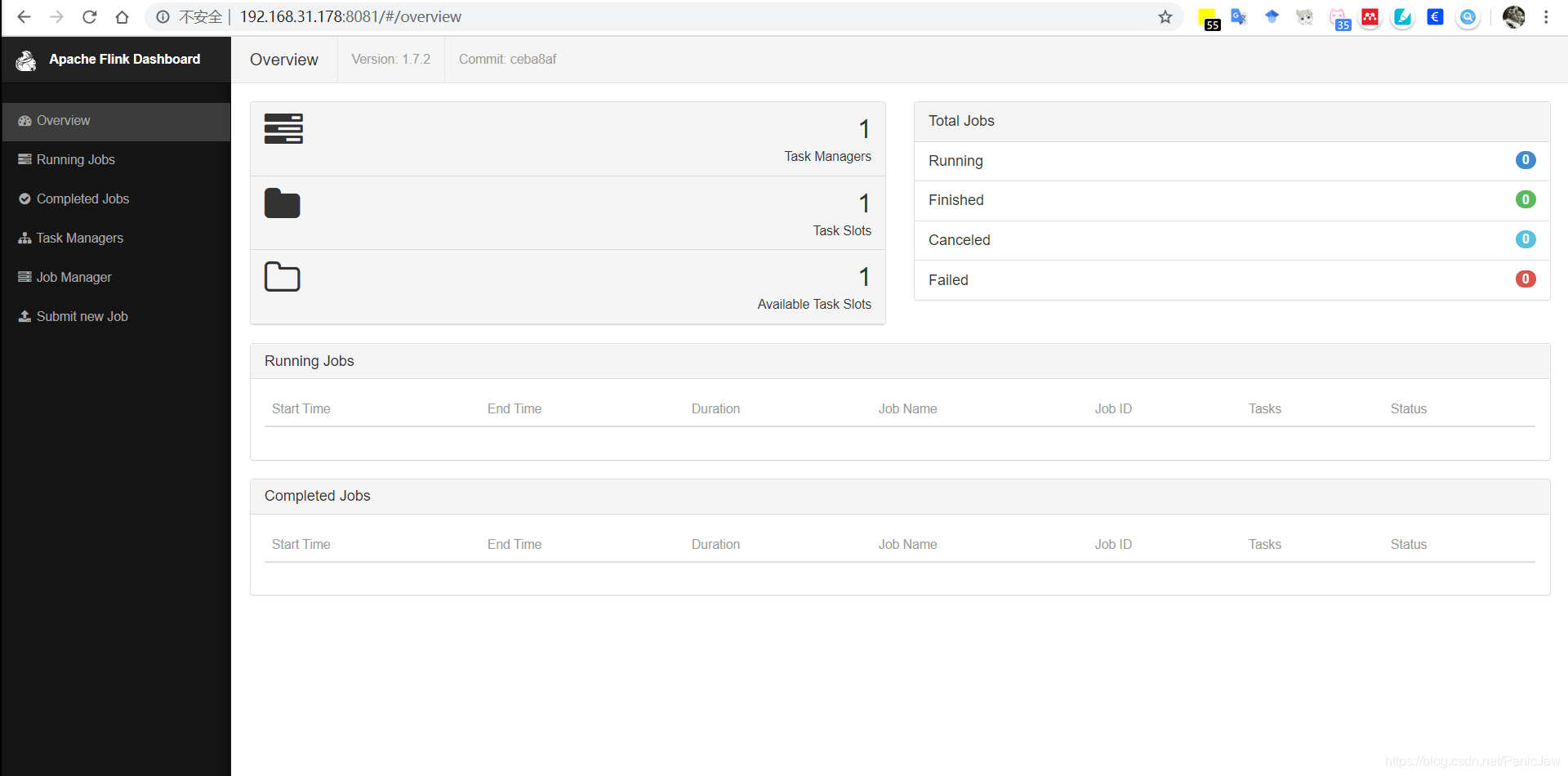
2。浏览器中输入 http://你的IP地址:8081,就能看到图形化界面
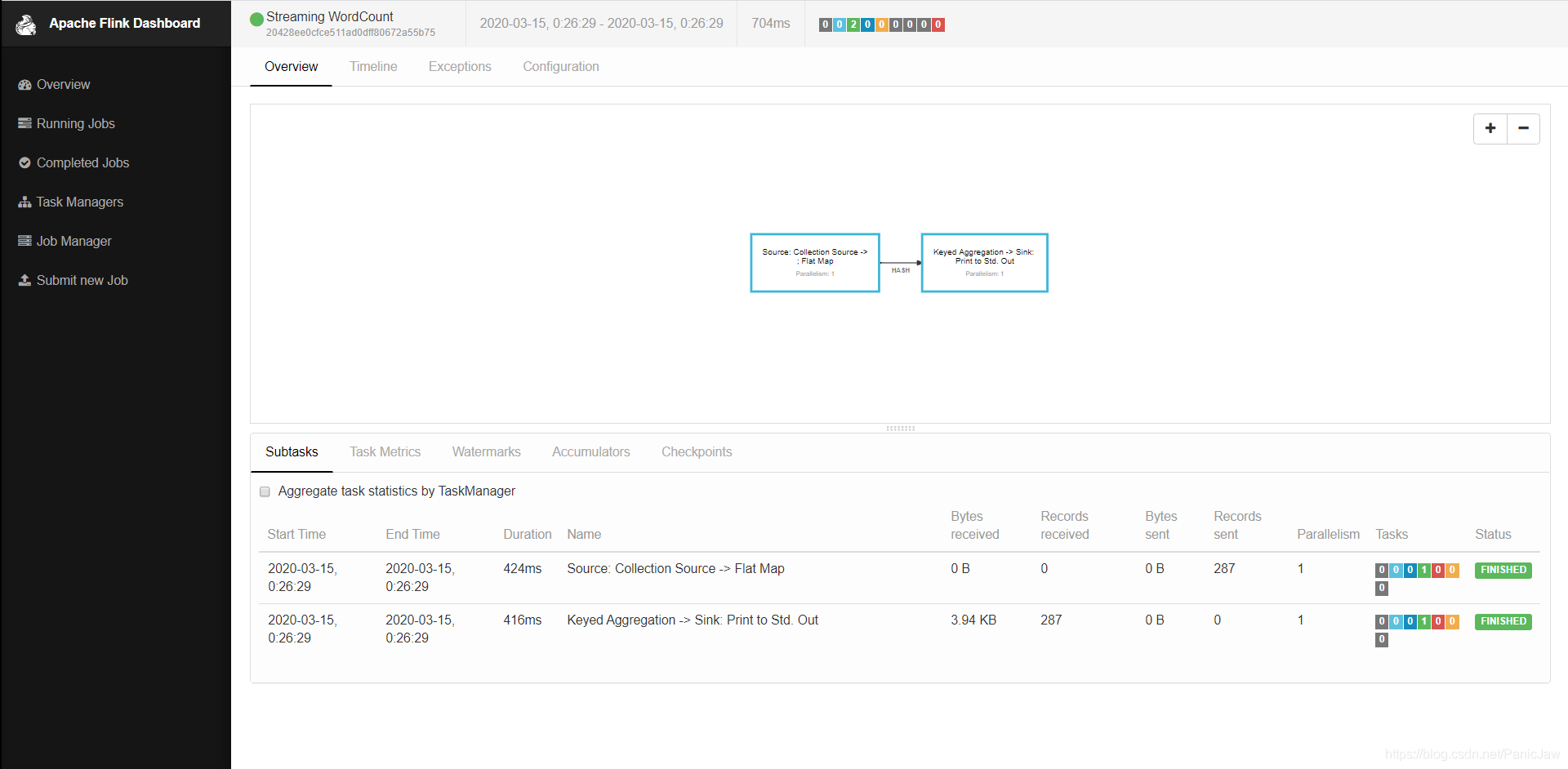
3.跑一个小例子,通过./bin/flink run命令跑一个 example 中的例子

查看日志中的结果

相应的控制台显示
最后关闭集群
关闭之前看到现有的进程

可以看到一个TaskManager,这个是Flink处理数据中的一个JVM进程,后续可以通过修改配置文件设置它其中的slot也就是线程的大小
关闭集群

查看进程,发现和Flink相关的处理进程结束了

