排序算法基本原理以及复杂度等知识点可跳转至该博客了解https://www.cnblogs.com/onepixel/p/7674659.html ,本博客主要对排序算法性能进行对比以及记录对比过程发现的问题
1. 插入排序和选择排序的对比
1.1 插入排序:从列表第一个元素 List[0] 开始每次取出列表一个元素,与该元素的前面元素进行比较,如果前面元素比该元素大,则把前面元素后移,直到前面元素不比该元素大,则插入。
插入排序示例
lst = [1,4,2,7,5]
----------------------第1次---------------------
取出lst[0] = 1; temp = lst[0]
前面没有元素,结束比较。
lst = [1,4,2,7,5]
----------------------第2次---------------------
取出lst[1] = 4; temp = lst[1]
lst[0] 不大于 temp, 不移动。
lst = [1,4,2,7,5]
----------------------第3次---------------------
取出lst[2] = 2; temp = lst[2]
lst[1] 大于 temp, lst[1]后移;
此时lst[2] = lst[1], 即lst[2] = 4。
lst[0] 不大于 temp, 不移动。
比较结束,将temp插入到列表中,lst[1] = temp。
lst = [1,2,4,7,5]
----------------------第4次---------------------
……
#插入排序示例代码
def insertsort(lst):
if lst:
if len(lst)<2:
return lst
L = lst[:]
for i in range(1, len(L)): #range()右边不闭合
temp = L[i]
j = i-1
while j>=0 and L[j] > temp:
L[j+1] = L[j]
j -= 1
if j<i-1:
L[j+1] = temp
return L
else:
return "List can't be none"1.2 选择排序:从列表第一个元素开始,每一次取一个出来和该列表的后续元素比较,找到最小值,然后将最小值和列表的取出值对换即可。
选择排序示例
lst = [1,4,2,7,5]
----------------------第1次---------------------
取出lst[0] = 1; minindex = 0
和lst[1], lst[2], lst[3], lst[4]比较;
没有比lst[0]更小的值,则minindex=0,不交换,结束
lst = [1,4,2,7,5]
----------------------第2次---------------------
取出lst[1] = 4; minindex=1
和lst[2],lst[3],lst[4]比较;
得到最小值lst[2]的索引为minindex=2;
将lst[1]和lst[minindex]交换,结束。
lst = [1,2,4,7,5]
----------------------第3次---------------------
取出lst[2] = 4; minindex=2
和lst[3],lst[4]比较;
没有比lst[2]更小的值,则minindex还是等于2,不交换,结束
lst = [1,2,4,7,5]
----------------------第4次---------------------
……
def selectsort(lst):
if lst:
if len(lst)<2:
return lst
L = lst[:]
for i in range(len(L)-1):
min = i
for j in range(len(L)-1, i, -1):
if L[j] < L[min]:
min = j
if min != i:
temp = L[i]
L[i] = L[min]
L[min] = temp
return L
else:
return "List can't be none" 1.3 插入排序和选择排序性能对比:我们都知道插入排序和选择排序的平均时间复杂度都是,而且选择排序每一轮循环都要遍历整个列表找出最小值,所以平均时间复杂度还是
。但是插入排序是和前面的数据排序,把比它小的数据往后移,这就值得我们注意了。如果列表本身有序程度较高,那么根本就不需要怎么移动,如[1,2,3,4],所以,时间复杂度最好为
。具体排序性能如下图。列表元素无序时,且长度为10,000,则选择排序比插入排序快一些,但处于同一数量级,区别不大。而列表元素有序时,插入排序只需0.002秒,而选择排序所用时间和处理无序列表时间差不多,都需要2.7秒左右。当我把列表长度拓展至40,000时,运行时间如下图。
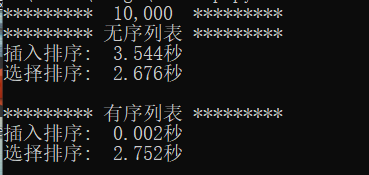

1.4 插入排序和选择排序总结:根据以上分析以及性能对比,对于随机序列,选择排序性能稍好,不管什么情况下,时间复杂度均为,此时插入排序与之处于同一数量级;对于有序程度较高的序列,插入排序有惊人的排序性能,复杂度可以为
,而且插入排序是依次比较,所以是稳定性排序算法(列表中相同两个元素不会因为排序算法而更换位置)。所以可以根据相应场景选择相应排序算法。
2. 归并排序和快速排序的对比
2.1 归并排序:将列表一分为二,再将两个子列表一分为二得到四个子列表,递归划分,最终得到单个元素的列表不再划分。此时再将子列表逐层合并,得到排序完成的列表,流程及代码如下。由二叉树知识可知,一n个元素的列表,最终划分为单个元素,那么总的层数有层,而每一层合并都需对n个元素进行n/2次比较,加上赋值操作,所以每一层的时间复杂度是
,总共有
,那么总的时间复杂度
,而且不管什么情况下,复杂度均为
。

def merge(left, right):
result = []
while len(left) and len(right):
if left[0] <= right[0]:
result.append(left.pop(0))
else:
result.append(right.pop(0))
if len(left):
result += left
elif len(right):
result += right
return result
def mergesort(lst):
if len(lst)<2:
return lst
middle = len(lst)//2
left = lst[:middle]
right = lst[middle:]
return merge(mergesort(left), mergesort(right)) 2.2 快速排序:选取关键字key(推荐取列表中间值,原因见附录),每一轮从列表末端判断是否有元素小于索引key的值,若有,更换值,并更新key。然后从列表前端判断是否有元素大于索引key的值,若有,更换值,并更新索引key,直至列表前端扫描索引和末端扫描索引重合,此时,索引key的左端都是比索引key的列表值小,索引key的右端都是比索引key的列表值大,分别对索引key的左右两端采取递归操作即可排序,排序示例如下,方便理解。平均情况下,key靠近整个列表的中值,那么每次扫描整个列表,然后将小于key放置左端,大于key放置右端,则依次划分,相当于归并排序的划分,层数接近层,每一层都要对n个元素进行比较,所以平均复杂度为
,但是当选取的key远离列表中值,那么以key为界,不能均分列表为两个子列表,比如比key小的列表为一个数,那么比key大的列表仍有n-2个数,相当于没有二分,复杂度和冒泡算法接近,退化为
。
快速排序
假设序列{xi}:5,3,7,6,4,1。
--------------------------------------------第1次------------------------------------------
此时,关键字索引为列表长度除以2,则key=3,则参考值ref=6,前端head的索引下标i=0,后端tail的索引下标j=5,从后往前找,第一个比6小的数是x5=1,因此序列为:5,3,7,1,4,6。
--------------------------------------------第2次------------------------------------------
更新i=0,j=4,key=5从前往后找,第一个比ref大的数是x2=7,因此序列为:5,3,6,1,4,7。
--------------------------------------------第3次------------------------------------------
更新i=3,j=4,key=2从j往前找,第一个比ref小的数是x4=4,因此:5,3,4,1,6,7。
--------------------------------------------第4次------------------------------------------
更新i=3,j=3,key=4, ref成为一条分界线,它之前的数都比它小,之后的数都比它大,对于前后两部分数,采用同样的方法来排序(递归)。
def quicksort1(Lp):
if len(Lp)<2:
return Lp
L = Lp[:]
key = len(L)//2
left = -1
right = len(L)
while left<right:
right -= 1 #下一轮开始都需要在上轮的值移动一步,不然又重复计算
while right>key and L[right]>=L[key]:
right -= 1
if right>key: #满足条件说明while循环是因为L[right]<L[key]而跳出,此时需要更新key
L[right], L[key] = L[key], L[right]
key = right
left += 1 #下一轮开始都需要在上轮的值移动一步,不然又重复计算
while left<key and L[left]<=L[key]:
left += 1
if key>left: #满足条件说明while循环是因为L[left]>L[key]而跳出,此时需要更新key
L[left], L[key] = L[key], L[left]
key = left
return quicksort1(L[:key]) + [L[key]] + quicksort1(L[key+1:])2.3 归并排序、快速排序和插入排序、选择排序的对比: 由下图运行过程可知,归并排序和快速排序的性能比插入排序和选择排序好的多。


2.4 归并排序和快速排序的对比: 由上述分析可知,快速排序会因为极端情况而复杂度上升,如果key值不够合适的话,会导致快速排序退化成冒泡排序,从而时间复杂度上升为。而归并排序的性能较为稳定,没有大的区别。如下图,可知快速排序对于有序列表处理效果良好。


由上图可知,归并排序速度没有快速排序快,博主了解到的原因是由于归并排序对内存的操作多于快速排序,那么为了探究是否该原因,博主将归并排序中比较合并列表的部分代码进行更改,然后修改代码如下。
原先合并比较函数
def merge(left, right):
result = []
while len(left) and len(right):
if left[0] <= right[0]:
result.append(left.pop(0))
else:
result.append(right.pop(0))
if len(left):
result += left
elif len(right):
result += right
return result
修改后合并比较函数,减少内存操作,仍然进行left列表和right列表比较,但不将比较结果保存至result列表中,result直接返回left和right中元素。
def mergeupdate(left, right):
ll = left[:]
rr = right[:]
result = []
while len(left) and len(right):
if left[0] <= right[0]:
left.pop(0)
else:
right.pop(0)
if len(ll):
result += ll
elif len(rr):
result += rr
return result代码运行效果如下


由图可以得到两点,①:对于有序程序较高的列表,快速排序运行效果比归并排序快得多,相差一个数量级,这也可从代码分析得到快速排序对有序列表的优势。②:对于无序列表快速排序比归并排序运行快2-3倍左右,而且通过修改归并排序的内存操作代码以及实验数据,可以验证:归并排序比快速排序慢的原因和内存操作有关。说明内存操作比较耗时间。
附录:
1. 快排的关键字key选择(尽量选取中间值)
key如果选两端的话,比如,设key=0此时若处理的列表为完全有序,如[1,2,3,4……999,1000……999999,1000000],那么程序就会占用超高内存,而且根本运算不了,而且按 计算的话,运算时间得以小时计算,直接退出,如下图。


原因是什么呢,对于有序列表,当选取的key为两端时,那么这个key的另一边全是大于或小于key的值,如此进行快排并没有实现key分区的作用,只是将key逐个拿走,如此就变为的时间复杂度,并且每次处理完列表长度几乎没有变化,那么内存逐渐消耗,极占据内存。
2. 如果提示超出递归深度,添加如下代码,拓展递归深度
import sys
sys.setrecursionlimit(10000000)3. python计算代码运行时间
import time
time.process_time() #不计算代码中的延时,单位是秒,通过两次差值得到中间代码块运行时长
time.perf_counter() #包括代码中的延时,单位是秒,通过两次差值得到中间代码块运行时长 4. 列表作为参数,函数会修改该列表的值导致主程序的列表值也随之改变,测试代码如下。
real_a = [5]
print('主程序中执行函数前实参值:', real_a)
def val(vir_a):
vir_a.append(3)
print('函数内形参修改后的值:', vir_a)
val(real_a)
print('主程序中执行函数后实参值:', real_a)运行结果如下

导致该结果的是因为python中,列表和字典是mutuable类型,数字、字符串以及元组是immutuable类型,处理数字时,实参则不会被函数修改,代码及结果如下。
real_a = 5
print('主程序中执行函数前实参值:', real_a)
def val(vir_a):
vir_a += 5
print('函数内形参修改后的值:', vir_a)
val(real_a)
print('主程序中执行函数后实参值:', real_a)
所以当传递列表或字典对象时,实际传的是对象地址,所以函数可以修改参数中列表或字典的值,即函数修改形参时会更改实参,因此我们处理列表或字典时,可以先拷贝一份,在拷贝的那一份进行处理,代码及结果如下。
real_a = [5]
print('主程序中执行函数前实参值:', real_a)
def val(vir_a):
vir_b = vir_a[:]
vir_b.append(3)
print('函数内形参修改后的值:', vir_b)
val(real_a)
print('主程序中执行函数后实参值:', real_a)