一、ik分词器是什么?
我们都知道,在平时使用搜索引擎搜索东西的时候,我们自己输入的关键字,有可能会被分隔成好几个字或者词,最常见的比如我们使用百度搜索关键字的话,那么所有与该关键字相关的都会显示出来,并把出现关键字的文档标红,而且单条记录可能出现多个标红,如图所示
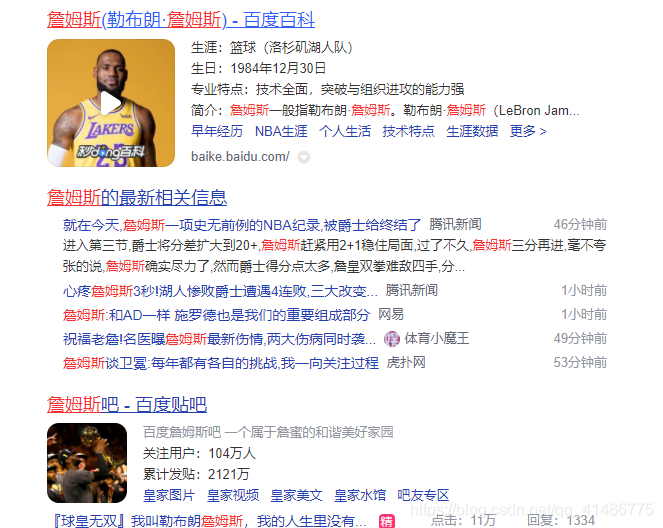
或者像这样的。,但凡与你的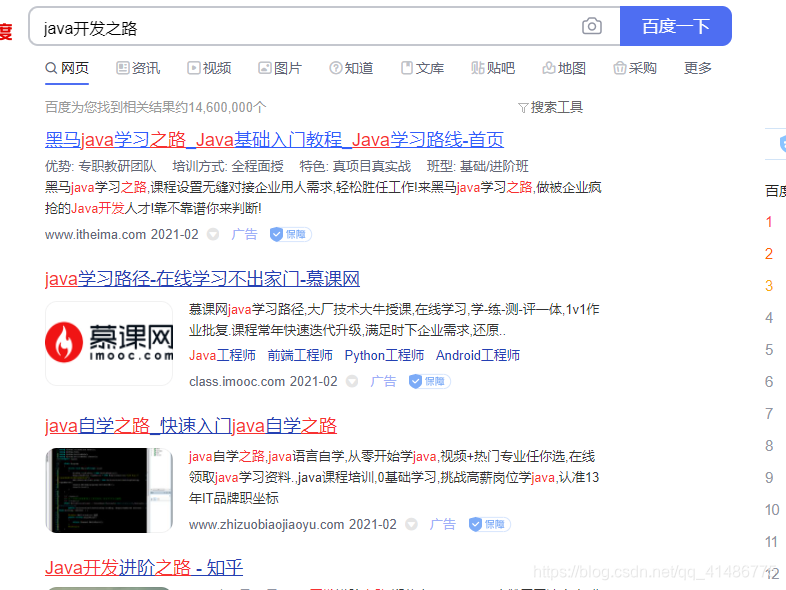
或者像这样的,但凡文档当中出现了一个或者多个与搜索的关键相匹配的文本,都会被标红。
于是乎,今天我们的主角闪耀登场了,他就是elasticsearch中的ik分词器
二、使用步骤
1.开启服务
在使用ik分词器之前,我们需要首先开启elasticsearch服务,然后为了演示ik分词器的展示效果,还需要下载kibana,用于操作并且查看elasticsearch里面的数据。
elasticsearch下载地址
kibana下载地址
下载完成后,我把他们放在同一个目录里面了。

接下来进入elasticsearch的bin目录,单击运行,也是es就启动起来了。
然后开启kibana服务,并且单击运行,kibana服务就启动起来了。
验证
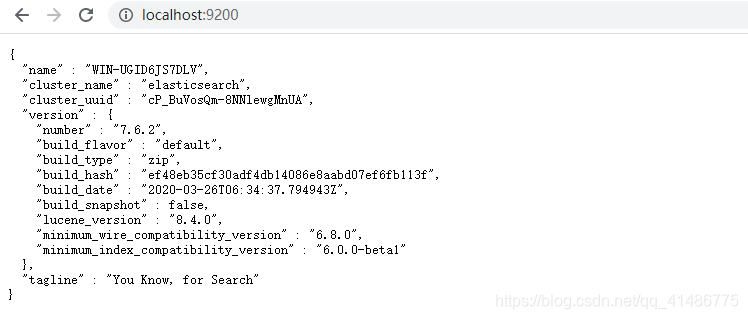
浏览器输入http://localhost:9200/验证是否开启了elasticsearch服务。
浏览器输入http://localhost:5601看看是否能够进入kibana页面
支持准备工作就已经做好了,那么接下来我们演示一下如何进行ik分词器的操作,以及如何自定义ik分词器,以能够实现我们想要的功能。
2.ik分词器演示
在ik分词器有两种模式,那么他们之间有什么样的区别呢?我们通过代码来演示一下。
- ik_smart
- ik_max_word
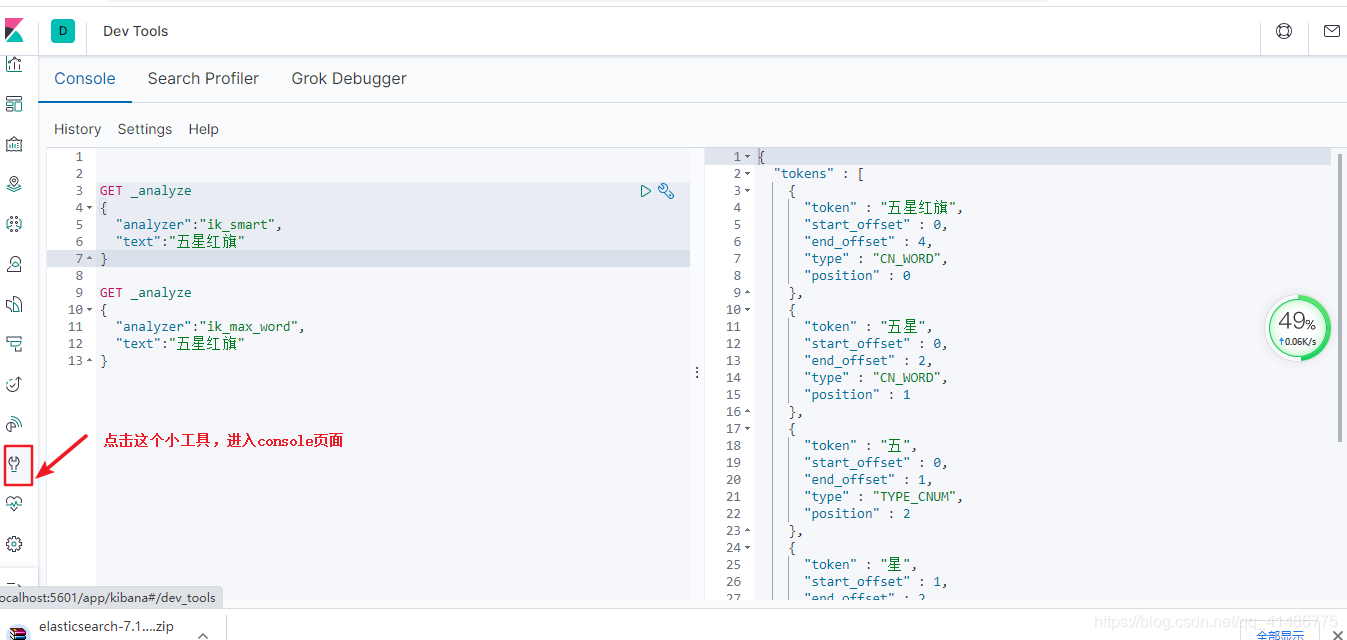
首先演示一下ik_smart,在屏幕左边输入以下命令。
GET _analyze
{
"analyzer":"ik_smart",
"text":"五星红旗"
}
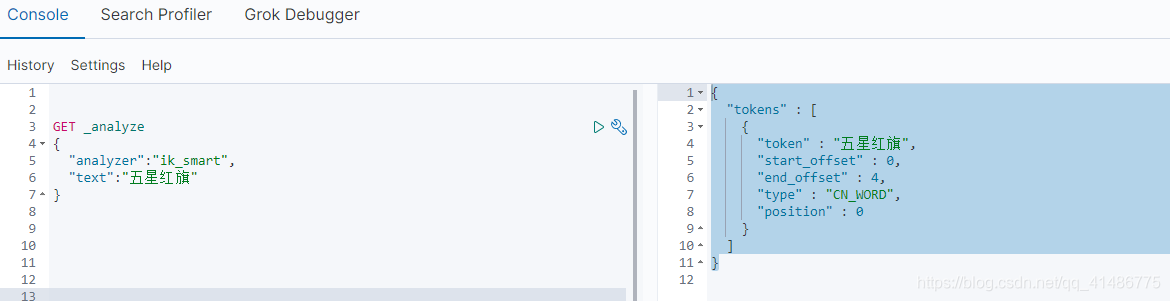
右边就能够查询到对应的结果。
{
"tokens" : [
{
"token" : "五星红旗",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 0
}
]
}
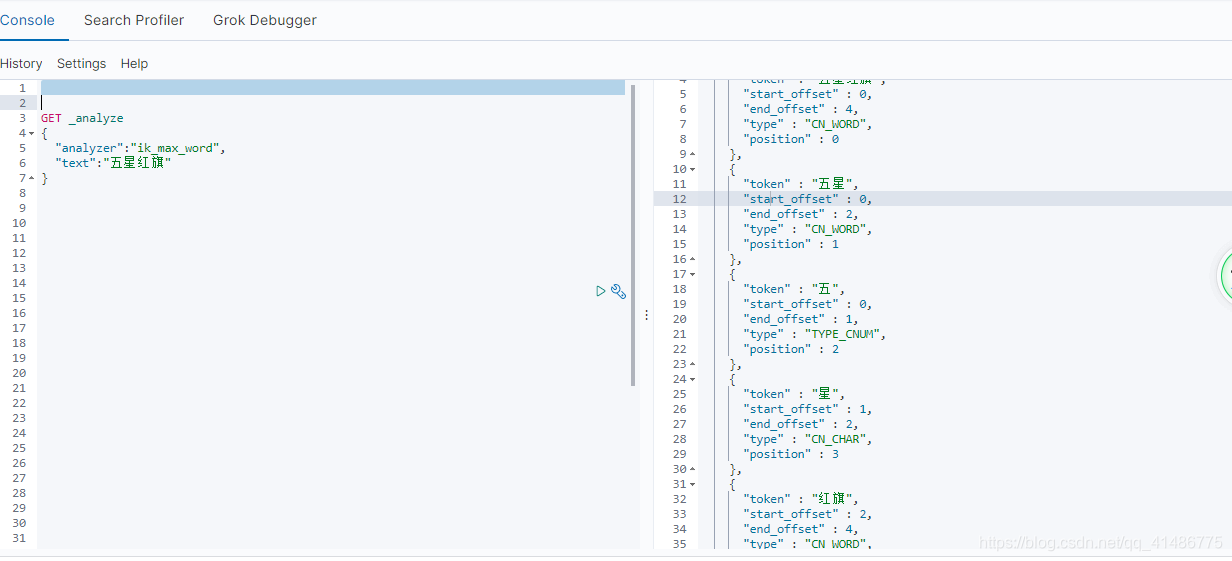
那我们使用ik_max_smart又会怎么样呢?
GET _analyze
{
"analyzer":"ik_max_word",
"text":"五星红旗"
}
返回结果如下,这就很明显了,elasticsearch会把所有可能的结果都显示出来。

{
"tokens" : [
{
"token" : "五星红旗",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "五星",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "五",
"start_offset" : 0,
"end_offset" : 1,
"type" : "TYPE_CNUM",
"position" : 2
},
{
"token" : "星",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "红旗",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 4
}
]
}
那么问题来了,我现在想要实现另外一种功能,假如我把某个人的名字输入进去,然后使用ik_max_smart模式来运行的话,它是不是会把名字也给拆开呢?(实际上我们并不想要这样的效果,我们想要的是不把名字分开)
GET _analyze
{
"analyzer":"ik_max_word",
"text":"廖晨威大四了"
}
{
"tokens" : [
{
"token" : "廖",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "晨",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "威",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "大四",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "四",
"start_offset" : 4,
"end_offset" : 5,
"type" : "TYPE_CNUM",
"position" : 4
},
{
"token" : "了",
"start_offset" : 5,
"end_offset" : 6,
"type" : "CN_CHAR",
"position" : 5
}
]
}
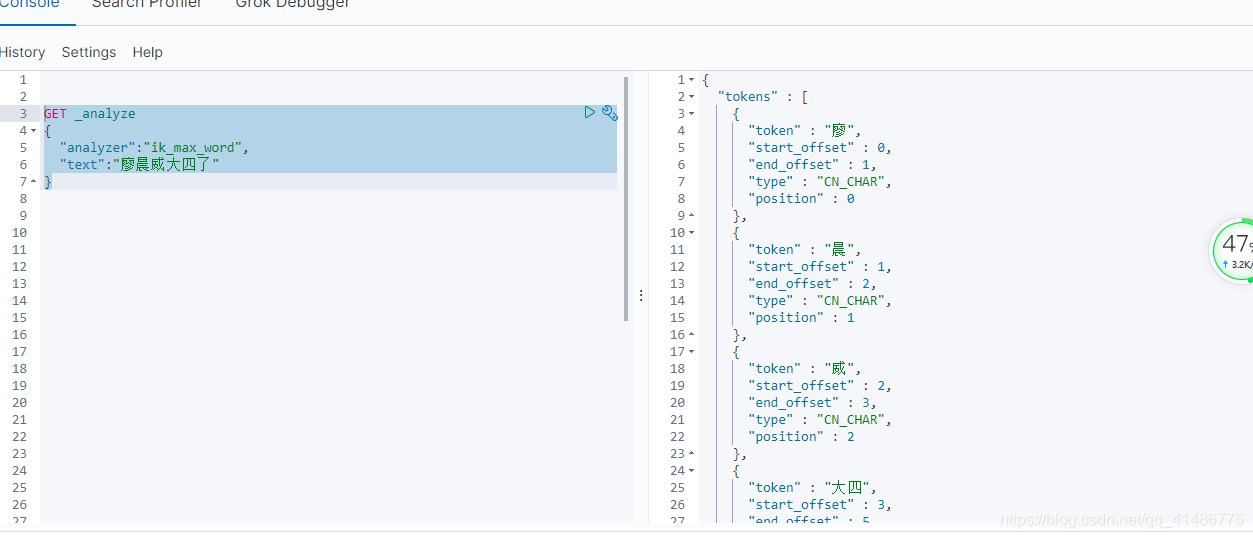
那么这个问题如何去解决呢?我们想要名字可以不拆开,其实很简单,我们只需要在elasticsearch的ik分词器插件当中加入我们想要达到的效果即可。
对应的目录如下
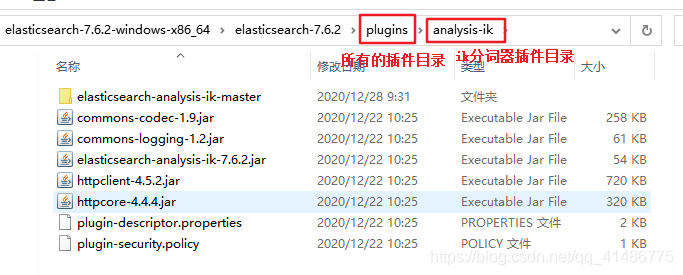
在下面的目录里面新建一个后缀为.dic的文件,并且往这个文件里面加入自己的名字(廖晨威),然后在IKAnalyzer.cfg.xml配置文件当中加入这个.dic文件即可。
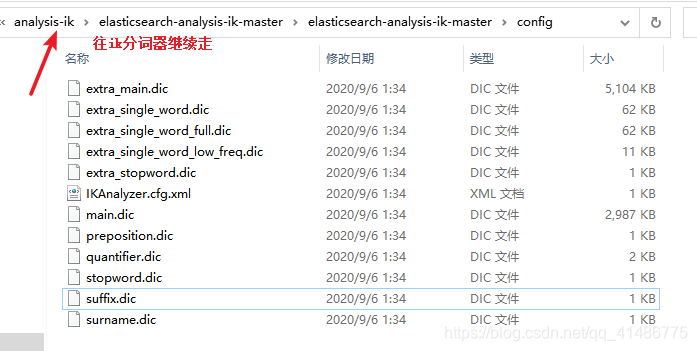


至此,扩展功能已经完成了,那么接下来我们需要重新开启一下es服务。
总结
至此,ik分词器的讲解已经完毕了,如果以后我们需要自定义一些自己需要的词汇,为了在搜索的时候,别把关键字拆开,那么就可以自定义扩展词汇。嘿嘿,原来如此简单!