摘要
我们提出了一种新的,生物学上可行的监督突触学习规则,使神经元能够有效地学习广泛的决策规则,就是把信息嵌入在脉冲的时空结构中,而不是简单的平均脉冲发射频率。
神经元可以实现的随机时空模式的分类数量是其突触数量的几倍。
我们不再使用单神经元,而是使用多神经元。
我们的工作证明了神经系统学习解码嵌入在脉冲同步分布模式中的信息的高能力。
介绍
解密编码原则,神经元所代表的和过程信息已经困扰了大脑科学研究者半个世纪。
通常情况下,神经元表示信息通过特闷的平均脉冲发放率。然而,实际上,听觉、嗅觉、触觉,脉冲发生对应于一个刺激,可以使精确的时间点,或者是其他相同神经元的动作电位。
这些数据表示,脉冲序列的时间结构扮演了一个重要的组成部分,对于神经元对于刺激的反应。例如,对于人类的嗅觉系统,动作电位的延迟,在个人嗅觉传入上携带者重要信息,就是外部强度的方向和表面的方向。脉冲延迟编码也被建议在嗅觉系统中。
在视网膜中检测到多神经元同步事件,并具有不同于单个神经元放电速率预测的感受野。实际上,一些研究者声称,在特定情况下,时间神经元编码提供了一个显著的计算优势,相对于速率编码。
但也有一些人声称,时间编码不太好使,因为它们解码的复杂性。
这个实验解决了两个重要的和代表性的问题。首先,通过突触可塑性的机制,神经元可以学习到区分不同输入脉冲的时空序列的模型吗?
也就是说,神经元怎么做,才能够学习到读出时间编码所携带的信息?
第二,对于嵌入在输入脉冲的时空特征,神经元用什么可以计算出它们的响应?
大多数存在的监督学习的计算模型,是基于脉冲速率的模型,而且没用应用时间决定的准则,这个缺点已经阻断理论和实践上的优势,在理解脉冲时间的所扮演的角色,在神经元信息处理和学习中。
为了跳过这个gap,我们已经设计了一个新的,生物学的貌似真实的监督学习模型,temporton,对于译码镶嵌在脉冲时空序列模型。通过使用tempotron学习,我们展示了,一个LIF神经元可以学习分类一系列输入的类别。这包括分类信息不包括。。。
但是包括单个神经元的延迟编码或者成对,或者更高阶的同步模式。
结论
tempotron学习规则
我们的神经元模型包括LIF模型,被指数衰减的突触电流所驱动,这些电流是N个突触传入。亚阈值膜电压是突触后电位的加权和(PSP),从全部的输入脉冲中:
V ( t ) = ∑ i ω i ∑ t i K ( t − t i ) + V r e s t V(t)=\sum_i\omega_i\sum_{t_i}K(t-t_i)+V_{rest} V(t)=∑iωi∑tiK(t−ti)+Vrest
在这里, t i t_i ti代表第i个脉冲的时间, K ( t − t i ) K(t-t_i) K(t−ti)是标准化后的PSP
更准确来说,就是
K ( t − t i ) = V 0 ( e x p [ − ( t − t i ) / τ ] − e x p [ − ( t − t i ) / τ s ] ) K(t-t_i)=V_0(exp[-(t-t_i)/\tau]-exp[-(t-t_i)/\tau_s]) K(t−ti)=V0(exp[−(t−ti)/τ]−exp[−(t−ti)/τs])
参数 τ \tau τ和 τ s \tau_s τs分别表示常量膜电压和突触电流的延迟时间。当 V ( t ) V(t) V(t)超过放电阈值时,电压经历一个平滑的复位到 V r e s t V_{rest} Vrest
在分类任务中,每个输入模型属于两类中的一个,“+”或者“-”,它的任务就是,输入是+的时候,发放至少一个脉冲,输入是-的时候,保持静默。
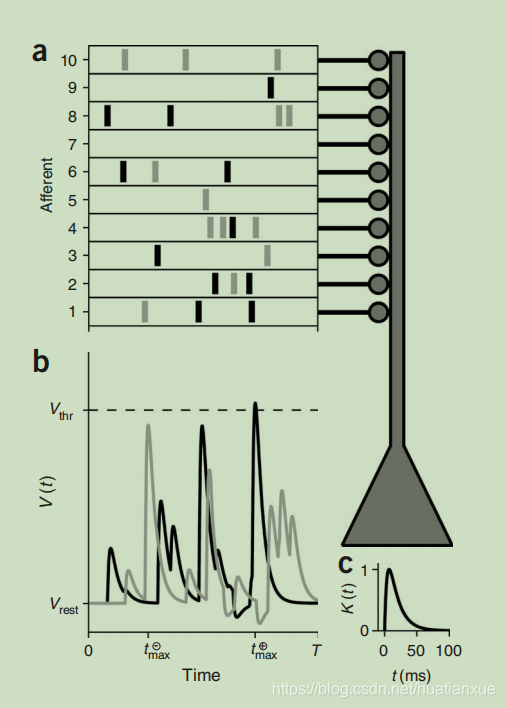
上图中,黑色的代表+,灰色的代表-
V t h r V_{thr} Vthr表示的是阈值电压, t m a x − t_{max}^- tmax−表示的是负号中最大的, t m a x + t_{max}^+ tmax+代表是正号中最大的,我们可以看到当: t m a x − < V t h r < t m a x − t_{max}^-<V_{thr}<t_{max}^- tmax−<Vthr<tmax−时,是可以正确分类的,**也就是说:这时候只有负的,那么没有脉冲,正的,那么有脉冲,**这是由10个突触前电位决定的。
c,突触后激活核函数 K ( t ) K(t) K(t)的膜时间常数为 τ = 15 m s \tau=15ms τ=15ms 而且突触时间常数 τ s = τ / 4 \tau_s=\tau/4 τs=τ/4.这篇文章中所有的其他图,输入到达时间都是0到500ms
神经元通过调整突触权重来学习任务,当错误发生的时候。
神经元使用一下的规则:如果在一个+模式中,没有输出脉冲的话, 每个突触权重 ω i \omega_i ωi将会被增加,通过以下的方式
Δ ω i = λ ∑ t i < t m a x K ( t m a x − t i ) \Delta\omega_i=\lambda\sum_{t_i<t_{max}}K(t_{max}-t_i) Δωi=λ∑ti<tmaxK(tmax−ti)
上式中, t m a x t_{max} tmax表示突触后电压到达最大值的时间。常量 λ > 0 \lambda>0 λ>0用来你指定每一个输入脉冲,最大值得突触更新。相反,如果一个输出显示出对应-模式,突触权重应该减少 Δ ω i \Delta\omega_i Δωi
tempotron神经元实现了“梯度下降”,最小化代价函数,这个代价函数是这样一个总量,错误产生输出模式的最大电压和放电阈值之间的最大值。例如,对于每一个+的模式,但是没有产生脉冲的情况而言,代价函数就是 V t h r − V ( t m a x ) V_{thr}-V(t_{max}) Vthr−V(tmax).对于每一个-模式,但是产生了脉冲的情况而言,代价函数是 V ( t m a x ) − V t h r V(t_{max})-V_{thr} V(tmax)−Vthr
‘我在想,代价函数一般不是正数么?应该是有个平方按才对呀’
在梯度学习中,突触权重的变化是 成正比的 和代价函数的负导数。
通过使用这个规则,我们研究了LIF神经元去学习分类任务,关于脉冲模式,模拟了一个尖峰延迟场景。图三。和尖峰延时同步代码。
学习分类延时模式
在我们第一个测试,关于tempotron的能力去分辨脉冲时空特性中,我们评估了它的表现,关于分类单个脉冲群体。
这个测试包含了p个脉冲的模式,每个随机分配为+或者-。在每个模式中,每个传入的突触fire在固定时间发射一次,随机选择0-500ms的均匀分布。afferent,传入的,向心的。