在上一节训练手写训练集的模型中,每次运行,得到的模型参数都不同?这是什么原因造成的呢?
答:一方面是因为神经网络的损失函数是一个复杂的非凸函数,使用梯度下降法只能是尽可能的去逼近全局最小值点,另一方面由于每次训练时批次中的数据元素是随机的, 到达最小值点的路径也不同,所以每次运行的结果都不同, 但相差不大。
那如何保存这些训练好的模型参数呢?
保存训练好的模型参数
可以使用 Sequential 模型中的 save_weights 函数,

这样下次运行时,就可以直接加载这些模型参数既可。
参数 filepath 用来指定文件路径,默认为当前文件所在路径。模型参数可以被保存为 HDF5 格式或者 TensorFlow 的 SaveModel 格式。
当文件名的后缀为 ** .h5 或 ** .keras 时,并且 save_format = None 时,模型参数就被保存为 HDF5 格式。

HDF5 格式是

的简称。它是一种二进制的文件格式,可以看做是一个包含 group 和 dataset 的容器。
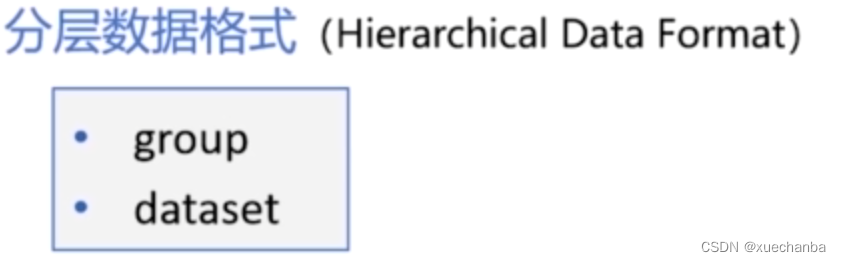
其中,group 类似于文件夹,文件夹的下面可以创建子文件夹,子文件夹下可以存放数据。dataset 是具体的数据,类似于 NumPy 中的多维数组。使用 .h5 文件来存放数据效率很高,非常适合存储大量的数据。因此,常用来保存多维数据和图像。
如果在文件名中没有指明文件后缀,那么模型参数就会被保存为 TensorFlow 的 SaveModel 格式。 为了使程序更加清晰,在保存为这种格式时,建议把参数 save_format 设置为 “tf”,

SaveModel 格式是 TensorFlow 中特有的一种序列化文件格式。

采用这种格式时,参数信息不是被保存在一个文件中,而是需要保存在多个文件中。
例如,执行下图中语句:

在当前目录下,会出现四个文件,

其中,checkpoint 文件是检查点文件,保存模型的相关信息。
而 .data 文件则用来保存所有的可训练变量,也就是模型参数的值,
.index 文件保存变量关键字和值之间的对应关系。
参数 overwrite 表示当前指定写入的文件已经存在时,是否直接覆盖原来的数据,默认为 True 。如果将这个参数设置为 False ,那么就会出现提示,
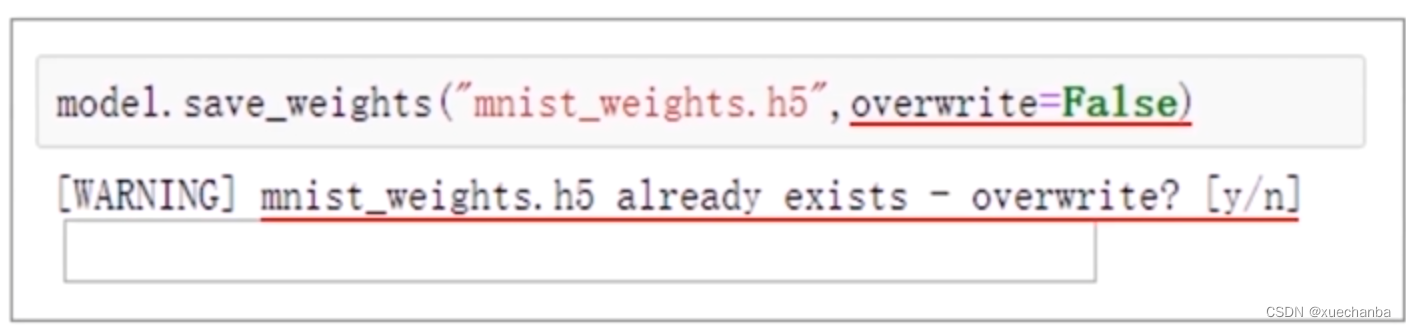
文件已经存在,是否覆盖。
加载训练好的模型参数
在保存模型参数之后,下次运行时就可以使用 load_weights 函数来直接从文件中读取和加载模型参数了。

实例:使用 Sequential 模型实现训练好的手写数字识别参数的保存和加载
# 一:导入库函数
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
# 二:参数配置
# 图片显示中文字体的配置
plt.rcParams["font.family"] = "SimHei", "sans-serif"
# GPU显存的分配配置
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(gpus[0], True)
# 三:加载数据
mnist = tf.keras.datasets.mnist
(train_x, train_y), (test_x, test_y) = mnist.load_data()
print(train_x.shape) # (60000, 28, 28)
# 每条数据的属性就是图片中各个像素的灰度值, 存放在一个 28 * 28 的二维数组中
print(train_y.shape) # (60000,)
print(test_x.shape) # (10000, 28, 28)
print(test_y.shape) # (10000,)
print(type(train_x), type(train_x))
# <class 'numpy.ndarray'> <class 'numpy.ndarray'>
# 每条数据的属性就是图片中各个像素的灰度值, 存放在一个
print(type(test_x), type(test_y))
# <class 'numpy.ndarray'> <class 'numpy.ndarray'>
print((train_x.min(), train_x.max()))
print((test_y.min(), test_y.max()))
# 每个元素的灰度值在(0, 255)之间
# 数据的标签值在(0, 9)之间
# 四:数据预处理
"""
# 在输入神经网络时, 需要把每条数据的属性从 28 * 28 的二维数组转化为长度为 784 的一维数组
# 可以使用 reshape 方法进行转换
X_train = train_x.reshape((60000, 28*28))
X_test = test_x.reshape((10000, 28*28))
print(X_train.shape)
print(X_test.shape)
# 但是这一步也可以省略, 在这里保持输入数据的形状不变,
# 在后面创建神经网络时增加一个 Flatten() 层来实现输入数据维度的变化.(通过 tf.keras.layers.Flatten()函数来实现)
"""
# 为了加快迭代速度, 还要对属性进行归一化, 使其取值范围在 (0, 1)之间
# 与此同时, 把它转换为Tensor张量, 数据类型是 32 位的浮点数.
# 把标签值也转换为Tensor张量,数据类型是 8 位的整型数.
X_train, X_test = tf.cast(train_x / 255.0, tf.float32), tf.cast(test_x / 255.0, tf.float32)
y_train, y_test = tf.cast(train_y, tf.int16), tf.cast(test_y, tf.int16)
# 现在, 数据已经准备好了, 可以搭建模型了
# 五:搭建模型
# 在之前, 都是使用低阶 API 来训练和测试模型, 在这里直接使用 tf.keras.Sequential 来建立和训练模型
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28, 28)))
# 这里首先添加一个 Flatten 层, 说明输入层的形状, Flatten 层不进行计算, 只是完成形状转换, 把输入的属性拉直, 变成一维数组
# 这样在数据预处理阶段, 不用改变输入数据的形状, 隐含层中也不用再说明输入数据, 各层的结构更加清晰
model.add(tf.keras.layers.Dense(128, activation="relu"))
# 这里再添加隐含层, 隐含层是全连接层, 其中有 128 个结点, 激活函数采用 relu 函数
model.add(tf.keras.layers.Dense(10, activation="softmax"))
# 最后, 添加输出层, 输出层也是全连接层, 其中有 10 个结点, 激活函数采用 softmax 函数
# 六:查看模型结构和信息
# 下面使用 summary() 方法来查看模型结构和参数信息
print(model.summary())
"""
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0 可以看出输入层中共 784 个结点, 没有参数
_________________________________________________________________
dense (Dense) (None, 128) 100480 可以看出隐含层中共 128 个结点, 100480个参数
_________________________________________________________________
dense_1 (Dense) (None, 10) 1290 可以看出输出层中共有 10 个结点, 1290个参数
=================================================================
Total params: 101,770 所有参数为 101770 , 和前面计算的结果一致
Trainable params: 101,770 可训练参数为 101770
Non-trainable params: 0
_________________________________________________________________
None
"""
# 七:配置模型的训练方法
model.compile(loss='sparse_categorical_crossentropy',
# 损失函数使用稀疏交叉熵损失函数,
optimizer='adam', # 这里可以不用设置 adam 算法中的参数,
# 因为 keras 中已经使用常用的公开参数作为他们的默认值
# 在大多数情况下都可以得到比较好的结果
metrics=['sparse_categorical_accuracy'] # 在 mnist 手写数字数据集中
# 标签值是 0 ~ 9 的数字, 而神经网络的输出是一组概率分布, 类似独热编码的形式
# 所以使用稀疏准确率评价函数
)
# 八:训练模型
model.fit(X_train, y_train, batch_size=64, epochs=5, validation_split=0.2)
"""
750/750 [==============================] - 2s 2ms/step - loss: 0.3316 - sparse_categorical_accuracy: 0.9080
- val_loss: 0.1854 - val_sparse_categorical_accuracy: 0.9490
Epoch 2/5
750/750 [==============================] - 1s 2ms/step - loss: 0.1542 - sparse_categorical_accuracy: 0.9557
- val_loss: 0.1362 - val_sparse_categorical_accuracy: 0.9625
Epoch 3/5
750/750 [==============================] - 1s 2ms/step - loss: 0.1083 - sparse_categorical_accuracy: 0.9684
- val_loss: 0.1133 - val_sparse_categorical_accuracy: 0.9662
Epoch 4/5
750/750 [==============================] - 1s 2ms/step - loss: 0.0816 - sparse_categorical_accuracy: 0.9764
- val_loss: 0.1070 - val_sparse_categorical_accuracy: 0.9683
Epoch 5/5
750/750 [==============================] - 1s 2ms/step - loss: 0.0640 - sparse_categorical_accuracy: 0.9817
- val_loss: 0.0891 - val_sparse_categorical_accuracy: 0.9740
48000 / 64 = 750,由于批次中的数据元素是随机的,所以每次运行的结果都不同,但相差不大
"""
# 九:评估模型
# 这里使用 mnist 本身的测试集来评估模型
# verbose=2 表示输出进度条进度
model.evaluate(X_test, y_test, batch_size=64, verbose=2)
"""
157/157 - 0s - loss: 0.0831 - sparse_categorical_accuracy: 0.9753
可以看出评估结果和训练结束时差不多, 说明模型具备比较好的泛化能力
"""
# 十:保存模型参数
# 如果对这次训练结果满意, 就可以使用 save_weights 方法来保存模型参数
model.save_weights("mnist_weights.h5")
保存结果如下,
下面,再来说一说如何加载模型参数。
在加载完数据、对数据处理完之后、说明(搭建)神经网络的结构和训练方法之后,无需重新训练模型。
# 一:导入库函数
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
# 二:参数配置
# 图片显示中文字体的配置
plt.rcParams["font.family"] = "SimHei", "sans-serif"
# GPU显存的分配配置
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(gpus[0], True)
# 三:加载数据
mnist = tf.keras.datasets.mnist
(train_x, train_y), (test_x, test_y) = mnist.load_data()
# 四:数据预处理
# 为了加快迭代速度, 还要对属性进行归一化, 使其取值范围在 (0, 1)之间
# 与此同时, 把它转换为Tensor张量, 数据类型是 32 位的浮点数.
# 把标签值也转换为Tensor张量,数据类型是 8 位的整型数.
X_train, X_test = tf.cast(train_x / 255.0, tf.float32), tf.cast(test_x / 255.0, tf.float32)
y_train, y_test = tf.cast(train_y, tf.int16), tf.cast(test_y, tf.int16)
# 现在, 数据已经准备好了, 可以搭建模型了
# 五:搭建模型
# 在之前, 都是使用低阶 API 来训练和测试模型, 在这里直接使用 tf.keras.Sequential 来建立和训练模型
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28, 28)))
# 这里首先添加一个 Flatten 层, 说明输入层的形状, Flatten 层不进行计算, 只是完成形状转换, 把输入的属性拉直, 变成一维数组
# 这样在数据预处理阶段, 不用改变输入数据的形状, 隐含层中也不用再说明输入数据, 各层的结构更加清晰
model.add(tf.keras.layers.Dense(128, activation="relu"))
# 这里再添加隐含层, 隐含层是全连接层, 其中有 128 个结点, 激活函数采用 relu 函数
model.add(tf.keras.layers.Dense(10, activation="softmax"))
# 最后, 添加输出层, 输出层也是全连接层, 其中有 10 个结点, 激活函数采用 softmax 函数
# 六:配置模型的训练方法
model.compile(loss='sparse_categorical_crossentropy',
# 损失函数使用稀疏交叉熵损失函数,
optimizer='adam', # 这里可以不用设置 adam 算法中的参数,
# 因为 keras 中已经使用常用的公开参数作为他们的默认值
# 在大多数情况下都可以得到比较好的结果
metrics=['sparse_categorical_accuracy'] # 在 mnist 手写数字数据集中
# 标签值是 0 ~ 9 的数字, 而神经网络的输出是一组概率分布, 类似独热编码的形式
# 所以使用稀疏准确率评价函数
)
# 七:加载模型参数
model.load_weights("mnist_weights.h5")
# 八:使用测试集中的数据来评估模型性能
# 这里使用 mnist 本身的测试集来评估模型
# verbose=2 表示输出进度条进度
model.evaluate(X_test, y_test, batch_size=64, verbose=2)
"""
157/157 - 0s - loss: 0.0831 - sparse_categorical_accuracy: 0.9753
和保存之前的评估结果一样
"""
# 十:应用模型 -- 预测
# 下面再随机取出测试集中的任意4个数据进行识别
plt.figure()
for i in range(4):
num = np.random.randint(1, 10000)
plt.subplot(1, 4, i+1)
plt.axis("off")
plt.imshow(test_x[num], cmap="gray")
y_pred = np.argmax(model.predict(tf.reshape(X_test[num], (1, 28, 28))))
plt.title("y= "+str(test_y[num]) + "\n" + "y_pred=" + str(y_pred))
plt.suptitle("随机取出测试集中的任意4个数据进行识别", fontsize=20, color="red", backgroundcolor="yellow")
plt.show()
运行结果如下,

需要注意的是,

并没有保存网络的结构和训练方法,因此,

否则就会出现模型没有定义的错误提示,见下图。

也就是说使用

替代了原来的

从而不用再重新训练模型了,但程序中其他部分不变。
如果要将整个神经网络的所有信息全都保存下来,可以使用 save 方法。
save 方法将整个神经网络的所有信息全都保存下来

它可以将神经网络的结构、模型参数、配置信息(优化器、损失函数等)以及优化器当前的状态信息等全部都完整的保存起来,下次使用时,可以直接加载整个模型。
参数 include_optimizer 表示是否存储优化器当前的状态,默认为 True ,当模型很复杂,数据集很大时,训练时间可能非常的长,需要几个小时甚至几天的时间,在这个过程中,也许会由于各种原因,我们不得不暂时终止训练,关闭训练程序,甚至关闭计算机,那么就需要保存优化器中所有参数的当前状态,下次重新运行时,就可以直接接着上一次断点位置继续训练下去。
使用 save 方法保存模型时,也可以存储为 HDF5 格式或者 SaveModel 格式,参数要求与使用 save_weights 函数一致。
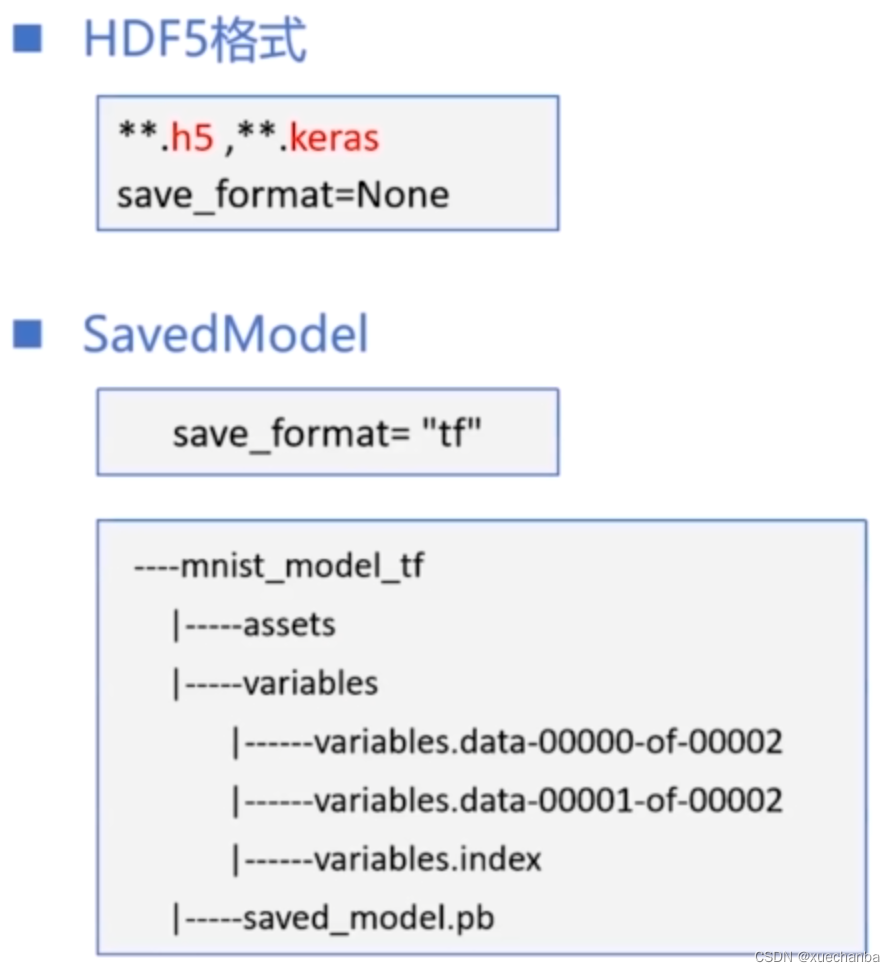
上图是保存为 SaveModel 格式后的文件夹结构,它包含两个子文件夹和一个文件,
其中的 assets 文件夹用来保存一些辅助的资源文件,
variables 文件夹用来保存模型参数,可以发现这就是使用 save_weights 函数保存为SaveModel 格式后的三个文件。
而文件 saved_model.pb 是用来保存计算图的。
tf.keras.models方法加载整个模型
在保存模型之后,再需要使用它时,可以使用

来加载整个模型。
实例:使用 Sequential 模型实现手写数字识别的整个模型参数的保存和加载
# 一:导入库函数
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
# 二:参数配置
# 图片显示中文字体的配置
plt.rcParams["font.family"] = "SimHei", "sans-serif"
# GPU显存的分配配置
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(gpus[0], True)
# 三:加载数据
mnist = tf.keras.datasets.mnist
(train_x, train_y), (test_x, test_y) = mnist.load_data()
print(train_x.shape) # (60000, 28, 28)
# 每条数据的属性就是图片中各个像素的灰度值, 存放在一个 28 * 28 的二维数组中
print(train_y.shape) # (60000,)
print(test_x.shape) # (10000, 28, 28)
print(test_y.shape) # (10000,)
print(type(train_x), type(train_x))
# <class 'numpy.ndarray'> <class 'numpy.ndarray'>
# 每条数据的属性就是图片中各个像素的灰度值, 存放在一个
print(type(test_x), type(test_y))
# <class 'numpy.ndarray'> <class 'numpy.ndarray'>
print((train_x.min(), train_x.max()))
print((test_y.min(), test_y.max()))
# 每个元素的灰度值在(0, 255)之间
# 数据的标签值在(0, 9)之间
# 四:数据预处理
"""
# 在输入神经网络时, 需要把每条数据的属性从 28 * 28 的二维数组转化为长度为 784 的一维数组
# 可以使用 reshape 方法进行转换
X_train = train_x.reshape((60000, 28*28))
X_test = test_x.reshape((10000, 28*28))
print(X_train.shape)
print(X_test.shape)
# 但是这一步也可以省略, 在这里保持输入数据的形状不变,
# 在后面创建神经网络时增加一个 Flatten() 层来实现输入数据维度的变化.(通过 tf.keras.layers.Flatten()函数来实现)
"""
# 为了加快迭代速度, 还要对属性进行归一化, 使其取值范围在 (0, 1)之间
# 与此同时, 把它转换为Tensor张量, 数据类型是 32 位的浮点数.
# 把标签值也转换为Tensor张量,数据类型是 8 位的整型数.
X_train, X_test = tf.cast(train_x / 255.0, tf.float32), tf.cast(test_x / 255.0, tf.float32)
y_train, y_test = tf.cast(train_y, tf.int16), tf.cast(test_y, tf.int16)
# 现在, 数据已经准备好了, 可以搭建模型了
# 五:搭建模型
# 在之前, 都是使用低阶 API 来训练和测试模型, 在这里直接使用 tf.keras.Sequential 来建立和训练模型
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28, 28)))
# 这里首先添加一个 Flatten 层, 说明输入层的形状, Flatten 层不进行计算, 只是完成形状转换, 把输入的属性拉直, 变成一维数组
# 这样在数据预处理阶段, 不用改变输入数据的形状, 隐含层中也不用再说明输入数据, 各层的结构更加清晰
model.add(tf.keras.layers.Dense(128, activation="relu"))
# 这里再添加隐含层, 隐含层是全连接层, 其中有 128 个结点, 激活函数采用 relu 函数
model.add(tf.keras.layers.Dense(10, activation="softmax"))
# 最后, 添加输出层, 输出层也是全连接层, 其中有 10 个结点, 激活函数采用 softmax 函数
# 六:查看模型结构和信息
# 下面使用 summary() 方法来查看模型结构和参数信息
print(model.summary())
"""
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0 可以看出输入层中共 784 个结点, 没有参数
_________________________________________________________________
dense (Dense) (None, 128) 100480 可以看出隐含层中共 128 个结点, 100480个参数
_________________________________________________________________
dense_1 (Dense) (None, 10) 1290 可以看出输出层中共有 10 个结点, 1290个参数
=================================================================
Total params: 101,770 所有参数为 101770 , 和前面计算的结果一致
Trainable params: 101,770 可训练参数为 101770
Non-trainable params: 0
_________________________________________________________________
None
"""
# 七:配置模型的训练方法
model.compile(loss='sparse_categorical_crossentropy',
# 损失函数使用稀疏交叉熵损失函数,
optimizer='adam', # 这里可以不用设置 adam 算法中的参数,
# 因为 keras 中已经使用常用的公开参数作为他们的默认值
# 在大多数情况下都可以得到比较好的结果
metrics=['sparse_categorical_accuracy'] # 在 mnist 手写数字数据集中
# 标签值是 0 ~ 9 的数字, 而神经网络的输出是一组概率分布, 类似独热编码的形式
# 所以使用稀疏准确率评价函数
)
# 八:训练模型
model.fit(X_train, y_train, batch_size=64, epochs=5, validation_split=0.2)
"""
750/750 [==============================] - 2s 2ms/step - loss: 0.3316 - sparse_categorical_accuracy: 0.9080
- val_loss: 0.1854 - val_sparse_categorical_accuracy: 0.9490
Epoch 2/5
750/750 [==============================] - 1s 2ms/step - loss: 0.1542 - sparse_categorical_accuracy: 0.9557
- val_loss: 0.1362 - val_sparse_categorical_accuracy: 0.9625
Epoch 3/5
750/750 [==============================] - 1s 2ms/step - loss: 0.1083 - sparse_categorical_accuracy: 0.9684
- val_loss: 0.1133 - val_sparse_categorical_accuracy: 0.9662
Epoch 4/5
750/750 [==============================] - 1s 2ms/step - loss: 0.0816 - sparse_categorical_accuracy: 0.9764
- val_loss: 0.1070 - val_sparse_categorical_accuracy: 0.9683
Epoch 5/5
750/750 [==============================] - 1s 2ms/step - loss: 0.0640 - sparse_categorical_accuracy: 0.9817
- val_loss: 0.0891 - val_sparse_categorical_accuracy: 0.9740
48000 / 64 = 750,由于批次中的数据元素是随机的,所以每次运行的结果都不同,但相差不大
"""
# 九:评估模型
# 这里使用 mnist 本身的测试集来评估模型
# verbose=2 表示输出进度条进度
model.evaluate(X_test, y_test, batch_size=64, verbose=2)
"""
157/157 - 0s - loss: 0.0831 - sparse_categorical_accuracy: 0.9753
可以看出评估结果和训练结束时差不多, 说明模型具备比较好的泛化能力
"""
# 十:保存整个模型参数
# 如果对这次训练结果满意, 就可以使用 save 方法来保存整个模型参数
model.save("mnist_model.h5")
查看本地文件夹
下次想要加载这个模型时,应该怎么做呢?
与 model.load_weights 函数相比,在加载完数据、对数据处理完之后,无需再说明(搭建)神经网络的结构和训练方法。
# 一:导入库函数
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
# 二:参数配置
# 图片显示中文字体的配置
plt.rcParams["font.family"] = "SimHei", "sans-serif"
# GPU显存的分配配置
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(gpus[0], True)
# 三:加载数据
mnist = tf.keras.datasets.mnist
(train_x, train_y), (test_x, test_y) = mnist.load_data()
# 四:数据预处理
# 为了加快迭代速度, 还要对属性进行归一化, 使其取值范围在 (0, 1)之间
# 与此同时, 把它转换为Tensor张量, 数据类型是 32 位的浮点数.
# 把标签值也转换为Tensor张量,数据类型是 8 位的整型数.
X_train, X_test = tf.cast(train_x / 255.0, tf.float32), tf.cast(test_x / 255.0, tf.float32)
y_train, y_test = tf.cast(train_y, tf.int16), tf.cast(test_y, tf.int16)
# 五:加载模型
model = tf.keras.models.load_model("mnist_model.h5")
# 六:查看模型结构和信息
# 下面使用 summary() 方法来查看模型结构和参数信息
print(model.summary())
"""
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
_________________________________________________________________
dense (Dense) (None, 128) 100480
_________________________________________________________________
dense_1 (Dense) (None, 10) 1290
=================================================================
Total params: 101,770
Trainable params: 101,770
Non-trainable params: 0
_________________________________________________________________
None
"""
# 七:使用测试集中的数据来评估模型性能
# 这里使用 mnist 本身的测试集来评估模型
# verbose=2 表示输出进度条进度
model.evaluate(X_test, y_test, batch_size=64, verbose=2)
"""
157/157 - 0s - loss: 0.0831 - sparse_categorical_accuracy: 0.9753
和保存之前的评估结果一样
"""
# 八:应用模型 -- 预测
# 下面再随机取出测试集中的任意4个数据进行识别
plt.figure()
for i in range(4):
num = np.random.randint(1, 10000)
plt.subplot(1, 4, i+1)
plt.axis("off")
plt.imshow(test_x[num], cmap="gray")
y_pred = np.argmax(model.predict(tf.reshape(X_test[num], (1, 28, 28))))
plt.title("y= "+str(test_y[num]) + "\n" + "y_pred=" + str(y_pred))
plt.suptitle("随机取出测试集中的任意4个数据进行识别", fontsize=20, color="red", backgroundcolor="yellow")
plt.show()
运行结果如下,
