1.多层前馈神经网络
首先说下多层前馈神经网络,BP算法,BP神经网络之间的关系。多层前馈(multilayer feed-forward)神经网络由一个输入层、一个或多个隐藏层和一个输出层组成,后向传播(BP)算法在多层前馈神经网络上面进行学习,采用BP算法的(多层)前馈神经网络被称为BP神经网络。给出一个多层前馈神经网络的拓扑结构,如下所示:
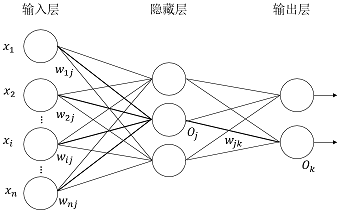
图1 多层前馈神经网络
神经网络的拓扑结构包括:输入层的单元数、隐藏层数(如果多于一层)、每个隐藏层的单元数和输出层的单元数。神经网络可以用于分类(预测给定元组的类标号)和数值预测(预测连续值输出)等。
2.后向传播(BP)算法详解
(1)初始值权重
神经网络的权重被初始化为小随机数,每个神经元都有一个相关联的偏置,同样也被初始化为小随机数。
(2)前向传播输入
以单个神经网络单元为例,如下所示:
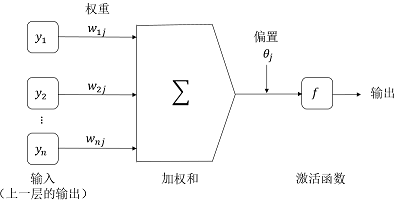
图2 神经网络单元
给定隐藏层或输出层的单元
,到单元
的净输入
,如下所示:
其中, 是由上一层的单元 到单元 的连接的权重; 是上一层的单元 的输出; 是单元 的偏置。需要说明的是偏置充当阀值,用来改变单元的活性。
给定单元 的净输入 ,单元 的输出 ,如下所示:
(3)后向传播误差
- 对于输出层单元
,误差
用下式计算:
其中, 是单元 的实际输出,而 是 给定训练元组的已知目标值。需要说明的是, 是逻辑斯缔函数的导数。 - 对于隐藏层单元
,它的误差用下式计算:
其中, 是由下一较高层中单元 到单元 的连接权重,而 是单元 的误差。 - 权重更新,如下所示:
其中, 是权重 的改变量,变量 是学习率,通常取0.0和1.0之间的常数值。 - 偏置更新,如下所示:
其中, 是 的改变量。 - 权重和偏置更新
如果每处理一个样本就更新权重和偏置,称为实例更新(case update);如果处理完训练集中的所有元组之后再更新权重和偏置,称为周期更新(epoch update)。理论上,反向传播算法的数据推导使用周期更新,但是在实践中,实例更新通常产生更加准确的结果。
说明:误差反向传播的过程就是将误差分摊给各层所有单元,从而获得各层单元的误差信号,进而修正各单元的权值,即权值调整的过程。
(4)终止条件
如果满足条件之一,就可以停止训练,如下所示:
- 前一周期所有的都太小,小于某个指定的阀值。
- 前一周期误分类的元组百分比小于某个阀值。
- 超过预先指定的周期数。
实践中,权重收敛可能需要数十万个周期。神经网络的训练有很多的经验和技巧,比如我们就可以使用一种称为模拟退火的技术,使神经网络确保收敛到全局最优。
3.用BP训练多层前馈神经网络
举个例子具体说明使用BP算法训练多层前馈神经网络的每个细节,如下所示:
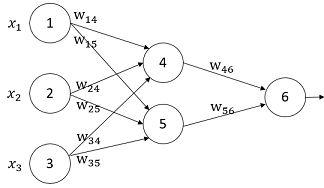
图3 用BP算法训练多层前馈神经网络
设置学习率为0.9,第一个训练元组为
,其类标号为1。神经网络的初始权重和偏置值如表1所示:

表1 初始输入、权重和偏置值
根据给定的元组,计算每个神经元的净输入和输出,如表2所示:

表2 净输入和输出的计算
每个神经元的误差值如表3所示:
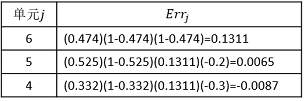
表3 每个节点误差的计算
说明:从误差的计算过程来理解反向(BP)传播算法也许更加直观和容易。
权重和偏置的更新如表4所示:
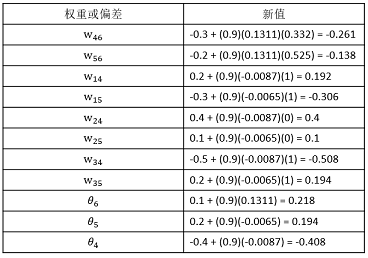
表4 权重和偏置更新的计算
说明:将该神经网络模型训练好后,就可以得到权重和偏执参数,进而做二分类。
4.用Python实现BP神经网络 [3]
神经网络拓扑结构,如下所示:
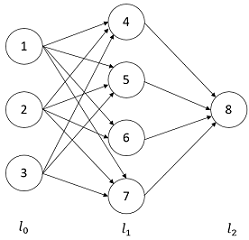
解析:
(1)第33和35行:l1和l2分别表示第1层和第2层神经元的输出。(第0层表示元组输入)
(2)第37行:l2_error与相对应。
(3)第40行:l2_delta与输出层误差相对应。
(4)第42行:l1_error与相对应。
(5)第43行:l1_delta与隐藏层误差相对应。
(6)第45行:l1.T.dot(l2_delta)与相对应,而syn1与相对应。
(7)第46行:l0.T.dot(l1_delta)与相对应,而syn0与相对应。
说明:
一边代码,一边方程,做到代码与方程的映射。这是一个基础的三层BP神经网络,但是麻雀虽小五脏俱全。主要的不足有几点:没有考虑偏置;没有考虑学习率;没有考虑正则化;使用的是周期更新,而不是实例更新(一个样本)和批量更新(m个样本)。但是,足以理解前馈神经网络和BP算法的工作原理。神经网络和BP算法的详细数学推导参考[5]。
参考文献:
[1] 数据挖掘:概念与技术(第三版)
[2] 使用Python构造神经网络:http://www.ibm.com/developerworks/cn/linux/l-neurnet/
[3] 一个11行Python代码实现的神经网络:http://python.jobbole.com/82758/
[4] 用BP人工神经网络识别手写数字:http://blog.csdn.net/gzlaiyonghao/article/details/7109898
[5] 反向传导算法:http://ufldl.stanford.edu/wiki/index.php/%E5%8F%8D%E5%90%91%E4%BC%A0%E5%AF%BC%E7%AE%97%E6%B3%95