Xpath 使用
1.什么是Xpath
XPath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言。最初是用来搜寻 XML 文档的,但同样适用于 HTML 文档的搜索。使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
2.Xptah解析原理
①实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中
②调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获
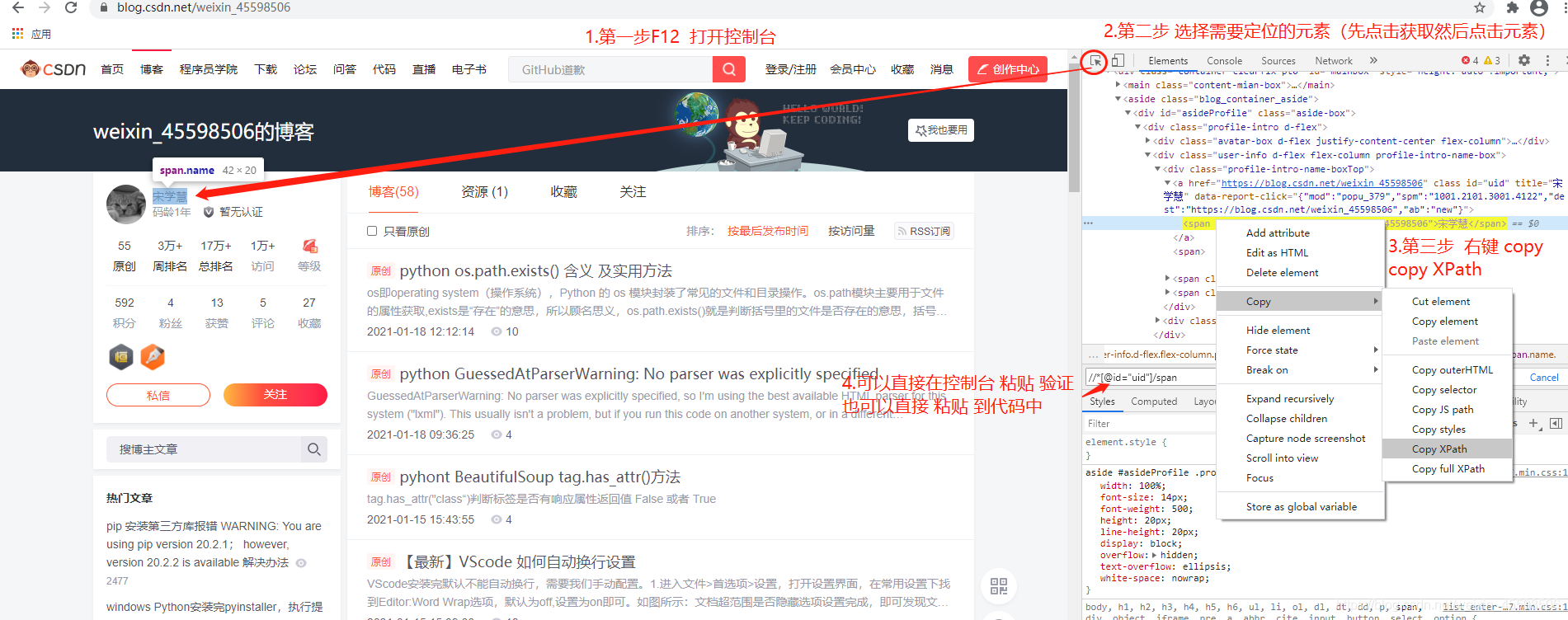
3.如何安装Xpath
直接使用pip 安装 pip install lxml
4.如果使用Xpath
(1)导入from lxml import etree
(2)将本地的html文档中的源码数据加载到etree对象中
html = etree.parse(r"路径/test.html")
(3) 可以将互联网上获取的源码数据加载到etree对象中
html = etree.HTML('page_text')
(4) 注意点:xpath方法返回的永远是一个列表
5.Xpath 表达式
节点、元素、属性、内容
路径表达式
| / | 根节点,节点分隔符 |
| // | 任意位置 |
| . | 当前节点 |
| … | 父节点 |
| @ | 属性 |
通配符
| * | 任意元素 |
| @* | 任意属性 |
| node() | 任意子节点(元素、属性、内容) |
谓语
使用中括号来限定元素,称为谓语
//a[n] n为大于零的整数,代表子元素排在第n个位置的<a>元素
//a[last()] last() 代表子元素排在最后个位置的<a>元素
//a[last()-1] 和上面同理,代表倒数第二个
//a[position()<3] 位置序号小于3,也就是前两个,这里我们可以看出xpath中的序列是从1开始
//a[@href] 拥有href的<a>元素
//a[@href='www.baidu.com'] href属性值为'www.baidu.com'的<a>元素
//book[@price>2] price值大于2的<book>元素
多个路径
用| 连接两个表达式,可以进行 或匹配
html_data = html.xpath("//book/title | //book/price")
②取值
Ⅰ.获取文本
直系文本:/text()
所有文本://text()
Ⅱ.获取属性
/@属性名称
获取img下面的src属性
img/@src
5.Xpath 常用函数
contains(string1,string2)
starts-with(string1,string2)
text()
last()
position()
node()
6.Chrome自动生成Xpath 表达式