写在前面:在写爬虫的时候需要对服务器返回的 html 代码进行内容的提取,可以通过正则表达式、XPath、BS4提取我们需要的数据,在这里我们重点介绍XPath。
XPath 是什么?
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
先介绍工具
- Chrome插件:XPath Helper
- Firefox插件:XPath Checker
- 开源的XPath表达式编辑工具:XMLQuire
这些工具可以方便再浏览器中测试我们写的 XPath ,看看所提取到的数据是否正确.
使用方法一个例子全搞定.
再吃个栗子
一个例子告诉你XPath是干什么的 && 工具有什么用。
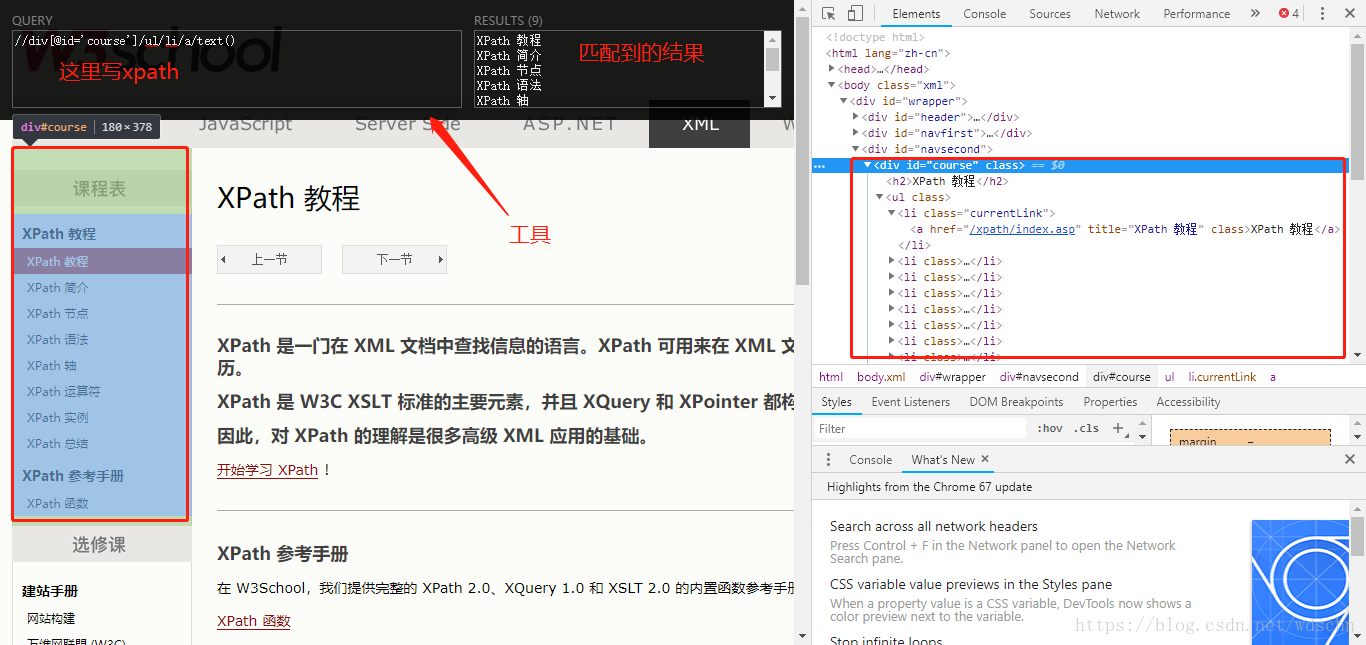
在上边的例子中,我们使用 //div[@id=’course’]/ul/li/a/text() 获取到了页面左侧课程表栏目下的所有链接的文字内容。
拨开这个栗子:
- “ // ”:最前边的 “ // ” 表示的意思是 从当前节点选择文档中的节点,而不考虑它们的位置。我们的 xpath 代码都是需要使用它开始。
- “ div ”:表示我们要查找 // 下的 div
- “ [@id=’course’] ”:是对前边 div 的限定,表示只查找 id属性为‘course’的div。
- “ /ul/li/a ” :在前边的获取到符合条件的div的内部再向里找ul,ul再向里找li,li再向里找a
- “ /text() ”:获取标签内文字。即获取到我们前边找到的所有符合条件的a标签的文字。
栗子已经吃完,但是这只是老王家卖的栗子。如果遇到了老张家那超级难剥的栗子怎么办?要掌握剥栗子的基本技能再遇见问题就可以可劲的怼怼怼了。
XPath 语法规则
在接下来的介绍中,我们使用一个xml例子来说明各个功能是使用。
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>选取节点

实例:
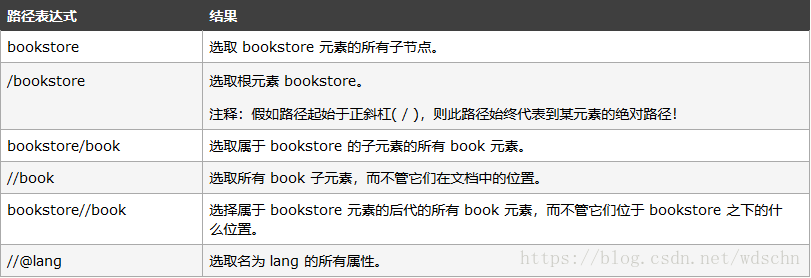
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
谓语(Predicates)
谓语是被嵌在方括号中的 [] 。用来查找某个特定的节点或者包含某个指定的值的节点。
实例:
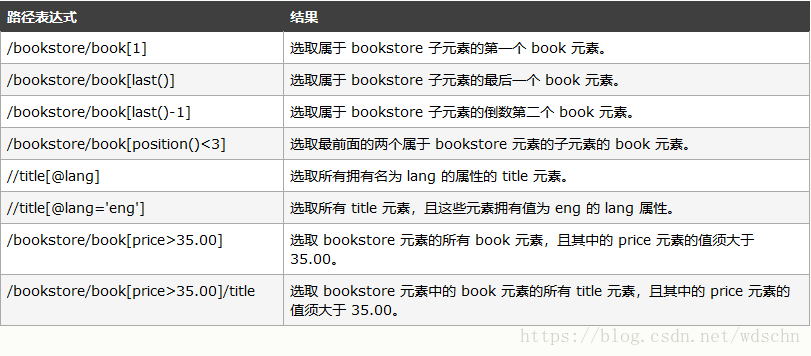
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
选取未知节点
XPath 通配符可用来选取未知的元素。

实例:
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:

选取若干路径
通过在路径表达式中使用 “ | ” 运算符,您可以选取若干个路径。
实例:
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:

XPath 运算符
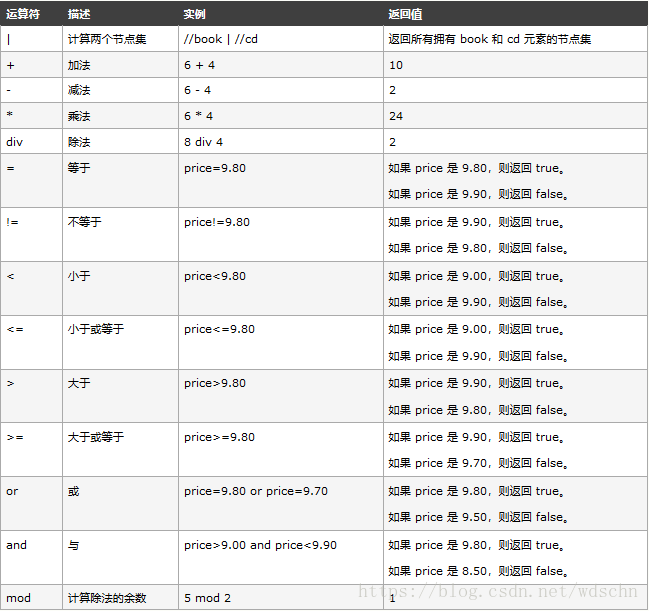
下面列出了可用在 XPath 表达式中的运算符:
Xpath 的使用是一个非常简单的操作。只要熟悉了一些常用的操作,写过一些之后便就得心应手。