转自:https://www.pianshen.com/article/33331174884/
1.22.Linear常用激活函数
1.22.1.ReLU torch.nn.ReLU()
1.22.2.RReLU torch.nn.RReLU()
1.22.3.LeakyReLU torch.nn.LeakyReLU()
1.22.4.PReLU torch.nn.PReLU()
1.22.5.Sofplus torch.nn.Softplus()
1.22.6.ELU torch.nn.ELU()
1.22.7.CELU torch.nn.CELU()
1.22.8.SELU torch.nn.SELU()
1.22.9.GELU torch.nn.GELU()
1.22.10.ReLU6 torch.nn.ReLU6()
1.22.11.Sigmoid torch.nn.Sigmoid()
1.22.12.Tanh torch.nn.Tanh()
1.22.13.Softsign torch.nn.Softsign()
1.22.14.Hardtanh torch.nn.Hardtanh()
1.22.15.Threshold torch.nn.Threshold()
1.22.16.Tanhshrink torch.nn.Tanhshrink()
1.22.17.Softshrink torch.nn.Softshrink()
1.22.18.Hardshrink torch.nn.Hardshrink()
1.22.19.LogSigmoid torch.nn.LogSigmoid()
1.22.20.Softmin torch.nn.Softmin()
1.22.21.Softmax torch.nn.Softmax()
1.22.22.LogSoftmax torch.nn.LogSoftmax()
1.22.Linear常用激活函数
1.22.1.ReLU torch.nn.ReLU()
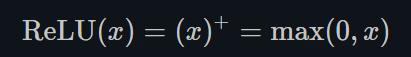
ReLU的函数图示如下: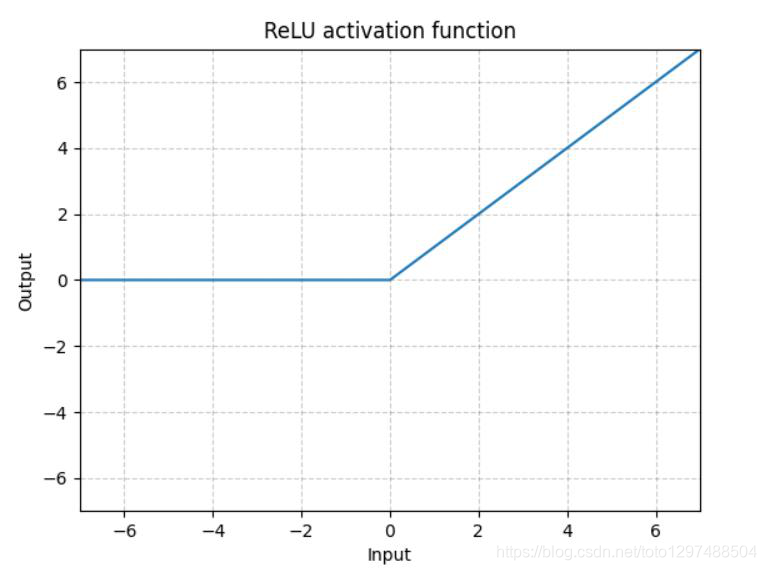
1.22.2.RReLU torch.nn.RReLU()
ReLU有很多变种, RReLU是Random ReLU的意思,定义如下: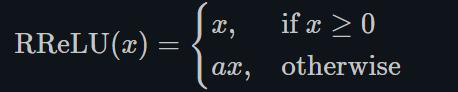
对RReLU而言, a是一个在给定范围内的随机变量(训练), 在推理时保持不变。同LeakyReLU不同的是,RReLU的a是可以learnable的参数,而LeakyReLU的a是固定的。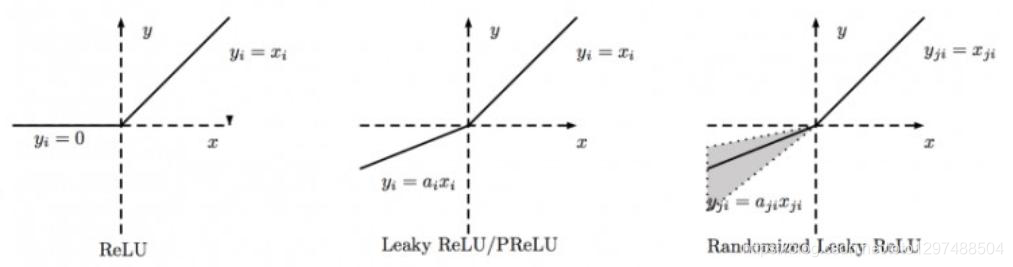
1.22.3.LeakyReLU torch.nn.LeakyReLU()

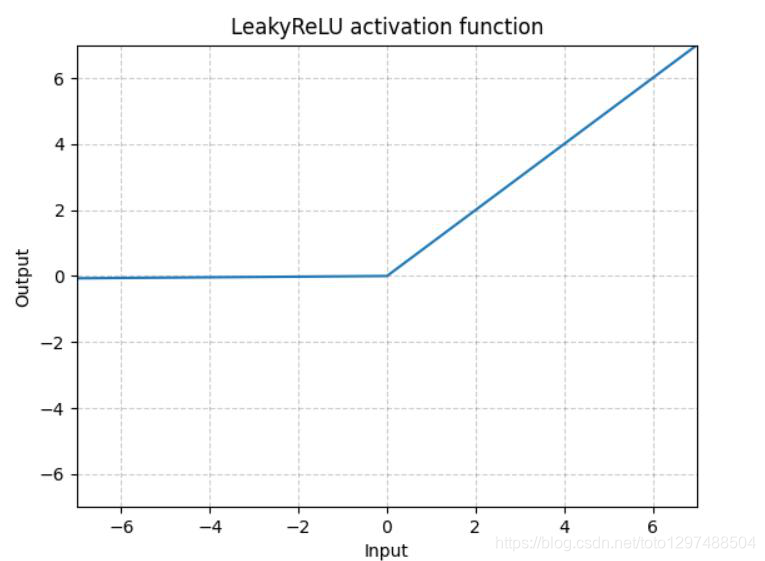
这里a是固定值,LeakyReLU的目的是为了避免激活函数不处理负值(小于0的部分梯度为0),通过使用negative slope,其使得网络可以在传递负值部分的梯度,让网络可以学习更多的信息,在一些应用中确实有较大的益处。
1.22.4.PReLU torch.nn.PReLU()
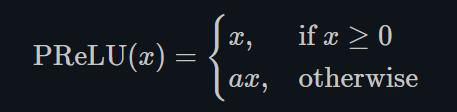
不同于RReLU的a可以是随机的,PReLU中的a就是一个learnable的参数。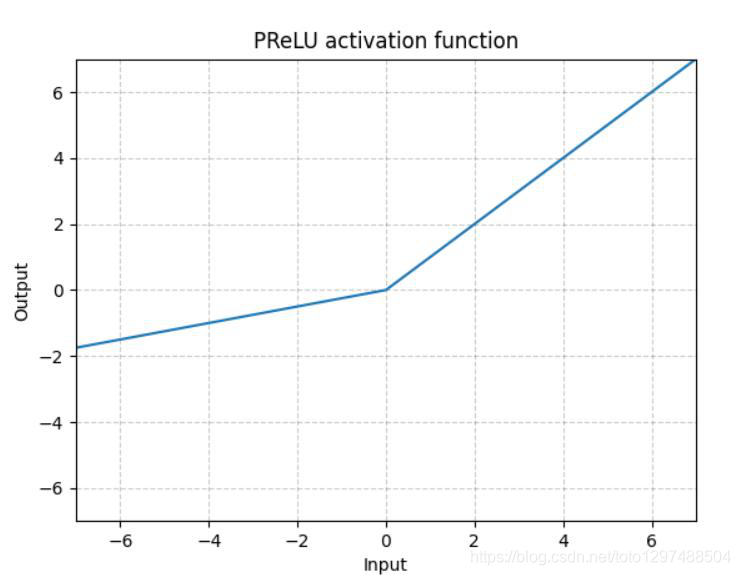
需要注意的是:上述激活函数(即ReLU、LeakyReLU、PReLU)是尺度不变(scale-invariant)的。
1.22.5.Sofplus torch.nn.Softplus()
Softplus作为损失函数在StyleGAN1和2中都得到了使用,下面分别是其表达式和图解。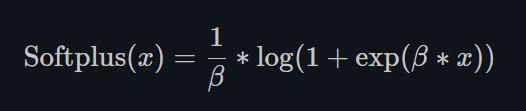
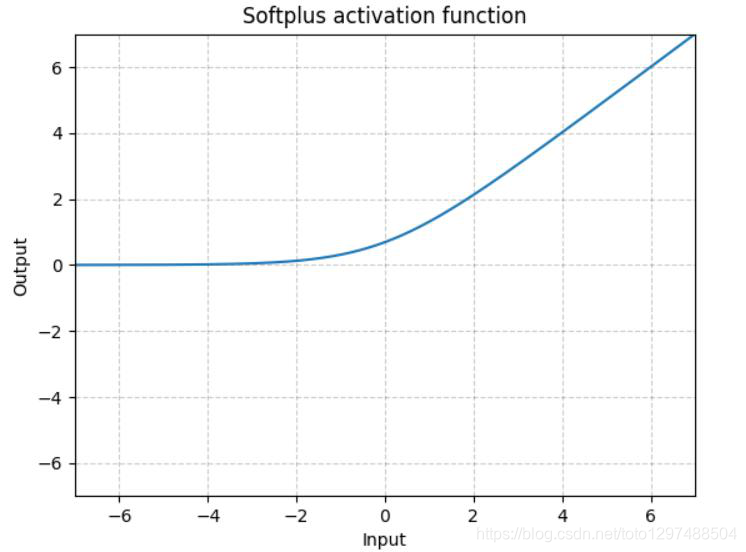
Softplus 是ReLU的光滑近似,可以有效的对输出都为正值的网络进行约束。
随着β的增加,Softplus与ReLU越来越接近。
1.22.6.ELU torch.nn.ELU()
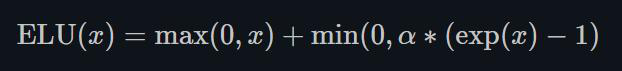

ELU不同于ReLU的点是,它可以输出小于0的值,使得系统的平均输出为0。因此,ELU会使得模型收敛的更加快速,其变种(CELU , SELU)只是不同参数组合ELU。
1.22.7.CELU torch.nn.CELU()
跟ELU相比,CELU是将ELU中的exp(x)变为exp(x/a)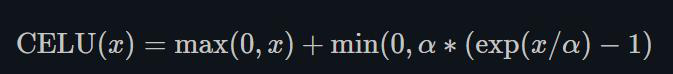
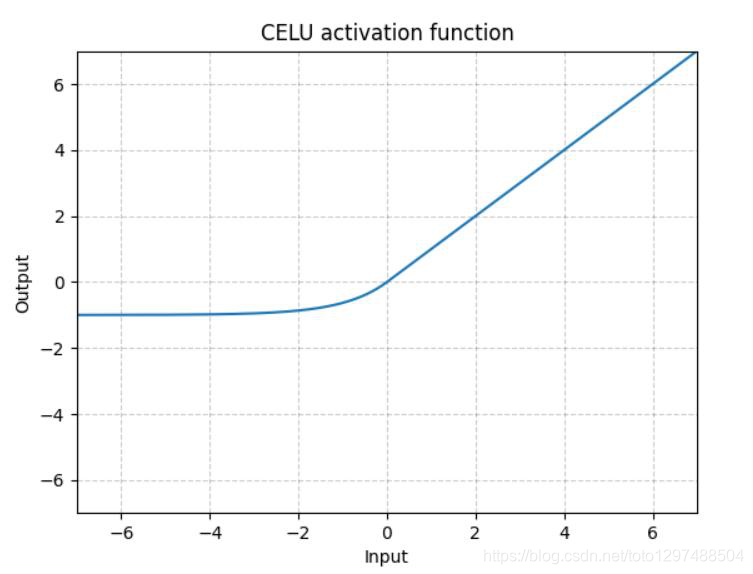
1.22.8.SELU torch.nn.SELU()
跟ELU相比,SELU是将ELU乘上了一个scala变量。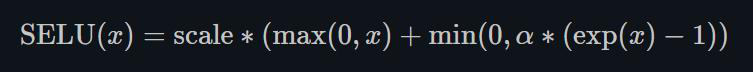
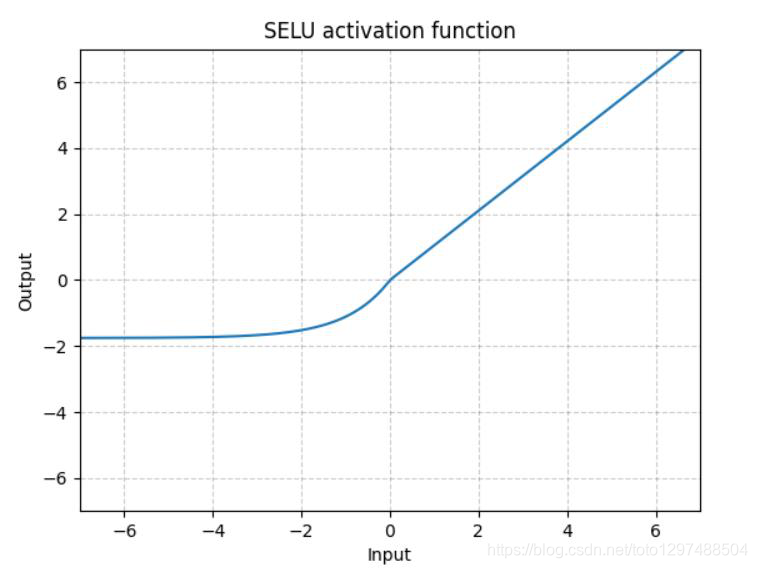
1.22.9.GELU torch.nn.GELU()
其中(x)Φ(x)是高斯分布的累积分布函数(Cumulative Distribution Function for Gaussian Distribution)。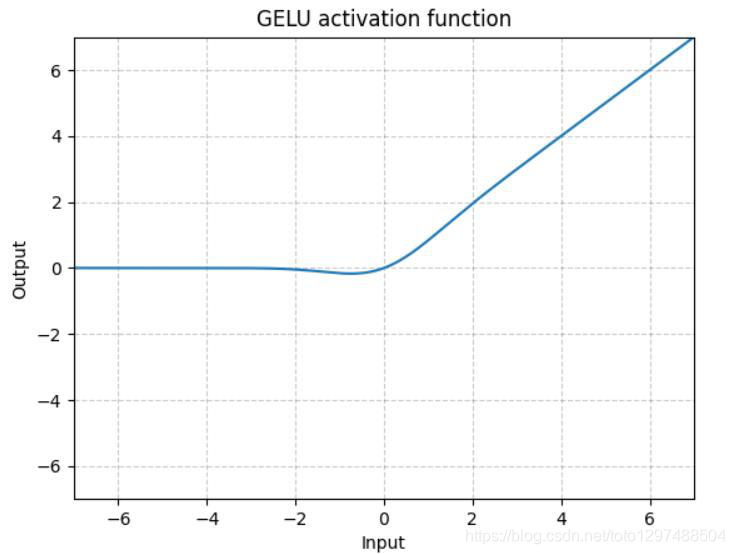
1.22.10.ReLU6 torch.nn.ReLU6()
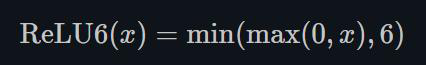
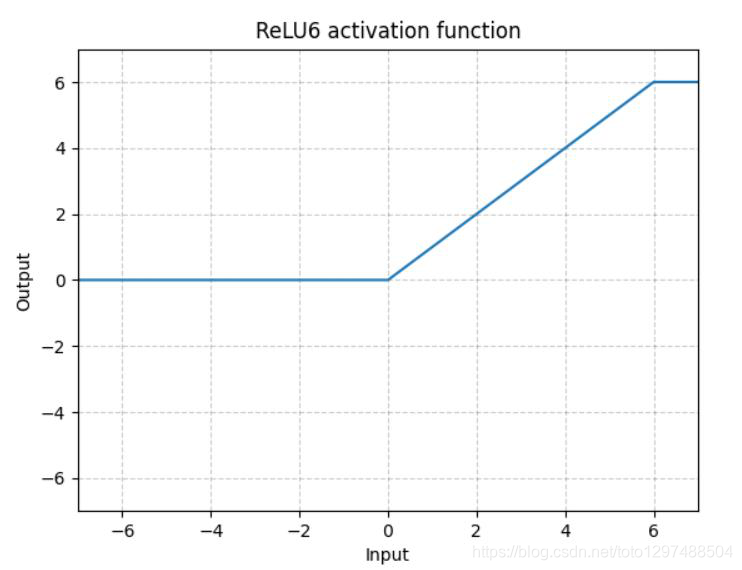
ReLU6是在ReLU的基础上,限制正值的上限6. one-stage的目标检测网络SSD中用这个损失函数。
1.22.11.Sigmoid torch.nn.Sigmoid()
Sigmoid是将数据限制在0到1之间。而且,由于Sigmoid的最大的梯度为0.25,随着使用sigmoid的层越来越多,网络就变得很难收敛。
因此,对深度学习,ReLU及其变种被广泛使用避免收敛困难的问题。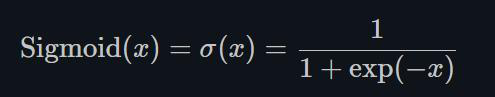
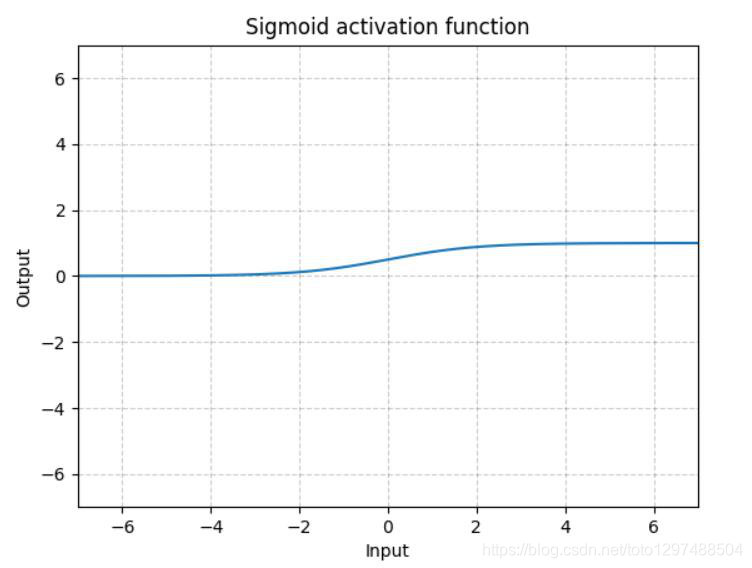
1.22.12.Tanh torch.nn.Tanh()
Tanh就是双曲正切,其输出的数值范围为-1到1. 其计算可以由三角函数计算,也可以由如下的表达式来得出: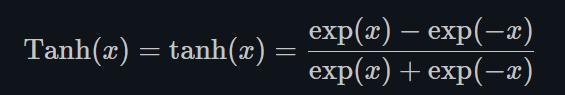
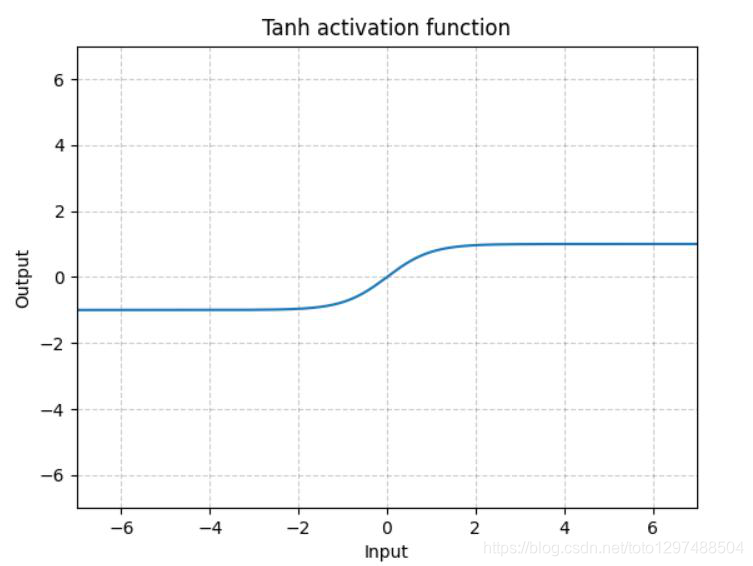
Tanh除了居中(-1到1)外,基本上与Sigmoid相同。这个函数的输出的均值大约为0。因此,模型收敛速度更快。注意,如果每个输入变量的平均值接近于0,那么收敛速度通常会更快,原理同Batch Norm。
1.22.13.Softsign torch.nn.Softsign()
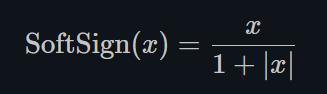
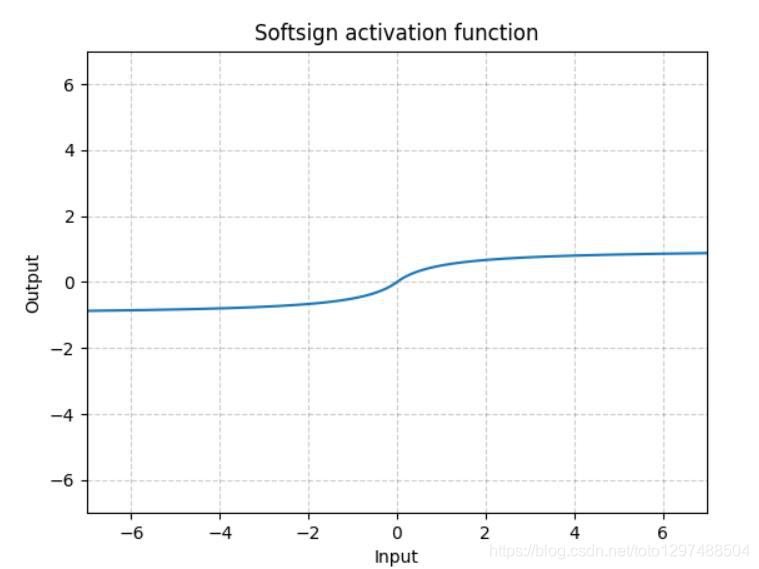
同Sigmoid有点类似,但是它比Sigmoid达到渐进线(asymptot n. [数] 渐近线)的速度更慢,有效的缓解了梯度消失的问题(gradient vanishing problem (to some extent).)。
1.22.14.Hardtanh torch.nn.Hardtanh()
如下图所示,Hardtanh就是1个线性分段函数[-1, 1],但是用户可以调整下限min_val和上限max_val,使其范围扩大/缩小。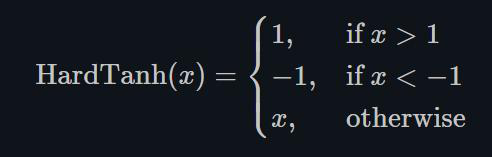
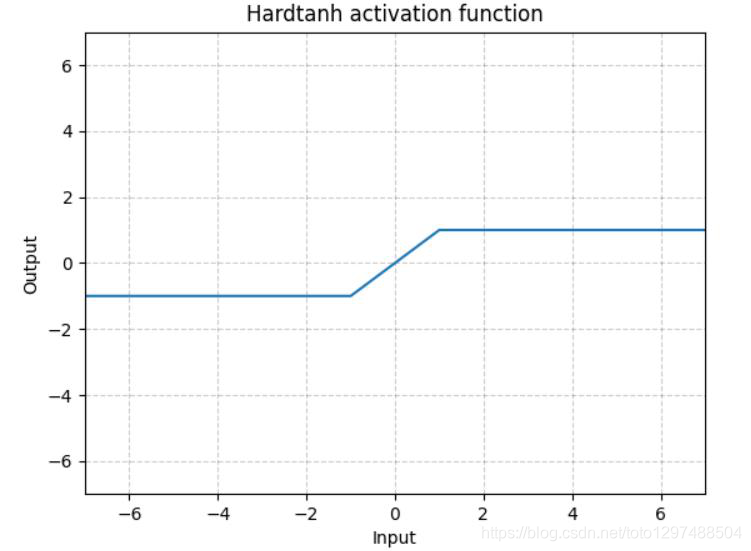
当权值保持在较小的范围内时,Hardtanh的工作效果出奇的好。
1.22.15.Threshold torch.nn.Threshold()
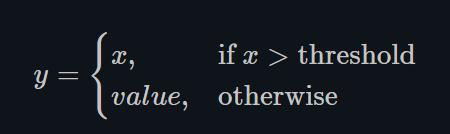
这种Threshold的方式现在很少使用,因为网络将不能传播梯度回来。这也是在60年代和70年代阻止人们使用反向传播的原因,因为当时的科研人员主要使用的是Binary的神经元,即输出只有0和1,脉冲信号。
1.22.16.Tanhshrink torch.nn.Tanhshrink()
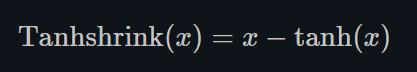
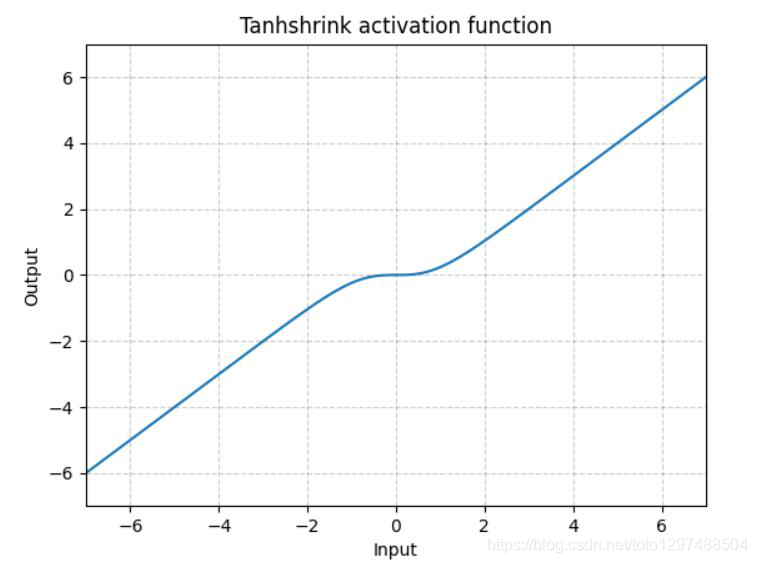
除了稀疏编码外,很少使用它来计算潜在变量(latent variable)的值。
1.22.17.Softshrink torch.nn.Softshrink()
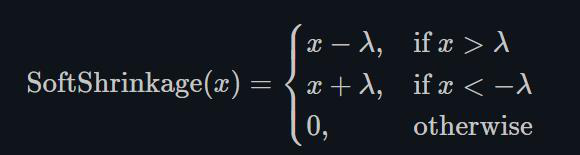
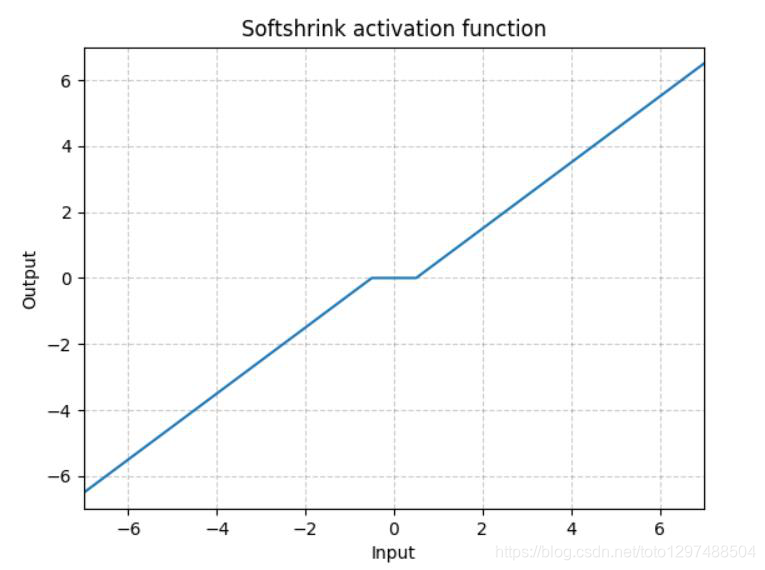
这种方式目前也不怎么常用,其目的是通过设置λ,将靠近0的值直接强制归0,由于这种方式对小于0的部分没有约束,所以效果不太好。
1.22.18.Hardshrink torch.nn.Hardshrink()
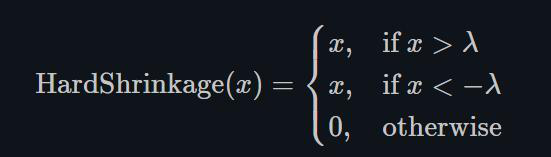
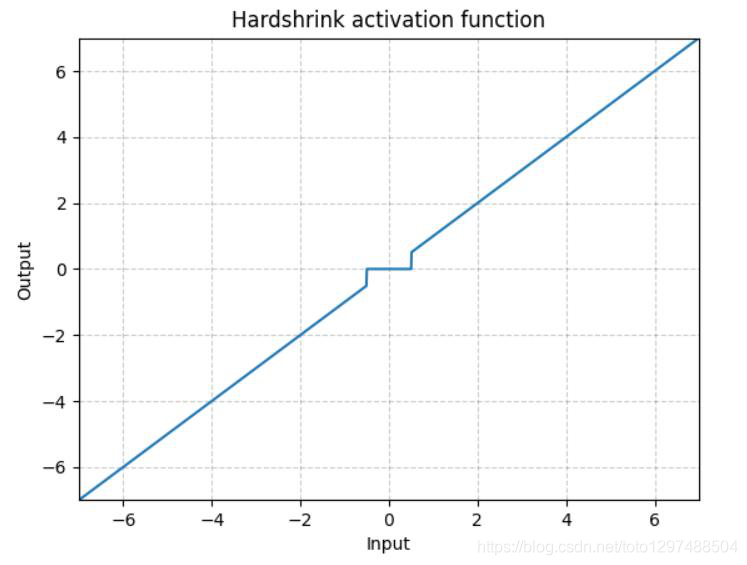
同Softshrink类似,除了稀疏编码以外,很少被使用。
1.22.19.LogSigmoid torch.nn.LogSigmoid()
LogSigmoid是在Sigmoid基础上,wrap了一个对数函数。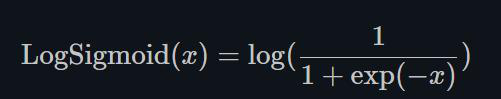
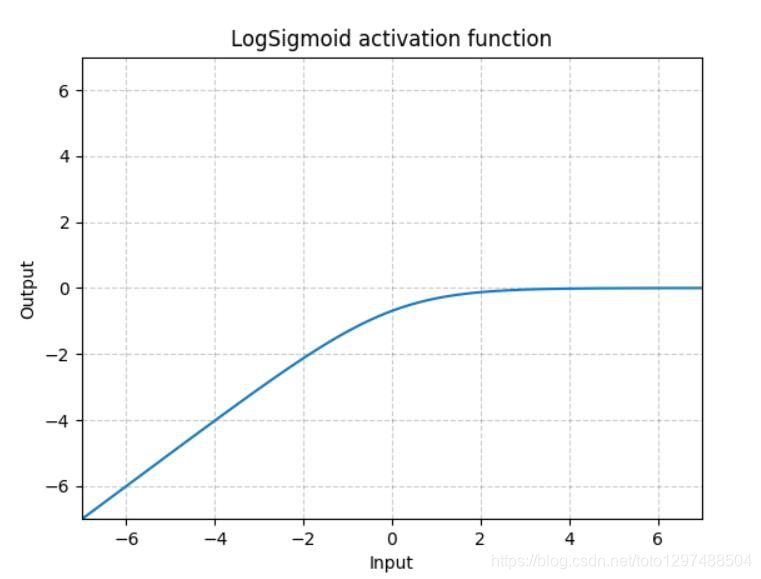
这种方式用作损失函数比较多
1.22.20.Softmin torch.nn.Softmin()
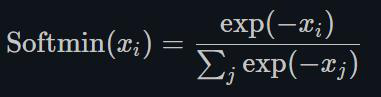
将数字变成概率分布,类似Softmax。
1.22.21.Softmax torch.nn.Softmax()
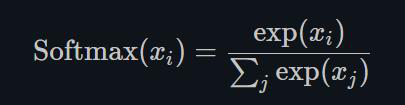
1.22.22.LogSoftmax torch.nn.LogSoftmax()
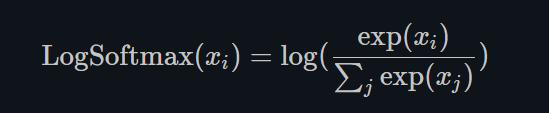
同LogSigmoid类似,LogSoftmax用作损失函数比较多
承接Matlab、Python和C++的编程,机器学习、计算机视觉的理论实现及辅导,本科和硕士的均可,咸鱼交易,专业回答请走知乎,详谈请联系QQ号757160542,非诚勿扰。