一、前言
TF-IDF方法的主要思想是:如果某个词或短语在一篇文章中出现的频率(TF) 高,并且在其他文章中很少出现(IDF高),则认为此词或者短语具有很好的类别区分能力。
二、步骤
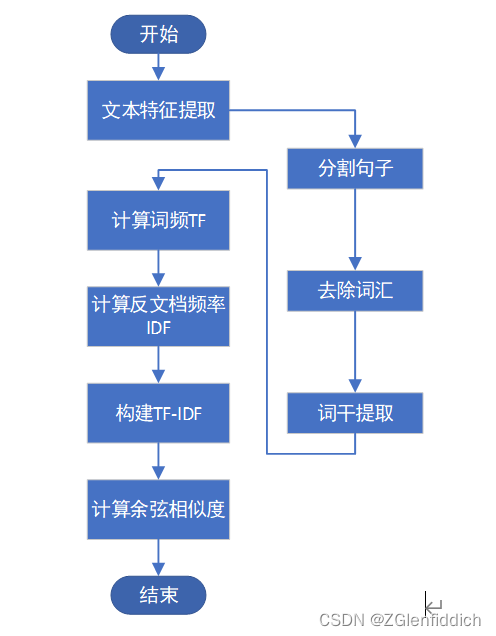
首先对文档进行特征提取操作:
(1)分割句子:按照空格进行分割,去除数字以及标点符号,并将所有字符全部小写;
(2)去除词汇:去除代词、冠词等功能词;
(3)词干提取:去除单词的复数、过去式、比较级、最高级等形式。
然后对生成的语料库进行每个文档的词频计算、反文档频率计算操作,从而构建出TF-IDF映射表。此时,每个文档都能够用一个单词向量表示。
最终对两个文档的单词向量使用余弦公式进行相似度计算即可。流程图如下所示:
三、函数实现
0.数据准备
我们需要将待处理的文本数据,全部用txt格式保存。如果原始数据是doc或者docx文件,建议先使用word的替换功能,替换掉原始文本数据中的换行符、段落标记等,替换成空格,再保存到txt文件里,常用特殊符号的替换方法如下:
| 输入符号 | 含义 |
| ^p | 段落标记 |
| ^l | 手动换行符 |
| ^m | 手动分页符 |
| ^s | 不间断空格 |
| ^+ | 长划线 |
| ^= | 短划线 |
| ^~ | 不间断连字符 |
1.导包
import re
import nltk.stem.snowball as sb
import pandas as pd
import math
from scipy import spatial| 包名 | 用途 |
| re | 正则表达式 |
| nltk.stem.snowball |
词干提取 |
| pandas |
输出格式控制 |
| math |
数学计算 |
| spatial |
计算余弦相似度 |
2.控制台输出
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 1000)注意:用于控制台输出多行多列数据,而不是省略号,更方便我们确定数据的正确性和完整性。
3.分割句子
def sentence_divide(path):
data = []
with open(path, "r", encoding='utf-8') as f:
for line in f.readlines():
# 1.去除数字,标点,且所有字符全部小写
line = re.sub(r'[.,"\'-?:!;]', '', line).lower()
line = line.strip("\n")
# 2.按照空格分隔
line = line.split()
data.append(line)
return data[0]注意:这里最后return data[0],因为我提前将文本存储为一行,如果你的txt自动换行,可以关闭这个功能,或者把return data[0]改为return data。
4.去除词汇
def delete_word(wordlist):
stop_words = ['i', 'me', 'my', 'myself', 'we', 'is', 'for', 'the', 'those', 'a', 'of', 'he', 'so', 'they', 'may',
'all', 'which', 'shall', 'towards', 'being', 'been', 'had', 'have', 'having', 'whose', 'was',
'she', 'it', 'then', 'and', 'by', 'if', 'where', 'when', 'how', 'would', 'not', 'such', 'through',
'do', 'their', 'be', 'were', 'an',
'as', 'this', 'that', 'in', 'on', 'to', 'but', 'there', 'into', 'or', 'should']
words = []
for word in wordlist:
if word not in stop_words:
words.append(word)
return words注意:这里的stop_words相当与nltk库里的stop_words停止词,就是过滤掉我们原始文档中存在的这些没有实际意义的介词、连词等。下载nltk库里的stop_words会出问题,建议和我一样,自己制定就行。
5.词干提取
def standard_word(wordlist):
words = []
# 词干提取
sb_stemmer = sb.SnowballStemmer('english')
for word in wordlist:
words.append(sb_stemmer.stem(word))
return words6.建立语料库
def word_lib(wordlist1, wordlist2, wordlist3, wordlist4):
lib = wordlist1+wordlist2+wordlist3+wordlist4
lib = set(lib)
return lib注意:这里的wordlist1, wordlist2, wordlist3, wordlist4,是因为我有四个文档需要对比,因此就放在了一起,你有几个文档,就写几个。
7.TF词频计算
def token_fre(wordlist, wordslib):
d = {}
corpusCount = len(wordlist)
for w in wordslib:
d[w] = 0
for word in wordlist:
d[word] += 1
for word, c in d.items():
d[word] = c / float(corpusCount)
return d注意:词频计算,n为该词在当前文本中出现的次数,sum为当前文本的总词数。实质就是就是计算文档中每个词汇在单个文本中出现的频率。
8.IDF文档频率计算
def idf_fre(wordlist):
idfDict = {}
N = len(wordlist)
idfDict = dict.fromkeys(wordlist[0].keys(), 0)
for word, val in idfDict.items():
idfDict[word] = math.log10(N / (float(val) + 1))
return (idfDict)注意:文档频率计算。其中N为文档总个数,n为包含该词的文档个数,加1是为了防止分母为0。
9.TF-IDF计算
def computeTFIDF(tfBow, idfs):
tfidf = {}
for word, val in tfBow.items():
tfidf[word] = val * idfs[word]
return tfidf注意:。
10.计算余弦相似度
def cosine_cal(v1, v2):
cos_sim = 1 - spatial.distance.cosine(v1, v2)
return cos_sim四、总结
文本相似度分析的方法还有其他,以后有机会再学习