问答系统所需要的数据已经提供,对于每一个问题都可以找得到相应的答案,所以可以理解为每一个样本数据是 <问题、答案>。 那系统的核心是当用户输入一个问题的时候,首先要找到跟这个问题最相近的已经存储在库里的问题,然后直接返回相应的答案即可。
由于作者是学电气的,这里以电力调度知识文本来构建问答系统
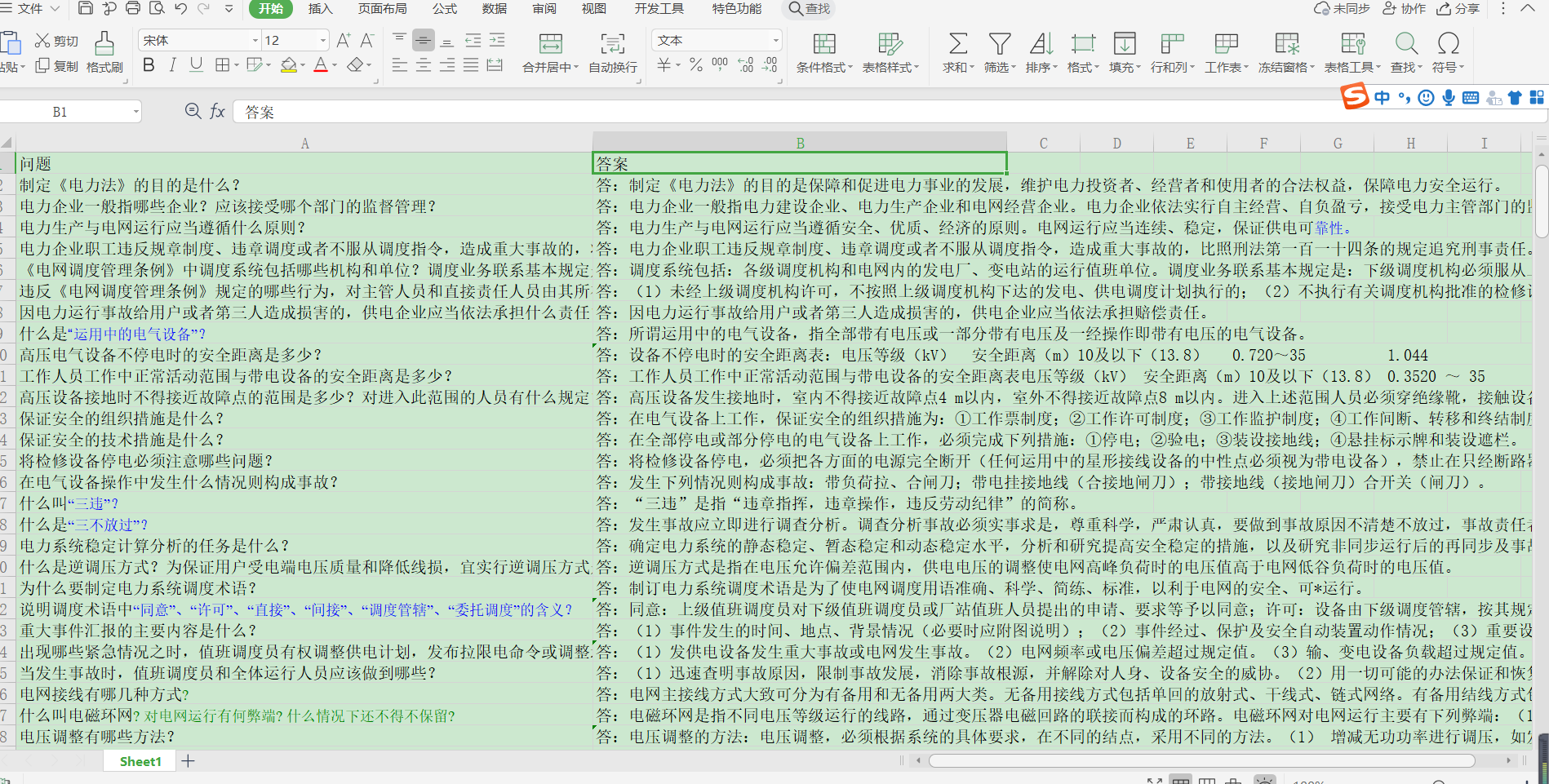
原始表格样子,我准备了调度相关的205个的问题和答案。
语言:python3.7
第一步:读取数据
import pandas as pd
import numpy as np
import jieba
import re
csv='电力调度问答.csv'
file_txt=pd.read_csv(csv, header=0,encoding='gbk')#[205 rows x 2 columns]
file_txt=file_txt.dropna()#删除空值[[205 rows x 2 columns]
print(file_txt.head())#查看前5行

第二步:过滤停用词,标点符号,单字词
中文停用词链接;
nlp 中文停用词数据集
# 定义删除除字母,数字,汉字以外的所有符号的函数
def remove_punctuation(line):
line = str(line)
if line.strip() == '':
return ''
rule = re.compile(u"[^a-zA-Z0-9\u4E00-\u9FA5]")
line = rule.sub('', line)
return line
#停用词
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='gbk').readlines()]
return stopwords
stopwords = stopwordslist("停用词.txt")
#去除标点符号
file_txt['clean_review']=file_txt['问题'].apply(remove_punctuation)
#去除停用词
file_txt['cut_review']=file_txt['clean_review'].apply(lambda x:" ".join([w for w in list(jieba.cut(x)) if w not in stopwords and len(w)>1]))
print(file_txt.head())
得到的cut_review为问题的关键词信息

查看下cut_review

第三步:文本向量化表示
因为我们是根据输入一个问题,然后从系统里找到和用户所题问题相似的问题,输出答案。需要计算相似度,在这之前需要先文本向量化表示。
我采用tf-idf表示,直接导入包使用吧。
from sklearn.feature_extraction.text import CountVectorizer#词袋
from sklearn.feature_extraction.text import TfidfTransformer#tfidf
count_vect = CountVectorizer()
X= count_vect.fit_transform(file_txt['cut_review'])
#tf-idf
tfidf_transformer = TfidfTransformer()
X_fidf = tfidf_transformer.fit_transform(X)
print(X_fidf)
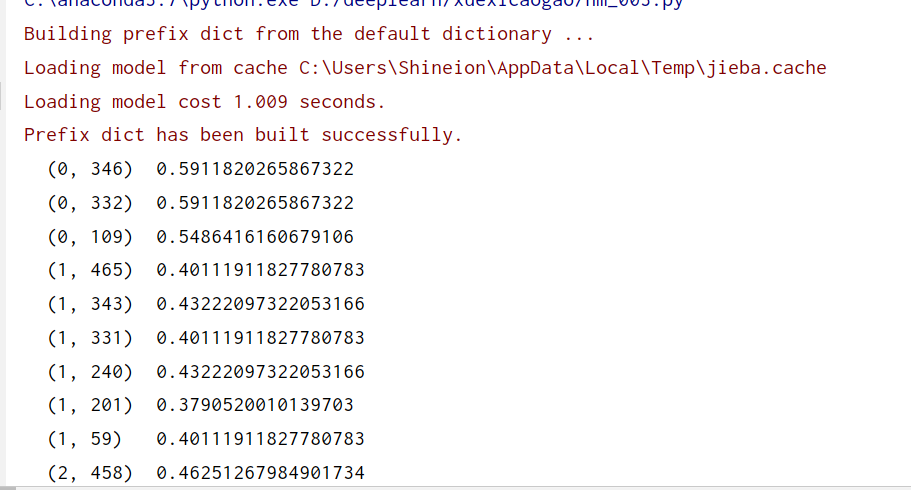
第四步:原始索引
我这里的原始索引为
{‘问题IID’:[关键词1,关键词2…],‘问题2ID’:[关键词2,关键词3…]…}
其中的ID为问题1所以的行数,即问题1为第一个问题,ID为1。
for i in range(len(file_txt)):
left, rights = i,file_txt.iloc[i]['cut_review'].split()
由于数太多,我这里修改下代码,假设只有5个问题

for i in range(len(file_txt.head())):
left, rights = i,file_txt.iloc[i]['cut_review'].split()
print('left is ',i,'rights is ',rights)

原始索引可以不出现总代码里,我写出来,只是为了方便你们阅读。
第五步:倒排索引实现
因为我们需要将用户提出的问题和库的问题进行相似度计算,然后返回相似度高的问题答案。 如果我们遍历库的每一个问题,然后和用户提出的问题做相似度计算,如果数据量大,则时间成本太大。
于是,这里需要倒排索引。
前文提到的原始索引为
{‘问题IID’:[关键词1,关键词2…],‘问题2ID’:[关键词2,关键词3…]…}
处理后的倒排索引为
{‘关键词1’:[问题1ID],‘关键词2’:[问题1ID,问题2ID…}
然后对用户提的问题,首先先分词,找到问题的关键词。然后根据关键词,找到包含该关键词的所有问题ID。再把这些问题和用户提的问题进行相似度计算。
通过倒排表,我们无需在计算相似度时遍历库的所有问题,只需遍历包含用户问题关键词的问题即可。
result={
}
for i in range(len(file_txt)):
left, rights = i,file_txt.iloc[i]['cut_review'].split()
for right in rights:
if right in result.keys():
result[right].append(left)
else:
result[right] = [left]
同理,由于原始数据量太大,我假设问题只有5个,这时来查看下倒排索引是什么。体验下什么是倒排索引
result={
}
for i in range(len(file_txt.head())):
left, rights = i,file_txt.iloc[i]['cut_review'].split()
for right in rights:
if right in result.keys():
result[right].append(left)
else:
result[right] = [left]
print(result)
如图所示,在只有5个问题下,包含关键词制定的问题只有1,包含关键词电力企业的有问题1,3…

第六步:对用户输入的问题进行分词,提取关键词,找到匹配到的所有问题ID
假设用户输入的问题是:sentence=“中性点接地方式有哪些”
得到的关键词是:[‘中性点’, ‘接地’, ‘方式’]
sentence="中性点接地方式有哪些"
clean_reviewyonghu=remove_punctuation(sentence)#去除标点
cut_reviewyonghu=[w for w in list(jieba.cut(clean_reviewyonghu)) if w not in stopwords and len(w)>1]#去除停用词,单字词
#print(cut_reviewyonghu)
# ['中性点', '接地', '方式']
Problem_Id=[]
for j in cut_reviewyonghu:
if j in result.keys():
Problem_Id.extend(result[j])
id=(list(set(Problem_Id)))#去重之后的ID
print(id)
得到的问题ID是
该问题在数据库里对应的问题有17个问题

第七步:相似度计算
将用户所提问题 “中性点接地方式有哪些” 和找到的17个问题,一一计算文档相似度。
相似度计算有很多种方式,我在下面用的相似度计算方法,没有用上第三步中文本向量化。
相似度计算有多种方式,具体参考我之前的一篇博客
文本相似度几种计算方法及代码python实现
#余弦相识度计算方法
def cosine_similarity(sentence1: str, sentence2: str) -> float:
"""
:param sentence1: s
:param sentence2:
:return: 两句文本的相识度
"""
seg1 = [word for word in jieba.cut(sentence1) if word not in stopwords]
seg2 = [word for word in jieba.cut(sentence2) if word not in stopwords]
word_list = list(set([word for word in seg1 + seg2]))#建立词库
word_count_vec_1 = []
word_count_vec_2 = []
for word in word_list:
word_count_vec_1.append(seg1.count(word))#文本1统计在词典里出现词的次数
word_count_vec_2.append(seg2.count(word))#文本2统计在词典里出现词的次数
vec_1 = np.array(word_count_vec_1)
vec_2 = np.array(word_count_vec_2)
#余弦公式
num = vec_1.dot(vec_2.T)
denom = np.linalg.norm(vec_1) * np.linalg.norm(vec_2)
cos = num / denom
sim = 0.5 + 0.5 * cos
return sim
str1=sentence#用户所提问题
similarity={
}#存储结果
if len(id)==0:
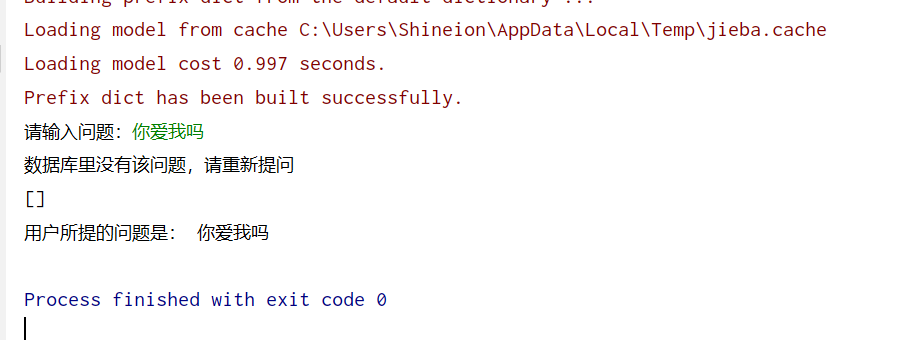
print('数据库里没有该问题,请重新提问')
else:
for i in id:
str2 = file_txt.iloc[i]['问题']
sim1 = cosine_similarity(str1, str2) # 余弦相识度
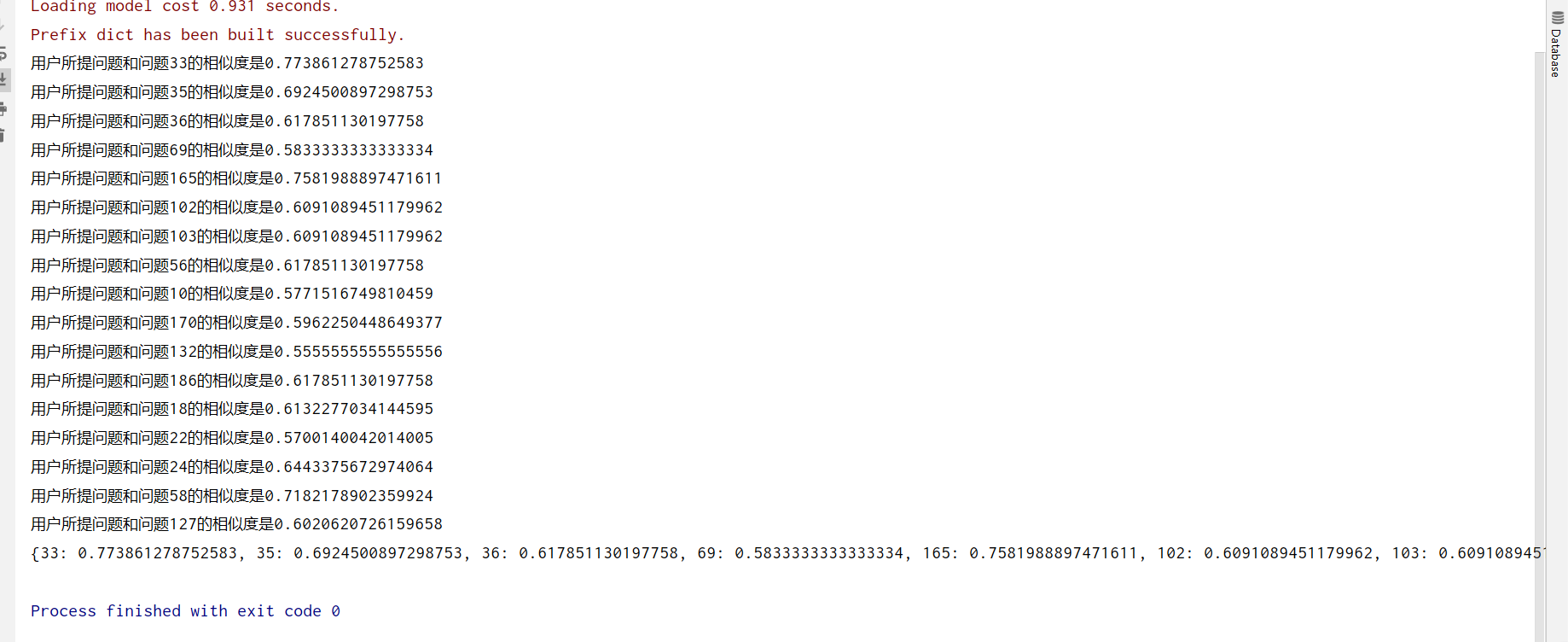
print('用户所提问题和问题{0}的相似度是{1}'.format(i, sim1))
similarity[i] = sim1
print(similarity)
第八步:给出答案
将第七步得到的similarity={} 进行排序,输出相似度最高的2个问题答案
jieguo=sorted(similarity.items(),key=lambda d:d[1],reverse=True)[:2]#降序
print(jieguo)
print('用户所提的问题是:',sentence)
for i,j in jieguo:
print('数据库相似的问题是{0} 答案是{1}'.format(i,file_txt.iloc[i]['答案']))
答案如下:可以发问题33的答案是我们要找的答案

完美
整理后的总代码
import pandas as pd
import numpy as np
import jieba
import re
# 定义删除除字母,数字,汉字以外的所有符号的函数
def remove_punctuation(line):
line = str(line)
if line.strip() == '':
return ''
rule = re.compile(u"[^a-zA-Z0-9\u4E00-\u9FA5]")
line = rule.sub('', line)
return line
#停用词
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='gbk').readlines()]
return stopwords
#余弦相识度计算方法
def cosine_similarity(sentence1: str, sentence2: str,stopwords) -> float:
"""
:param sentence1: s
:param sentence2:
:return: 两句文本的相识度
"""
seg1 = [word for word in jieba.cut(sentence1) if word not in stopwords ]
seg2 = [word for word in jieba.cut(sentence2) if word not in stopwords ]
word_list = list(set([word for word in seg1 + seg2]))#建立词库
word_count_vec_1 = []
word_count_vec_2 = []
for word in word_list:
word_count_vec_1.append(seg1.count(word))#文本1统计在词典里出现词的次数
word_count_vec_2.append(seg2.count(word))#文本2统计在词典里出现词的次数
vec_1 = np.array(word_count_vec_1)
vec_2 = np.array(word_count_vec_2)
#余弦公式
num = vec_1.dot(vec_2.T)
denom = np.linalg.norm(vec_1) * np.linalg.norm(vec_2)
cos = num / denom
sim = 0.5 + 0.5 * cos
return sim
def main():
#读取数据
csv = '电力调度问答.csv'
file_txt = pd.read_csv(csv, header=0, encoding='gbk') # [205 rows x 2 columns]
file_txt = file_txt.dropna() # 删除空值[[205 rows x 2 columns]
#停用词加载
stopwords = stopwordslist("停用词.txt")
# 去除标点符号
file_txt['clean_review'] = file_txt['问题'].apply(remove_punctuation)
# 去除停用词
file_txt['cut_review'] = file_txt['clean_review'].apply(
lambda x: " ".join([w for w in list(jieba.cut(x)) if w not in stopwords and len(w) > 1]))
#所有问题组合起来的倒排表 result
result = {
}
for i in range(len(file_txt)):
left, rights = i, file_txt.iloc[i]['cut_review'].split()
for right in rights:
if right in result.keys():
result[right].append(left)
else:
result[right] = [left]
#用户问题
sentence=input('请输入问题:')
clean_reviewyonghu = remove_punctuation(sentence) # 用户问题去除标点
cut_reviewyonghu = [w for w in list(jieba.cut(clean_reviewyonghu)) if
w not in stopwords and len(w) > 1] # 用户问题去除停用词,单字词 得到关键词
#print(cut_reviewyonghu)
#查找用户问题关键词在数据库中对应的问题id
Problem_Id = []
for j in cut_reviewyonghu:
if j in result.keys():
Problem_Id.extend(result[j])
id = (list(set(Problem_Id))) # 去重之后的ID
#计算余弦相似度
str1 = sentence # 用户所提问题
similarity = {
} # 存储结果
if len(id) == 0:
print('数据库里没有该问题,请重新提问')
else:
for i in id:
str2 = file_txt.iloc[i]['问题']
sim1 = cosine_similarity(str1, str2,stopwords) # 余弦相识度
# print('用户所提问题和问题{0}的相似度是{1}'.format(i, sim1))
similarity[i] = sim1
#输出和用户问题相似度最高几个问题的答案
jieguo = sorted(similarity.items(), key=lambda d: d[1], reverse=True)[:2] # 降序
print(jieguo)
print('用户所提的问题是:', sentence)
for i, j in jieguo:
print('数据库相似的问题是{0} 答案是{1}'.format(i, file_txt.iloc[i]['答案']))
if __name__=='__main__':
main()

总结
这是一个简单的问答系统,现实生活中,该业务应该还包含语音
即先语音转换为文字, 然后 文本纠错,最后再进行问答系统。
我们需要的维护的就是数据库中的问题(即对应本文的问题答案表格)
问题越多,该问题系统效果就越好。
如果需要提升效果和速度,可以再修改停用词(本文给出的停用词针对所有文本,不是专门为电力设计的),使最后得到的关键词只包含电力领域的词。
再者修改结巴分词,使有的词不被分成单字。
可以再封装为软件,懒得再动手封装为界面软件啦,就不演示啦。
如果只做到倒排索引那一步即根据用户提出的问题,在数据库里找到啦相似问题,然后把相似问题和答案 一一展现出来就是一个搜索系统(类似于百度,输入一句话,弹出一大堆相关得东西)

电气工程的计算机萌新:余登武。写博文不容易。如果你觉得本文对你有用,请点个赞支持下,谢谢
我一个学电气的,怎么懂得这些。唉
