第一节 初始Series
为什么学习pandas:
因为pandas含有使得数据分析工作变得更快和更简单的高级数据结构和操作工具
因为pandas时基于numpy来进行构建的,让以numpy为中心的应用变得更加的简单。
1、Series类型说明
这个就是一直类似于一堆数组的对象,它是由一组数据以及一组与之相关的数据标签索引组成(索引)。仅由一组数据即可产生最简单的series。
obj=Series([1,2,3,4,5)
obj.values
obj.index
2、自定义索引
obj=Series(["a","b","c"],index=[1,2,3])
obj[1]: "a"
3、series可以当作字典使用
data={"a":10000,"b"":1000,"c"":2000}
obj=Series(data)
keys=["a","c"]
obj_1=Series(data,index=keys)#只取出字典中对应a和c的values
4、对缺失数据的处理
data={“a”:None,"b":20000}
obj=Series(data)
pd.isnull(obj)#判断是否为空
obj.isnull()
5、指定series name和index name
obj.name=""
obj.index.name=""
第二节:初始Dataframe
是一个表格型的数据结构,含有一组有序的列,每一列可以是不同值的数据类型,数值,布尔值,字符串都可以
dataframe既有行索引也有列索引
1、构建一个dataframe
data={
"60年代":["狗子","秀儿"],
"70年代":["魏国","爱国"]
}
frame=Dataframe(data)
print(frame["60年代"])
dates=pd.date_range("20190301",periods=6)
df=pd.Dataframe(np.random.rand(6,4),index=dates,columns=list("abcd"))
#对行的访问
df["20190301":"20190303"]
df.loc["20190301":"20190303"],["a","b"]#根据index和column查找
df.at[dates[0],"a"] #根据index和column查找
dataframe能够接收哪些数据类型:
- 1、二维numpy
- 2、由数组或者列表或者元组组成的字典
- 3、由series组成的字典
- 4、由字典组成的字典
- 5、由列表或元组组成的列表
- 6、另一个dataframe
第三节:重新索引,数学运算和数据对齐
1、reindex
obj=Series([4.5,5.8,-1.2],index=list("abc"))
job_1=obj.reindex(["a","b","c","d","e"],fill_value=0)#为空值进行填充
o=obj.reindex(range(6),method="ffill")#前向值填充,后向填充:bfill

2、算术运算和数据对齐
pandas的一个重要功能就是可以对不同索引的对象进行算术运算,在对象相加时,如果存在不同的索引对,则结果的索引就是该索引的并集
不重叠的地方补nan
df1=Dataframe(np.arange(9).reshape((3,3)),columns=list("abc"),index=[1,2,3])
df2=Dataframe(np.arange(12).reshape((4,3)),columns=list("cde"),index=[1,2,3,4])
df1+df2
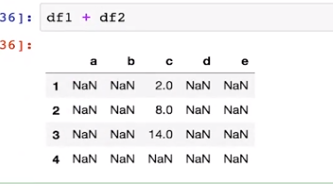
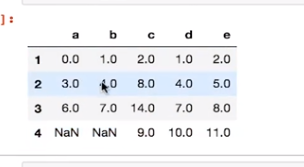
df1.add(df2,fill_value=0)#用0填充不重叠的值,如果本身位置为空,那么还是空
第四节 dataframe和series的运算,及排序
1、运算
frame=Dataframe(np.arange(12).reshape((4,3)),columns=list("bde"),index=[1,2,3,4])
series=frame.loc[1] #选取frame中索引为1的一行数据
frame-series#广播相减

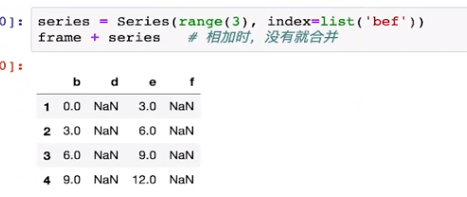
series=Series(range(3),index=list("bef"))
frame+series#没有合并
obj.sort_index()
obj.sort_values()
针对dataframe根据任意一个轴的索引进行排序
frame.sort_index(axis=1)
针对每一个columns排序:

第五节 层次化索引
层次化索引是pandas的一项比较重要的功能,能够让你在一个轴上拥有多个索引级别,另一种说法是能够以低维处理高纬度数据


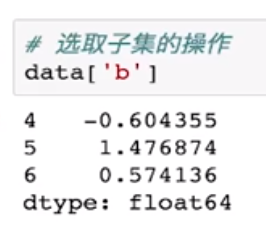
选取子集的操作
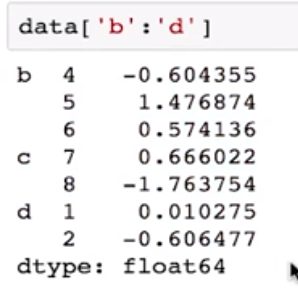
内层选取

使用unstack方法可以把生成新的dataframe
每条轴都可以由分层索引

第五节:读取csv文件
import pandas as pd
pd.read_csv()#默认分隔符为逗号
pd.read_table("dir",sep=",")#默认分隔符为“\t”
pd.read_fwf()#读取固定格式的宽列格式的数据
pd.read_clipboard()#读取剪切板中的数据
pd.read_csv("dir",header=None)#不要源文件的columns
pd.read_csv("dir",index_col="c")#指定c列为索引列
pd.read_csv("dir",index_col=["c","d"])#指定多列层次化索引
pd.read_csv("dir",skiprows=[1])#不读取指定行
pd.isnull()#判断每个位置是否为空
#大文件如何读取:
pd.read_csv("dir",nrows=5)#指定读取多少行
#写入文件
data=pd.read_csv("dir",nrows=5)
data.to_csv("dir",sep="\t")#将data制为csv
5.1 pandas读取excel文件并画图
excel=pd.read_excel("dir",sheet_name="工作表2")#读取指定工作表
p1=excel.plot(kind="scatter",x="age",y="place").git_figure()
p1.savefig("1.png")#保存png格式
第六节:matplotlib可视化操作
import matplotlib.pyplot as plt
import numpy as np
plt.plot(np.arange(10))
plt.show()
#添加子图
fig=plt.figure()
ax1=fig.add_subplot(2,2,1)
ax2=fig.add_subplot(2,2,2)
ax3=fig.add_subplot(2,2,3)
ax4=fig.add_subplot(2,2,4)
plt.show()
plt.plot(np.random.randn(50).cumsum(),"k--")#灰色
ax1=plt.hist(np.random.randn(100),bins=20,color="k",alpha=0.3)
ax2=plt.scatter(np.arange(30),np.arange(30)+3*np.random.randn(30))
plt.show()
series 画图
s=pd.Series(np.random.randn(10).cumsum())
print(s)
s.plot()
plt.show()