文章目录
信息抽取介绍 Information Extraction
1、信息抽取概要 (IE)
Extraction information from unstructured text(非结构化数据)
- 图片
- 文本
- video
- 音频
抽取实体(entities):
- 人,地名,时间
- 医疗领域:蛋白质,疾病,药物
抽取关系(relations)
- 位于 located in
- 工作在 work at
- 部分 is part of
先做实体抽取,再做关系抽取
2、信息抽取应用场景
2.1 一个例子
- 1、NER: 标记所有的实体和每个实体的类别
- 2、**关系抽取分析:**找到实体间的关系
- 3、指代消解,每个代词指代的是哪个名词。

2.2 More application
- 知识库的搭建
- Google scholar
- 购物引擎,产品搜索
- 正确分析
- 问答案系统
2.3 Search Engine vs Question Answering
- Question Answering:用户输入问题,系统直接给定answer
- Search Engine:用户需要自己筛选
问答系统的等级
- level 1: 返回文档
- level 2:返回关键句子
- level 3:返回key phrase
- level 4: 返回答案
3、命名实体识别介绍
3.1 概念
命名实体识别,简称NER,又称作专名识别,是指识别文本中具有特定意义的实体,主要包括任命,地名,机构名,专有名词等。
3.2 Case 1: Chat bot
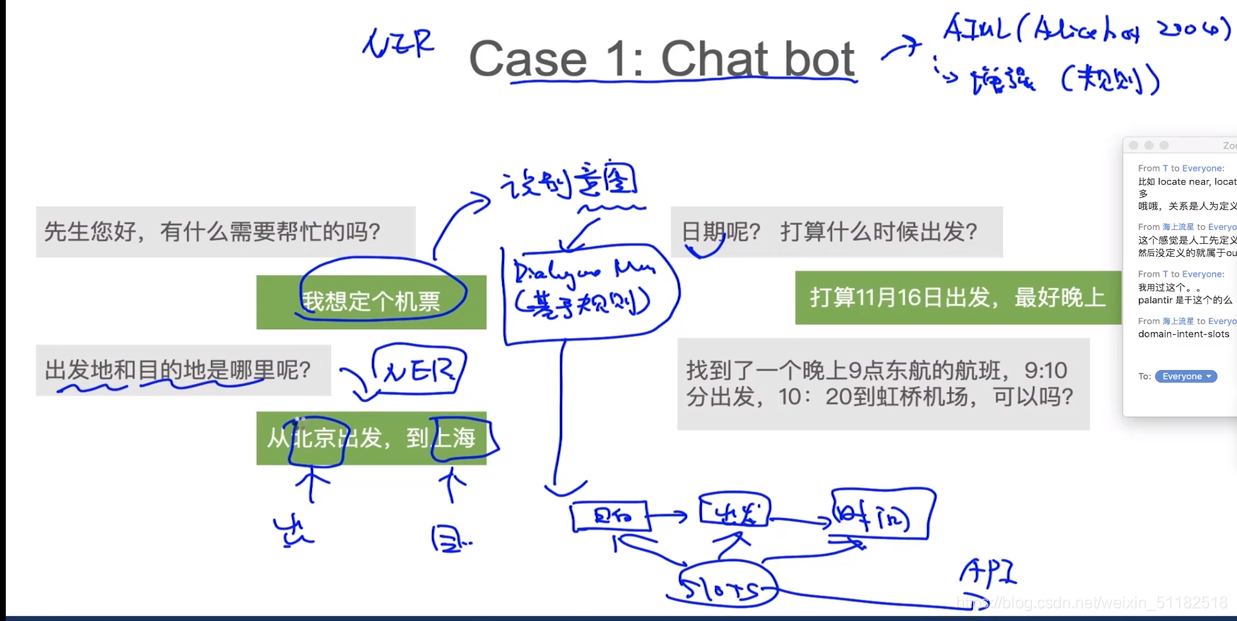
先做意图识别:文本分类
第一次抽取实体:北京,伤害
第二次抽取实体:11月16日
3.3 Case 2:Extract from news


4、搭建命名实体识别 NER分类器
- 定义实体种类
- 准备训练数据
- 训练NER
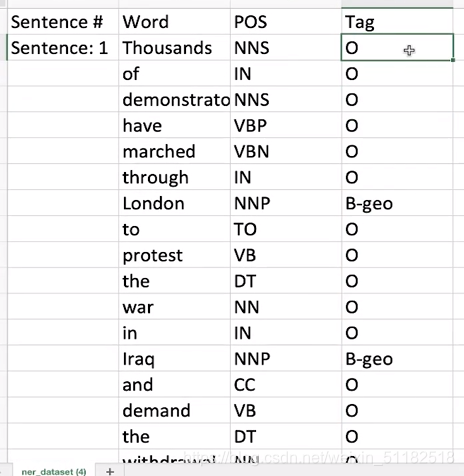
给定word, 词性和实体类别,O为不需要关注的单词,多个单词构成一个实体类别。
4.1 评估 NER Recognizer
- 精确率和召回率
- F1-score
4.2 Methods
4.2. 1 rule-based approach 利用规则

4.2.2 Majority voting approach 投票表决

选择概率最大的实体类型
4.2.3 基于监督学习的方法
- 1、非时序模型,逻辑回归,svm
- 2、时序模型:HMM,CRF, LSTM-CRF
针对一个单词,使用特征工程,提取特征,得到feature vector,输入到模型得到分类结果。
比如,应用随机森林进行分类,将一个单词是否是标题,是否有大写,它的词长度等作为feature,输入到模型进行训练,得到分类结果。这种特征提取没有考虑上下文信息。
5、文本的特征工程
对于一个句子的特征提取: The professor Colin proposed a model for NER in 1999
1、Bag-of-word features
- 当前词:Colin:
- 前后词:professor,proposed
- 前前,后后词:the, model
- Bi-gram: Professor Colin,Colin proposed,the professor, proposed model
2、词性的feature
- 当前词词性:名词
- 前后词词性:名词,动词
- 前前后后词性:冠词,名词
3、前缀后缀
- 当前词:Co,in
- 前后词:pr,or;pro, ed
4、当前词的特性
- 词长
- 包含有多少个大写字母
- 是否大写开头
- 是否包含“-”
- 是否包含数字
5、 stemming
对单词做stemming后重复上面四个操作
6、特征编码 Feature Encoding
对于当前词的词性:Loc,需要把这个词性转变为one-hot encoding,但会使特征的维度变大很多很多。
常见的特征种类:
1、类别型的特征,使用one-hot encoding
- 男女
- 动词,名词
2、连续性的特征
- 身高
- 温度
可以直接使用做归一化,还可以转为高斯分布N(0,1)
做discretize,按区间做分类。

3、Ordinal Feature 与ranking 相关的

通过特征只能了解到顺序,但无法了解具体的差别。一个同学考试拿A,一个拿B,不知道他们具体差了多少
- 方法1:直接使用
- 方法2:当作categorical feature使用

7、关系抽取介绍
7.1信息抽取任务:
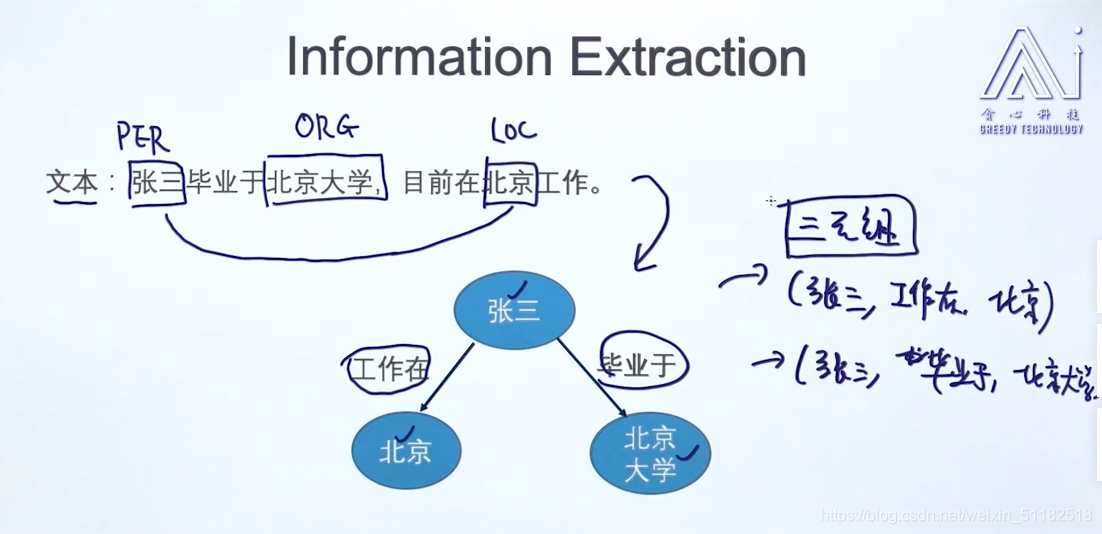
通过NER抽取出张三,北京大学和北京三个实体
使用三元组保存实体之间的关系。——RDF Store

7.2 Automatic Content Extraction(ACE)
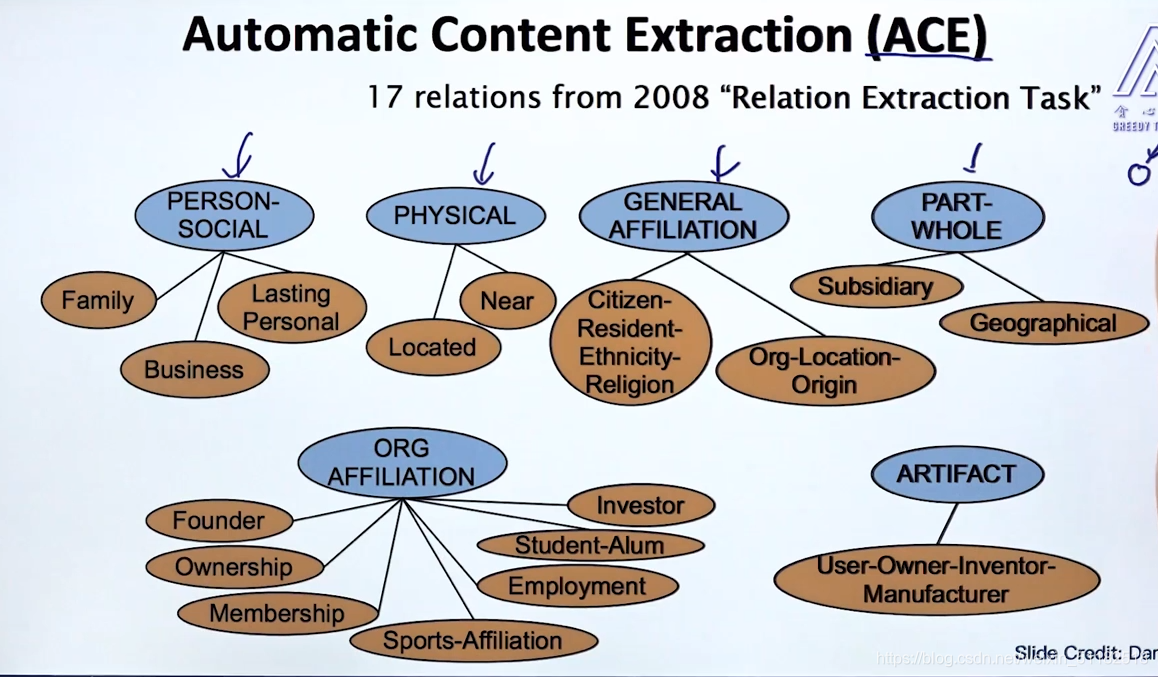
知识图谱:包含多种关系类型+包含多种实体类型
Ontological Relation(本体关系)
- IS-A (hypernym relation)
- instance-of
7.3 关系抽取方法介绍
1、基于规则
2、监督学习
3、半监督-无监督学习
- Boostrap
- Distant Supervision
- 无监督学习
8、基于规则的方法
8.1 举例 “is-a”


8.2 Benefits and Drawbacks
优点:
- 准确
- 不需要训练数据
缺点:
- low recall rate
- 人力成本
- 规则本身难设计
9、基于监督学习方法
1、定义关系类型
2、实义实体类型
3、训练数据准备
- 实体标记好
- 实体之间的关系
同时考虑两个单词的特征,构造特征放入算法进行分类。
9.1 特征工程
1) Bag of word feature:
American Airline, Tim Wanger,以及bigram,trigram特征
2)中间部分特征
a unit of Amr, immediately, match the move, spokesman
3) pos feature:词性相关特征
名词/动词/,也可以加入bigram或者中间部分的词性
4)实体类别特征
American Airline: OGR
Tim Wanger: PER
5) Stemming
6)位置相关信息
- 两个实体间包含了多少个单词?
- 这句话在本文中的位置
7)句法分析相关特征
计算两个节点之间最短路径
8)依存文法相关
w1,w2,w3,w4,w5
分析出每个单词和其他单词的关系
- shortest path
- 0/1
9.2 Classification Model

SVM,神经网络

- 先做二分类,看单词之间有没有关系:k+1类
- 如果有关系,再用模型2做多分类问题:k类
- 模型会更加简单,大部分的实体会被model1 过滤掉
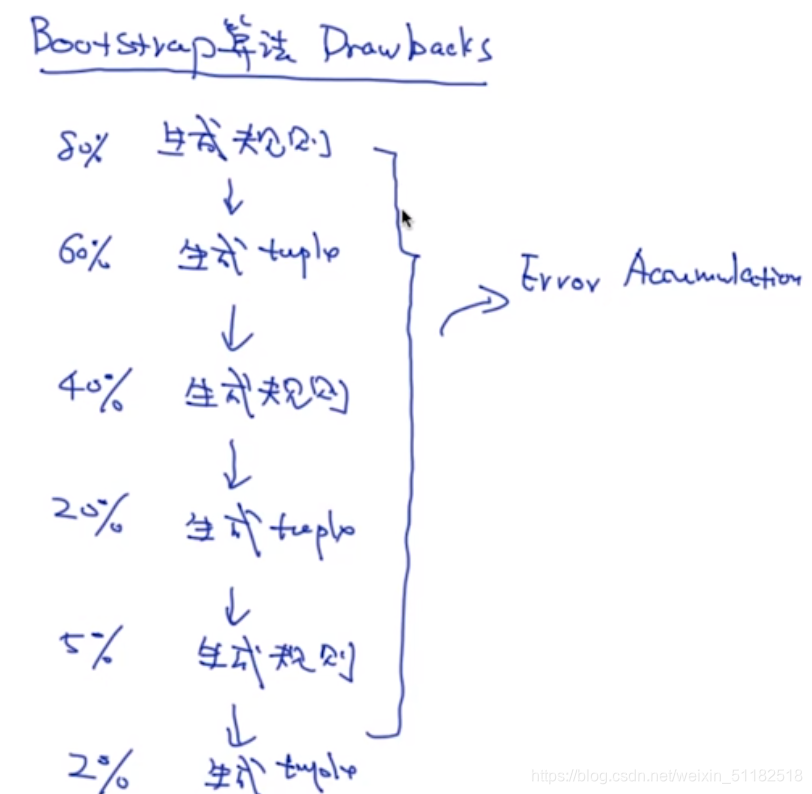
10、Bootstrap 方法
10.1 Bootstrap

- 使用有限的tuple去生成一些规则
- 使用规则去生成额外的tuple
- 再使用原有的tuple和生成的tuple去重复上述步骤
- 直到训练出很多很多的tuple和规则
优点:全自动的过程
算法的缺点:
- error accumulation,随着循环,误差会提高,准确率在经过三次迭代后,严重下降。
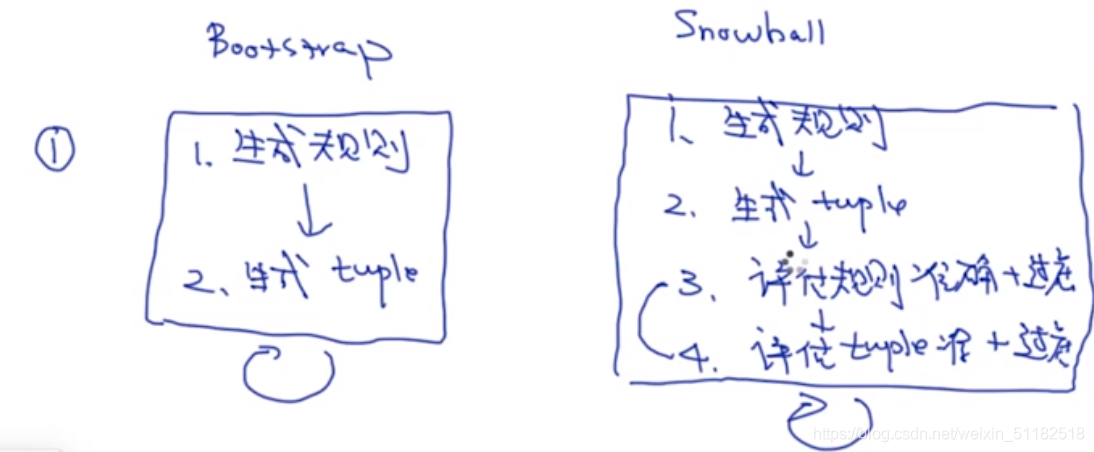
10.2 Snow ball
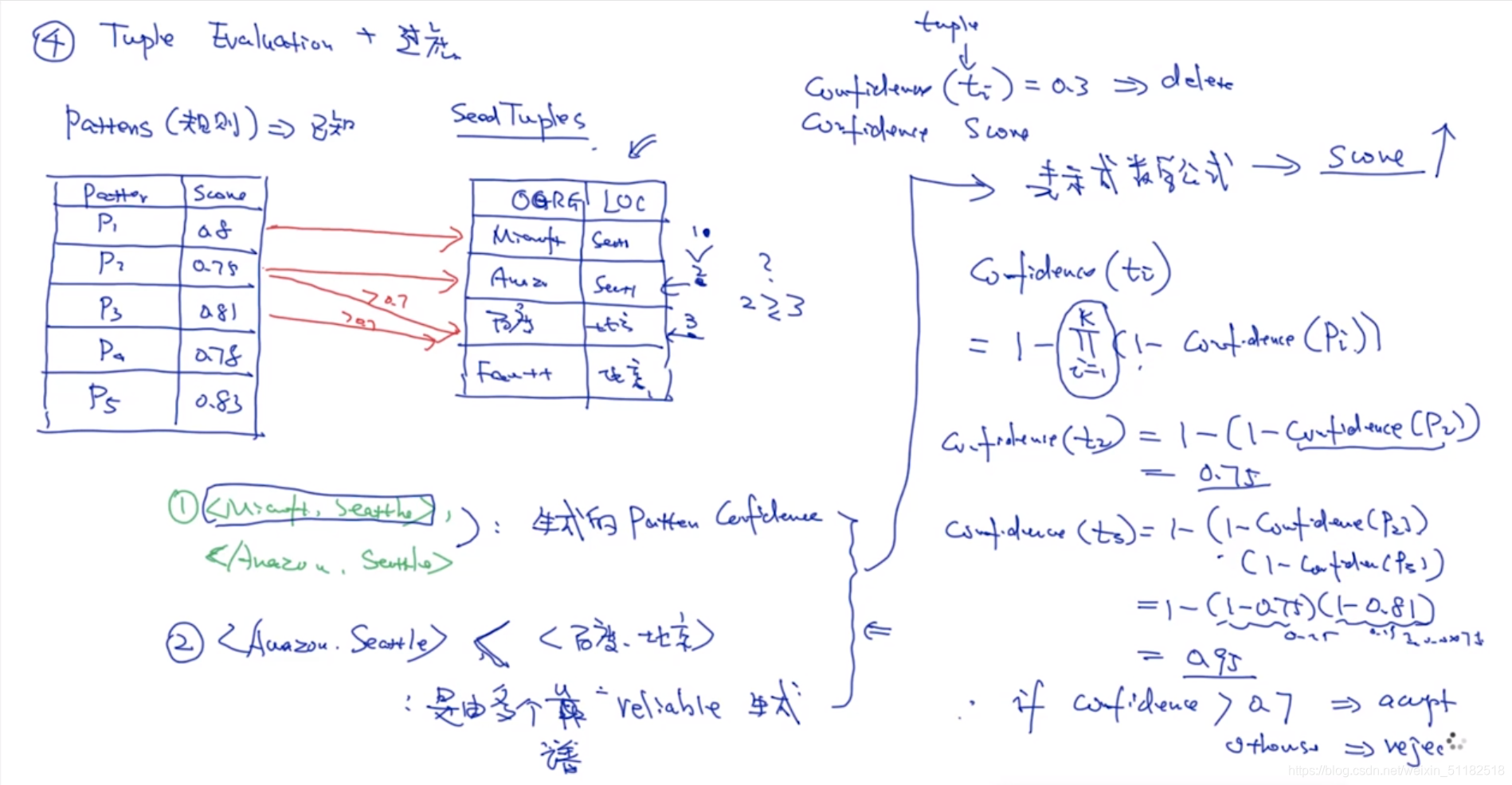
step 1:生成规则
从文章中寻找在tuple中的实体,标记规则。使用近似匹配的算法,计算规则和规则之间的相似度,规则和tuple之间的相似度。
snow ball 的核心:使用模板
pattern representation:五元组算法
< left >[org]< middle > [loc]< right>
如何计算相似度

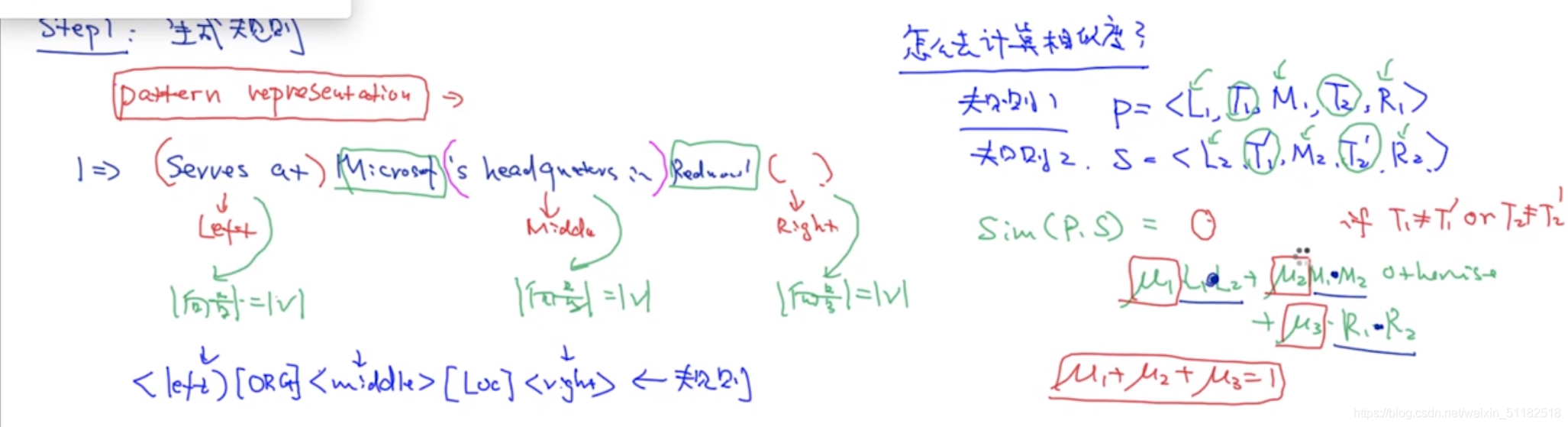
- 如果两个实体不一样,相似度为0。
- 如果实体类型一样,计算相似度。
step2:生成模板
使用聚类,对每个模板做分类,使相似度比较高的模板聚类在一起。

将每一个类中的模板取平均值作为一个新的模板。
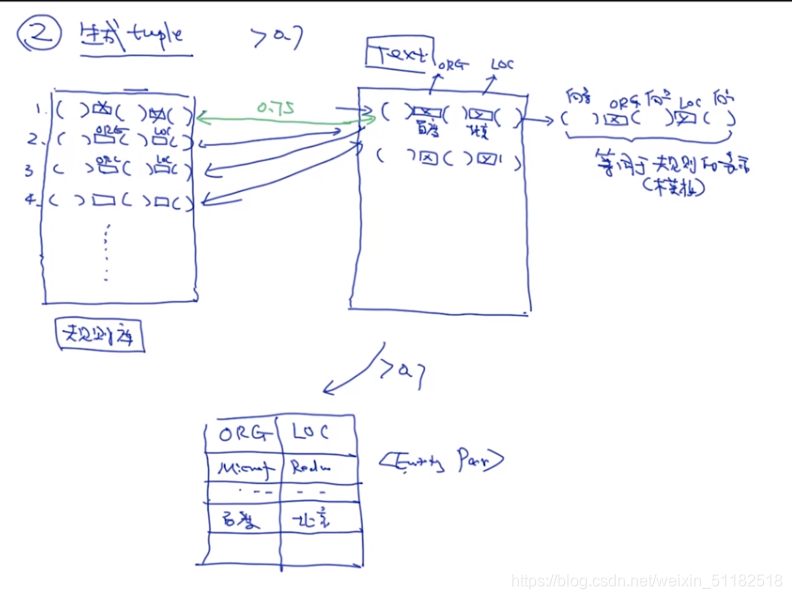
step 3: 生成tuple与模板评估
根据生成的规则匹配在文章中生成新的tuple
规则里面的指的是实体类型
在生成tuple的过程中也要使用五元组表示法,生成tuple的过程就是计算与规则库中规则的之间的相似度
step 4: pattern evaluation
选择一个模板,只用这个模板,对一个文档生成一些tuples,与seed tuples对比计算confidence,如果confidence值小于阈值,就把该模板从规则库中去掉。

step 5:评估记录+过滤:tuple evaluation
计算confidence(tuple)
已知:seed tuples是由规则库中的哪个规则产生的。
对比两个tuple的confidence就是对比生辰他们的规则的confidence哪个更高
如果一个tuple是由多个靠谱的规则生成的,那么该tuple的confidence一定比只由一个规则生成的更靠谱。
10.3 snowball 总结
- 1、信息抽取领域重要的部分
- 2、细节和流程
- 3、pattern representation,confidence score,五元组
11、Distant-supervision方法
12、无监督学习
13、实体消歧 Entity Disambiguiation
实体消歧的本质:一个词可能有多个意思,也就是在不同的上下文中所表达的含义不太一样
13.1 介绍

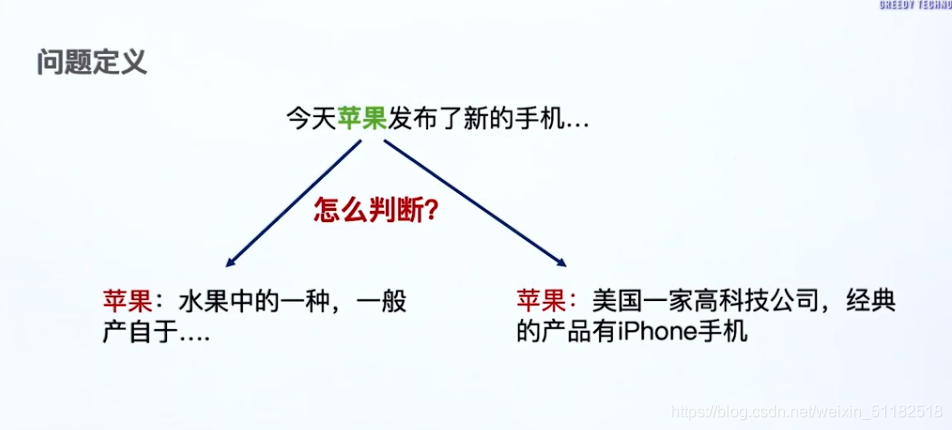
13.2 实体消歧算法
将query使用tf-idf转为向量,与苹果的两个定义计算余弦相似度,选择更大的相似形的定义

14、实体统一 Entity Resolution

在数据清洗中是很重要的部分
14.1 实体统一算法
问题定义:给定两个实体,判断是否是指向同一个实体:0/1二分类问题
举例:给定两个实体,字符串的形状 str1,str2:判断是否指向同一个实体
1、方法一:计算两个str的相似度:edit distance
2、方法二:基于规则

根据给定规则的表格删除str中出现的字符串元素。
3、方法三:有监督学习的方法
一篇文章出现百度有限公司,百度科技公司,标记其属于同一类。提取特征:单词本身,单词上下文。

4、基于图的实体统一:个体特征加关系相关特征
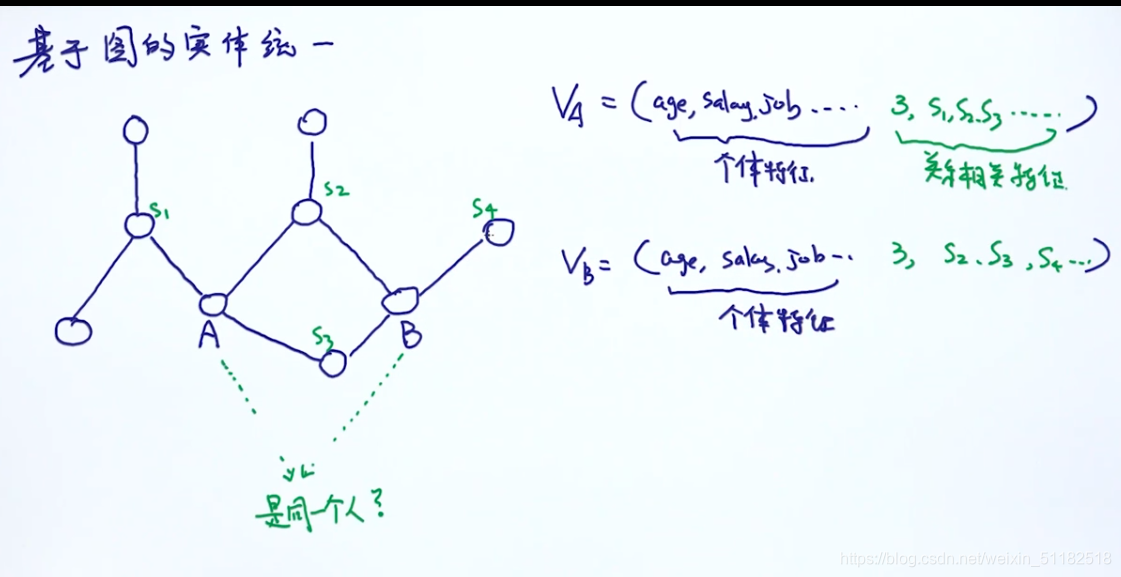
通过相似度计算设置阈值,判断它们是否是个实体
如果是,就做merge
如果不是,remain
15、指代消解
15.1 举例
张三没有去上班,因为生病了,昨天李四陪他去了医院,好消息是,他已经好了。 将他看作一个二分类问题。
- 1、最简单的方法:分类成离他最近的实体
- 2、supervised learning:
15.2 收集数据
1)收集数据
2) 构造分类器

考虑(张三,A) 为1的这一组数据,将张三和他在文本中出现的位置中间的,张三左边的,他右边的几个字符串转换为向量的形式。
16、句法分析 —— Parsing
16.1 介绍
理解一个句子,两种方法:
- 从句法分析的角度理解一个句子(主谓宾)
- 感觉,基于语言模型
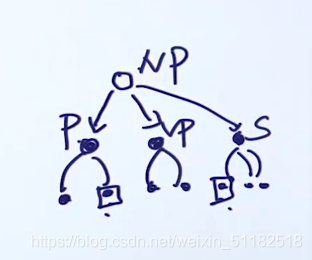
16.2 语法树
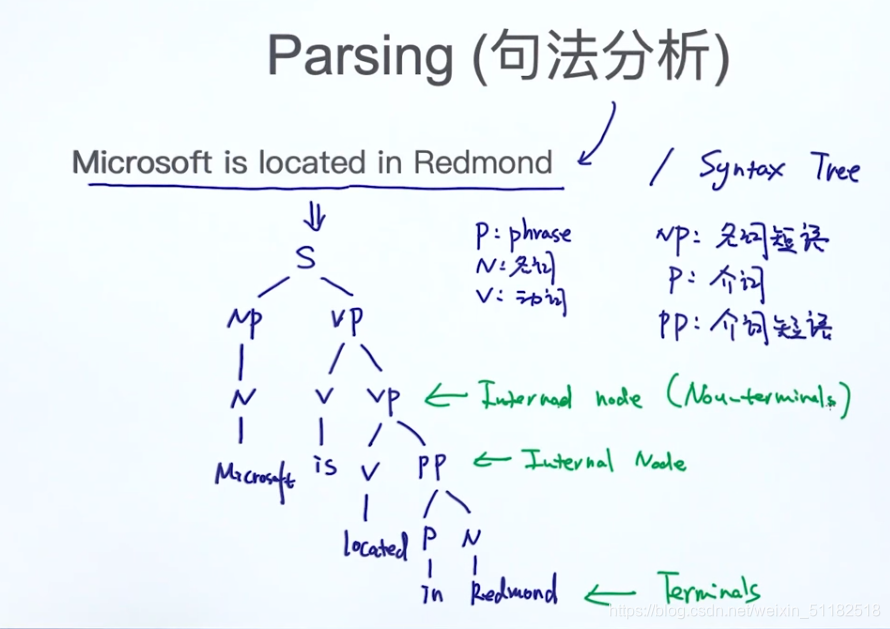
- p: phrase
- N:名词
- V:动词
- NP:名词短语
- P:介词
- PP:介词短语
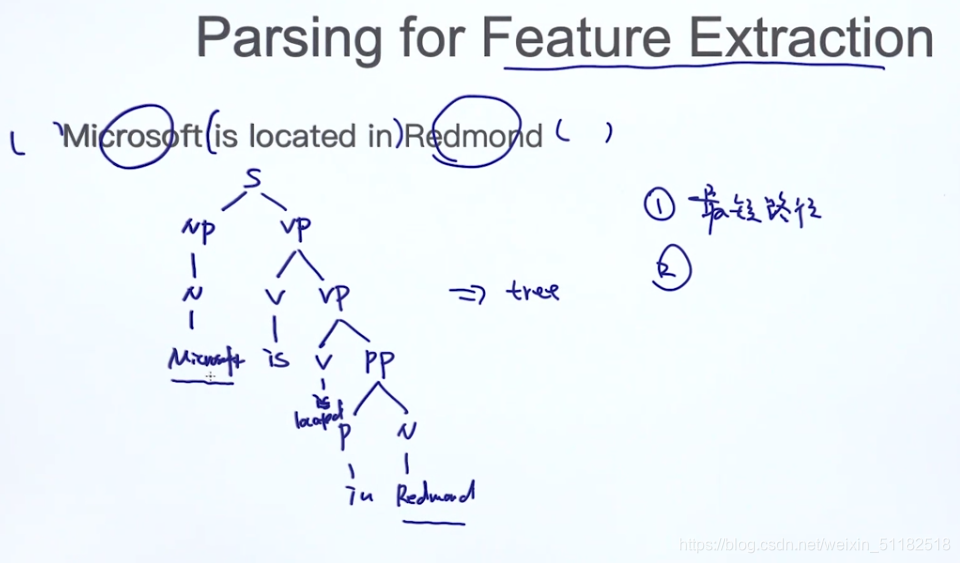
16.2 Parsing for Feature Extraction
- 1、最短路径
- 2、路径上的符号
16.3 语法
什么样的条件下可以把句子转换成语法树?

右边的都是终结符号,只要没遇到终结符号,就可以一直向下分类。
16.4 From CFG(context free grammars) to PCFG (probablistic context free grammars)

每一个中间结点的再向下分的类型都会有一定概率
16.5 评估语法树
目的:给定一个grammar,把一个句子转换成语法树

16.6 寻找最好的数
- 1、枚举所有可能的句法树,时间复杂度很大
- 2、CKY算法:核心理念就是动态规划
17、CKY 算法
17.1 CKY 算法核心思想
Binarization is the Key,规则的右边只能出现两个不同的符号。
17.2 Transforming to CNF(chosmsky normal form)
- 不能允许出现1个符号
- 不能允许出现两个以上的符号
remove e会产生很多新的规则
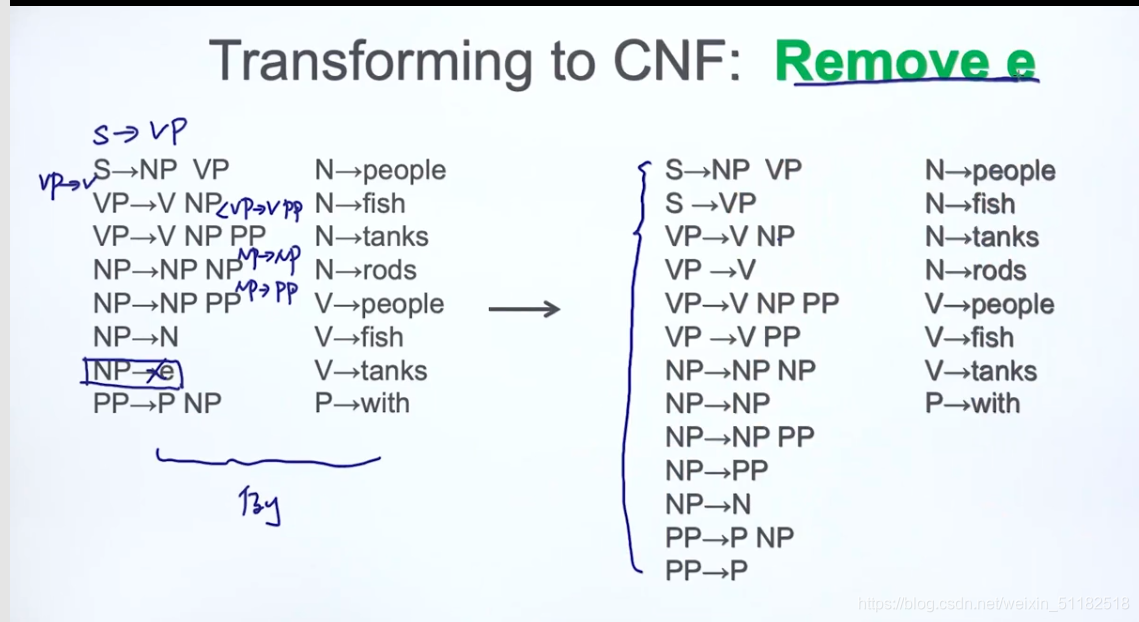
remove unaries
s …> vp,把s看作vp

继续去掉unaries

删除掉unaries后,右边的词性对照的单词数量增多

到此为止,右边没有出现unaries和e
如果出现三个,就把两个定义成新的变量,新的变量再指向原先的两个词性

红色部分为CNF form
- about CKY
1、必须符合binarization
2、其他的条件不是必须的
17.3 CKY算法
给定一个句子, fish people fish tanks
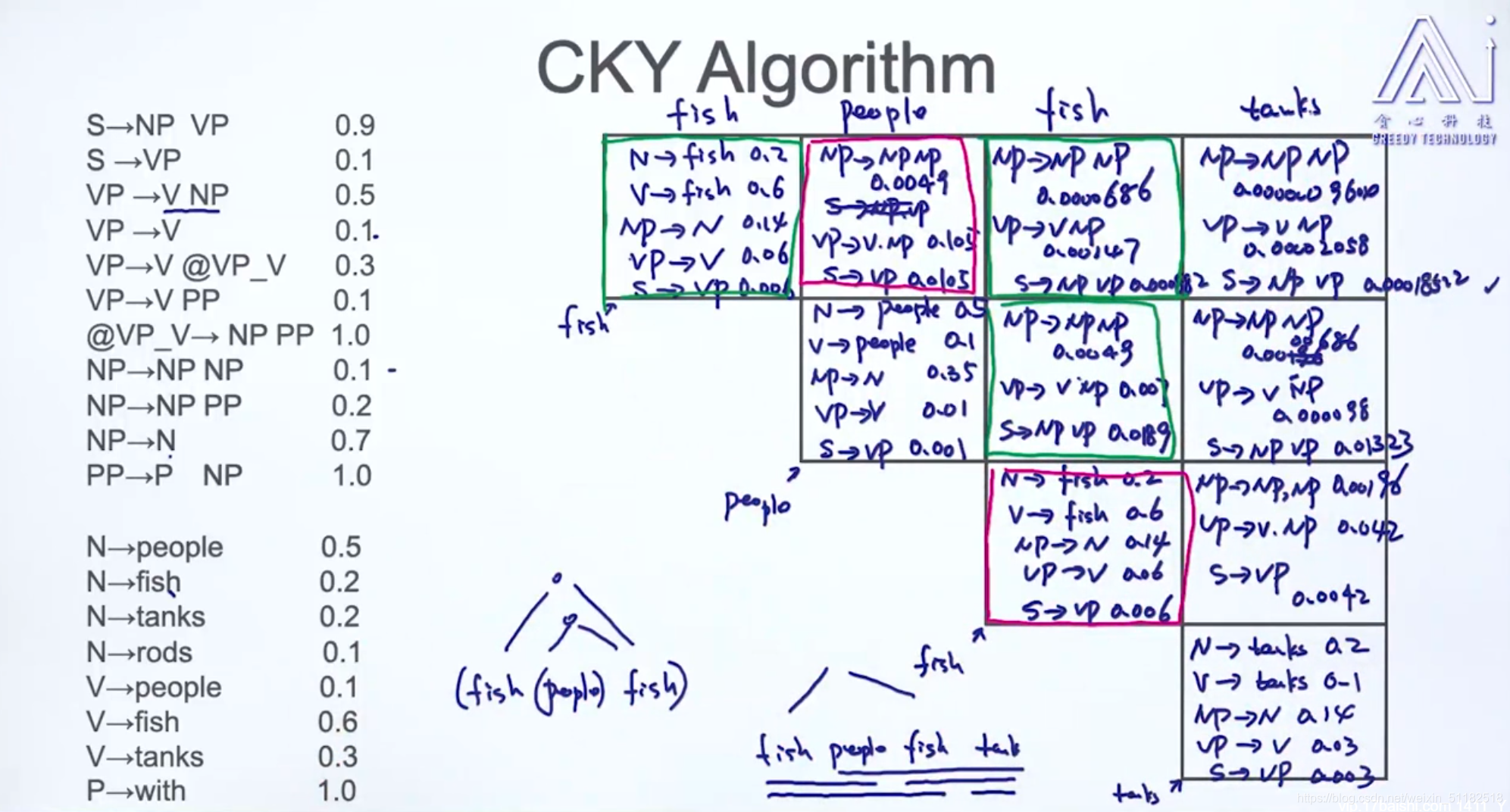
把一棵树从叶节点开始慢慢生成。