文章目录
Li, Z., et al. (2019). Chinese Relation Extraction with Multi-Grained Information and External Linguistic Knowledge. Proceedings ofthe 57th Annual Meeting ofthe Association for Computational Linguistics: 4377–4386.
code
Abstract
中文关系提取是使用具有基于字符character或基于词word的输入的神经网络进行的,并且大多数现有方法通常遭受分段错误和多义性的模糊性。为了解决这些问题,我们提出了一种用于中文关系提取的多粒度点阵框架(MG点阵),以利用多粒度语言信息和外部语言知识。在这个框架中,(1)我们将字级信息合并到字符序列输入中,以便可以避免分段错误。 (2)借助外部语言知识,我们还对多义词的多重感知进行建模,以减轻多义歧义。与其他基线相比,在不同域中的三个真实世界数据集上的实验显示了我们模型的一致且显着的优越性和稳健性。
- Chinese NRE(MG lattice多粒度点阵)
- 中文关系抽取
- 神经网络
- 多粒度
- 基于字符+基于词
- 解决的问题:
- 分段错误(分词?)
- 多粒度:将词级信息融入到字符序列输入中
- 多义性
- 借助外部语言库
- open-sourced HowNet API (Qi et al., 2019)
- 分段错误(分词?)
1.Introduction
关系提取(RE)在信息提取(IE)中具有关键作用,旨在提取自然语言句子中实体对之间的语义关系。在下游应用中,该技术是构建大规模知识图的关键模块。深度学习的最新发展提高了对神经关系提取(NRE)的兴趣,NRE试图使用神经网络自动学习语义特征(Liu et al。,2013; Zeng et al。,2014,2015; Lin et al。, 2016; Zhou等,2016; Jiang等,2016)。
- NRE–神经网络
- Liu et al。,2013;
- Zeng et al。,2014,2015;
- Lin et al。, 2016;
- Zhou等,2016;
- Jiang等,2016
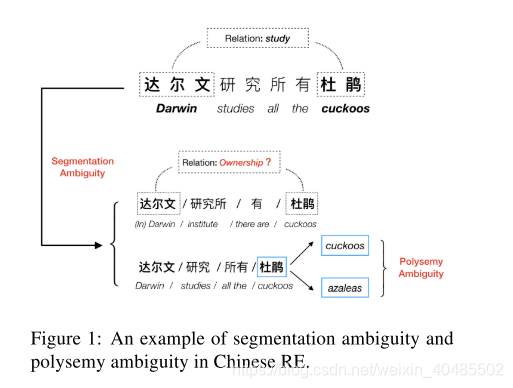
虽然NRE没有必要执行特征工程,但他们忽略了这样一个事实,即输入的不同语言粒度将对模型产生重大影响,特别是对于中文RE。传统上,根据粒度的不同,中国RE的大多数现有方法可以分为两种类型:基于字符的RE和基于字的RE。
- 输入粒度影响大:
- 基于字符
- 它将每个输入句子视为字符序列。这种方法的缺点是它不能充分利用字级信息,捕获的功能少于基于字的方法。
- 基于word
- 应首先执行分词。
- 然后,导出一个单词序列并将其输入神经网络模型。
- 但是,基于单词的模型的性能可能会受到分词质量的显着影响。
- 近平其一,难以获得充分的语义信息
- 基于字符
此外,数据集中存在许多多义词的事实是现有RE模型忽略的另一个点,这限制了模型探索深层语义特征的能力。例如,“杜鹃”这个词有两种不同的含义,分别是“杜鹃”和“杜鹃花”。但是,如果没有外部知识的帮助,从普通文本中学习含义信息是很困难的。因此,引入外部语言知识将对NRE模型有很大帮助。
- 多义词:
- 从文本中难以得知
- 需要引入外部语言知识
2.相关工作
近年来,RE,特别是NRE,已在NLP领域得到广泛研究。作为先驱,(
- Liu et al。,2013)提出了一个简单的CNN RE模型,它被认为是一个开创性的工作,它使用神经网络自动学习特征。
- 在此基础上,(Zeng et al。,2014)开发了一种具有最大池的CNN模型,其中位置嵌入首先用于表示位置信息。然后,
- PCNNs模型(Zeng et al。,2015)为RE设计了多实例学习范例。但是,PCNNs模型存在选择句子的问题。
- 为了解决这个问题,Lin等人。 (2016)将注意机制应用于包中的所有实例。
- 此外,Jiang等人。 (2016)提出了一个具有多实例和多标签范例的模型。
- 虽然PCNNs模型更有效,但它们无法利用像RNN这样的上下文信息。因此,
- 具有注意机制的LSTM也应用于RE任务(Zhang和Wang,2015; Zhou等,2016; Lee等,2019)。
中国RE的现有方法主要是基于字符或基于单词的主流NRE模型的实现(Chen和Hsu,2016;Rénqvist等,2017; ZHANG等,2017; Xu等,2017)。在大多数情况下,这些方法只关注模型本身的改进,忽略了不同粒度的输入将对RE模型产生重大影响的事实。基于字符的模型不能利用单词的信息,捕获比基于单词的模型更少的特征。另一方面,基于单词的模型的表现受到细分质量的显着影响(Zhang and Yang,2018)。虽然有些方法用于将角色级别和单词级别信息结合在其他NLP任务中,如字符 - 双子星(Chen et al。,2015; Yang et al。,2017)和软词(Zhao和Kit,2008; Chen等)。 al。,2014; Peng和Dredze,2016),信息利用率仍然非常有限。
- 中文NRE
- 未考虑粒度
- Chen和Hsu,2016;Rénqvist等,2017; ZHANG等,2017; Xu等,2017)
- 多粒度
- haracter-bigrams (Chen et al., 2015; Yang et al., 2017) and
- soft words (Zhao and Kit, 2008; Chen et al., 2014; Peng and Dredze, 2016)
- 未考虑粒度
- 树LSTM
- lattice LSTM
- 可处理多粒度
- 无法处理多义词
- HowNet proposed by Dong and Dong (2003)
- 引入外部语言库
- 本文中使用: open-sourced HowNet API (Qi et al., 2019)
泰等人。 (2015)提出了一种树状LSTM模型来改进语义表示。这种类型的结构已经应用于各种任务,包括人类行为识别(Sun et al。,2017),NMT编码器(Su et al。,2017),语音标记化(Sperber et al。,2017)和NRE(Zhang和杨,2018年)。虽然lattice LSTM模型可以利用单词和单词序列信息,但它仍然可能受到多义词模糊性的严重影响。换句话说,随着语言情境的变化,这些模型无法处理单词的多义词。因此,引入外部语言知识是非常必要的。我们在Dong和Dong(2003)提出的知网的帮助下利用感知级信息,这是一个概念知识库,用相关的词义来注释中文。此外,我们的工作中也使用了开源的HowNet API(Qi et al。,2019)。
3. 方法
给定一个中文句子和两个标记实体,中文关系提取的任务是提取两个实体之间的语义关系。在本节中,我们将详细介绍用于中文关系抽取的MG点阵模型。如图2所示,该模型可以从三个方面介绍:输入表示。给定具有两个目标实体作为输入的中文句子,该部分表示句子中的每个单词和字符。然后,该模型可以利用单词级和字符级信息。
- MG lattice chinese NRE
- 输入表示
- 输入:给定含有两个目标实体的句子作为输入
- 表示:每个词和字
- 这个模型可以利用这两个信息
- MG lattice 编码器
- lattice LSTM
- 将外部知识结合到词义消歧中,
- 为每个输入实例构建分布式表示。
- 关系分类器
- 在学习隐藏状态之后,字符级机制用于于合并特征。
- 然后将最终的句子表示输入softmax分类器以预测关系。
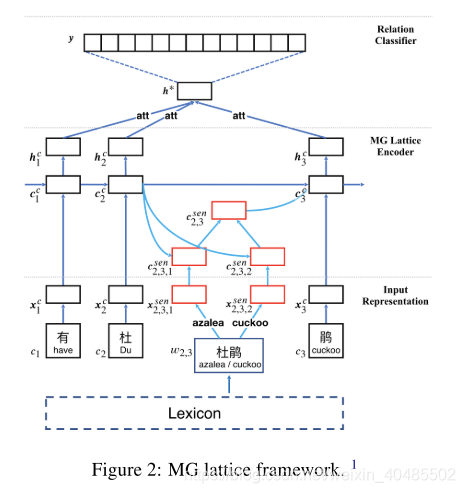
- 输入表示
3.1 输入
3.1.1 字符级别表示
- 每个字的嵌入->一个句子
- Skip-gram model (Mikolov et al., 2013).
- 位置嵌入position feature–
- 最终输入
3.1.2单词级表示
虽然我们的模型将字符序列作为直接输入,但为了完全捕获字级特征,它还需要输入句子中所有潜在单词的信息。这里,潜在的单词是任何字符子序列,它匹配在分段的大原始文本上构建的词典D中的单词。让成为从第b个字符到第e个字符的子序列。为了表示,我们使用word2vec(Mikolov等,2013)将其转换为实值向量。
- 文本中所有出现在词典上的单词–>word2vec–>向量表示
- word2vec:不考虑多义词
- 用HowNet作为外部知识库纳入model–>一个含义对应一个向量
- 操作
- 给定单词
- 通过HowNet检索,得到他的K个含义
- 每个含义映射到一个向量
(SAT模型,基于skip-gram)
- SAT (Sememe Attention over Target)
- 得到他的含义向量集合:
- 这就是 的表示
3.2encoder
- 编码器的
- 直接输入:是字符序列,以及词典D中的所有潜在单词。 all potential words in lexicon D
- 训练之后,编码器的输出 :是输入句子的隐藏状态向量h。
- 我们引入了两种策略的编码器,包括
- 基本晶格LSTM(lattice)
- 多晶格(MG晶格)LSTM。
3.2.1 base lattice LSTM encoder
- 基于字符的LSTM
- base lattice LSTM encoder(在上面基本LSTM的基础上)
- 为了控制每个词的贡献,需要额外的门:
- 最后得到隐层表示
3.2.2 MG lattice LSTM encoder
- base lattice LSTM encoder
- 一个单词一个向量,不考虑多义词
- 最后得到隐层表示
3.3 关系分类器
- 上面得到了字符级的h
- attention连接:
- 概率
- 损失函数
4.实验
在本节中,我们对三个手动标记的数据集进行了一系列实验。与其他型号相比,我们的模型显示出优越性和有效性。此外,泛化是我们模型的另一个优点,因为有五个语料库用于构建三个数据集,这些数据集在主题和写作方式上完全不同。实验将按如下方式组织:(1)首先,我们通过将基于字符和基于字的模型进行比较,研究模型将字符级和字级信息结合起来的能力; (2)然后我们关注感知表示的影响,在三种不同的基于格子的模型中进行实验; (3)最后,我们在关系提取任务中与其他提出的模型进行了比较。
- 本模型特点:泛化性
4.1数据集
- 中文的数据集
- Chinese SanWen (Xu et al., 2017),
- 包含837篇中国文献文章中的9种关系类型,其中695篇文章用于培训,84篇用于测试,其余58篇用于验证。ACE 2005数据集是从新闻专线,广播和网络日志中收集的,包含8023个关系事实和18个关系子类型。我们随机选择75%来训练模型,剩下的用于评估。
- ACE 2005 Chinese corpus (LDC2006T06)
- FinRE.
- 为了在测试域中实现更多样化,我们在新浪财经2中手动注释来自2647个财务新闻的FinRE数据集,分别用13486,3727和1489个关系实例进行培训,测试和验证。FinRE包含44个不同的关系,包括特殊关系NA,表示标记的实体对之间没有关系。
- Chinese SanWen (Xu et al., 2017),
4.1.2 评估
- precision-recall curve,
- F1-score,
- Precision at top N predictions (P@N) and
- area under the curve (AUC).
4.1.2 超参数设置
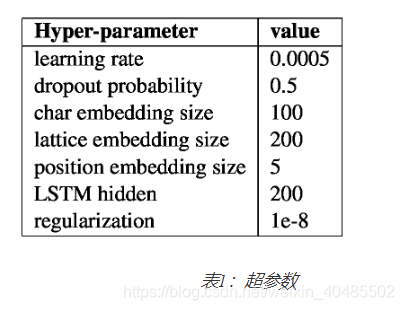
- 通过使用验证数据集上的评估结果提前停止来选择最佳模型。对于其他参数,我们遵循经验设置,因为它们对我们模型的整体性能几乎没有影响。
- F1
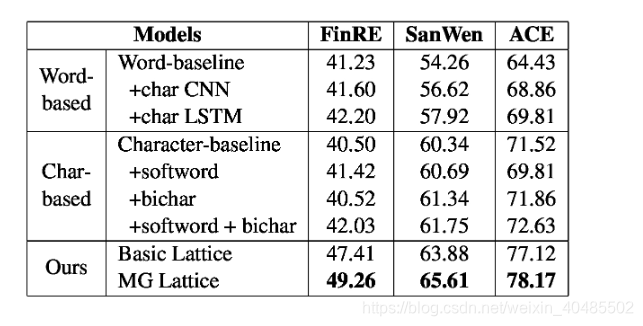
4.2lattice的作用
在这一部分中,我们主要关注编码器层的效果。如表2所示,我们在所有数据集上对基于char,基于单词和基于点阵的模型进行了实验。通过用双向LSTM替换晶格编码器来实现基于字和基于字符的基线。此外,字符和单词功能分别添加到这两个基线,以便它们可以同时使用字符和单词信息。
对于单词基线,我们利用额外的CNN / LSTM来学习每个单词的字符的隐藏状态(char CNN / LSTM)。
对于char基线,bichar和softword(当前字符所在的单词)用作wordlevel特征以改进字符表示。基于点阵的方法包括两个基于格的模型,它们都可以明确地利用字符和单词信息。基本网格使用3.2.1中提到的编码器,它可以将字级信息动态地合并到字符序列中。
对于MG晶格,每个感测嵌入将用于构建独立的感测路径。因此,不仅有单词信息,还有信息信息流入细胞状态。
- 结果证明了:
- 获取两种信息的model优于仅含单个信息的model
- 证明了利用基于格的模型利用字符和单词序列信息的能力。
4.3词义表示的影响
- 在本节中,我们将通过利用具有不同策略的感知级信息来研究词义表示的效果。因此,在我们的实验中使用了三种基于晶格的模型。
- 首先,基本点阵模型使用word2vec(Mikolov等,2013)来训练单词嵌入,它不考虑单词含义信息。
- 然后,我们引入基本格(SAT)模型作为比较,其中预训练的单词嵌入通过含义信息得到改善(Niu等,2017)。
- 此外,MG点阵模型使用有意嵌入来构建独立路径并动态选择适当的感知。
- MG效果好
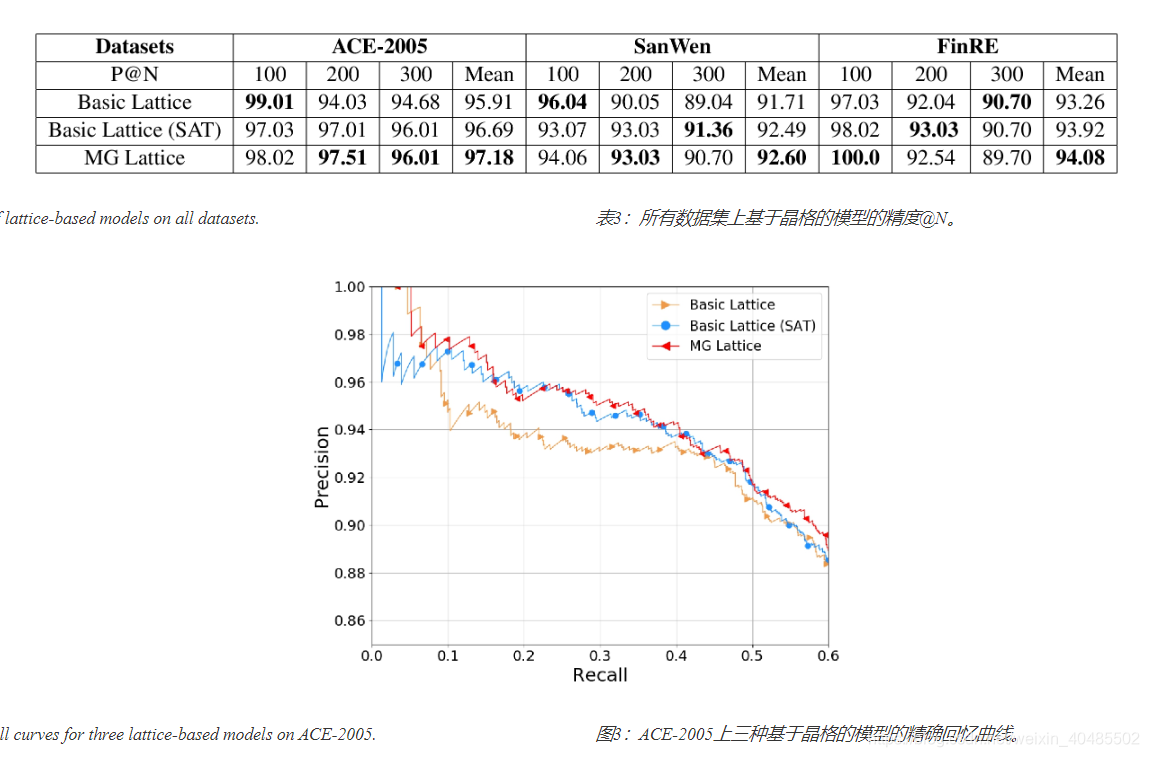
为了更直观地比较和分析所有基于晶格的模型的有效性,我们报告了图3中ACE-2005数据集的精确回忆曲线作为示例。
尽管基本晶格(SAT)模型获得了比原始基本晶格模型更好的整体性能,但是当召回率低时精度仍然较低,这对应于表3中的结果。
- 结论:
- 仅在预训练阶段考虑多个感觉会增加单词表示的噪声。
- 换句话说,单词表示往往倾向于语料库中常用的含义,当正确的当前单词的正确含义不是常见的时,这会干扰模型。
- 尽管如此,MG晶格模型成功地避免了这个问题,在曲线的所有部分都能提供最佳性能。该结果表明MG晶格模型不受噪声信息的显着影响,因为它可以动态地选择不同上下文中的感测路径。虽然MG晶格模型显示了整体结果的有效性和稳健性,但值得注意的是,改进是有限的。
- 这种情况表明,仍可以改进多粒度信息的利用。
- 仅在预训练阶段考虑多个感觉会增加单词表示的噪声。
4.4最终结果
我们对上面提到的五种模型的基于字符和基于单词的版本进行了实验。结果表明,基于字符的版本比所有数据集上的所有模型的基于单词的版本表现更好。因此,我们仅在以下实验中使用五种选定模型的基于字符的版本。
为了公平起见,我们在BLSTM和Att-BLSTM中添加了位置嵌入,这些都没有在原始论文中使用。
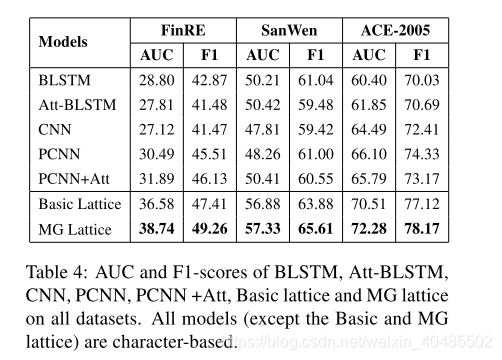
- 为了进行全面的比较和分析,我们报告了图4中的精确回忆曲线和表4中的F1分数和AUC。从结果中,我们可以观察到:
- (1)基于格子的模型在来自不同领域的数据集上显着优于其他提出的模型。
- 由于多义信息,MG晶格模型在所有模型中表现最佳,显示出中国RE任务的优越性和有效性。结果表明,感知级信息可以增强从文本中捕获深层语义信息的能力。
- (2)基本点阵模型和MG点阵模型之间的差距在数据集FinRE上变窄。造成这种现象的原因在于,财务报告是由财务报告语料库构建的,而财务报告的词语通常是严谨而明确的。
- (3)相比之下,PCNN和PCNN + ATT模型在SanWen和ACE数据集中表现更差。原因是这两个数据集中的实体对之间存在位置重叠,使得PCNN无法充分利用分段机制。结果表明基于PCNN的方法高度依赖于数据集的形式。相比之下,我们的模型显示了所有三个数据集的稳健性。
- (1)基于格子的模型在来自不同领域的数据集上显着优于其他提出的模型。
