AFM



self.P.shape
Out[18]: torch.Size([4])
假如有39个域,那么就有 m ⋅ ( m − 1 ) 2 \frac{m\cdot (m-1)}{2} 2m⋅(m−1)=741个特征交互,Attention layer的 W W W就是一个4x4的矩阵, h h h是个4x1的输出层,aij=[741] ,过一遍softmax归一化
DCN
评论区有人认识作者
揭秘 Deep & Cross : 如何自动构造高阶交叉特征
用tensorflow实现的DCN
玩转企业级Deep&Cross Network模型你只差一步
xl_w.shape
Out[9]: torch.Size([32, 1, 1])
dot_.shape
Out[10]: torch.Size([32, 117, 1])
x_l.shape
Out[11]: torch.Size([32, 117, 1])
xl_w.shape
Out[9]: torch.Size([32, 1, 1])
dot_.shape
Out[10]: torch.Size([32, 117, 1])
x_l.shape
Out[11]: torch.Size([32, 117, 1])

假设有117个特征,自己和自己内积,特征剩下1,乘以weight,weight的列数和117特征一致。
NFM
FM也可以看做是一个神经网络架构,就是去掉隐藏层的NFM。
NFM最重要的区别就在于Bi-Interaction Layer。Wide&Deep和DeepCross都是用拼接操作(concatenation)替换了Bi-Interaction。
Concatenation操作的最大缺点就是它并没有考虑任何的特征组合信息,所以就全部依赖后面的MLP去学习特征组合,但是很不幸,MLP的学习优化非常困难。
使用Bi-Interaction考虑到了二阶特征组合,使得输入的表示包含更多的信息,减轻了后面MLP部分的学习压力,所以可以用更简单的模型(实验中只用了一层隐层),取得更好的效果。
差点被某个代码带偏了,还是看看官方实现
https://github.com/guoyang9/NFM-pyorch
DIN

3个样本,故序列特征最多为3行。最长序列为4个元素,其他的用0补全。
通过deepctr_torch/models/basemodel.py:185的代码,所有张量的轴数被规范化为2
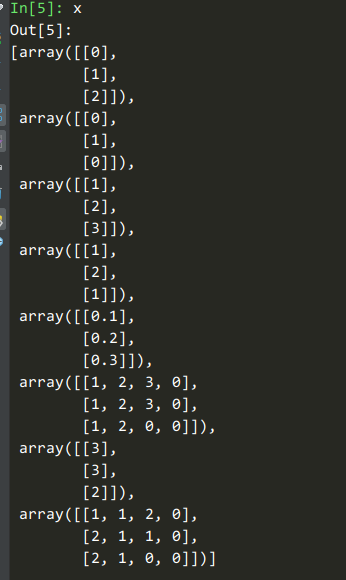
6个非序列特征,2个序列长度为4的序列特征,6+4x2=14
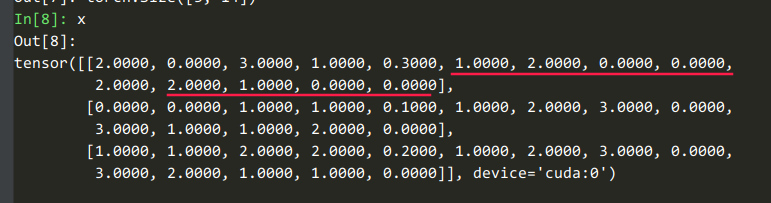
进入到deepctr_torch.models.din.DIN#forward
input_from_feature_columns这个函数用来抽稀疏特征和密集特征。
_, dense_value_list = self.input_from_feature_columns(...
dense_value_list
Out[10]:
[tensor([[0.3000],
[0.1000],
[0.2000]], device='cuda:0')]
query_emb_list是对sparse_feature_columns的嵌入
self.history_feature_list # 用户指定的
Out[16]: ['item', 'item_gender']
self.history_fc_names # 系统指定的, 前缀是 hist_
Out[17]: ['hist_item', 'hist_item_gender']
query_emb_list 是对 ['item', 'item_gender'] 做嵌入:
query_emb_list[0].shape
Out[21]: torch.Size([3, 1, 8])
query_emb_list 是对 ['hist_item', 'hist_item_gender'] 做嵌入:
keys_emb_list[0].shape
Out[20]: torch.Size([3, 4, 8])
回顾DIN构造函数的这一小段代码,判断是变长稀疏变量还是历史变量也很简单:
在Embedding的维度进行拼接
# concatenate
query_emb = torch.cat(query_emb_list, dim=-1) # [B, 1, E]
keys_emb = torch.cat(keys_emb_list, dim=-1)
keys_emb.shape
Out[24]: torch.Size([3, 4, 16]) # 16 = 8 * 2
keys_length
Out[29]: tensor([2, 3, 3], device='cuda:0')
看到deepctr_torch.layers.sequence.AttentionSequencePoolingLayer#forward
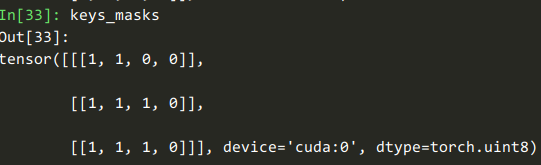
看到deepctr_torch.layers.core.LocalActivationUnit#forward
queries = query.expand(-1, user_behavior_len, -1)
query.shape
Out[38]: torch.Size([3, 1, 16])
queries.shape
Out[37]: torch.Size([3, 4, 16])
在序列长度轴复制query,使其与keys匹配
在Embedding轴,【query, key, 元素减,元素积】
attention_input.shape
Out[40]: torch.Size([3, 4, 64])
attention_output.shape
Out[39]: torch.Size([3, 4, 16])
这个deepctr_torch.layers.core.DNN有点意思
self.dnn
Out[41]:
DNN(
(dropout): Dropout(p=0)
(linears): ModuleList(
(0): Linear(in_features=64, out_features=64, bias=True)
(1): Linear(in_features=64, out_features=16, bias=True)
)
(activation_layers): ModuleList(
(0): Dice(
(bn): BatchNorm1d(64, eps=1e-08, momentum=0.1, affine=True, track_running_stats=True)
(sigmoid): Sigmoid()
)
(1): Dice(
(bn): BatchNorm1d(16, eps=1e-08, momentum=0.1, affine=True, track_running_stats=True)
(sigmoid): Sigmoid()
)
)
)
注意这里是把多个特征域拼在一起,得到一个唯一的Attention。
我觉得可以这样理解,一个用户曾访问了很多物品,而物品有很多属性,如【item_id, cat_id, brand_id】这些。我们需要综合考虑这些属性,但反映到物品权重时,只能有一个权重(而不是每个属性一个权重)。
(存在改进空间)
attention_score.shape
Out[42]: torch.Size([3, 4, 1])
回到deepctr_torch.models.din.DIN#forward,在使用了Attention之后,相当于对历史序列进行了加权平均。