python3集成了python2中urllib和urllib2的所有功能,在python3环境下只需要引入urllib库就可以使用urllib和urllib2的所有功能
本篇博客内容所使用的所有包:urllib(urllib.request.urlopen、urllib.parse)、pickle
这块先说一下必须知道的小知识点:HTTP状态码
简单总结一下:[100, 102]是消息,[200,207]是成功,[300,307]是重定向,[400,418]并[421,426]并[449,451]是错误,[500,510]加上600是服务器错误
Get方式简单爬取百度首页源码
1.先引入urllib下的request
import urllib.request
2.使用get方式请求获取请求
response = urllib.request.urlopen("http://www.baidu.com")
print(response)
经过打印发现response是http.client.HTTPResponse object,urlopen将得到的网页源码封装成HTTPResponse对象返回
3.获取源码文本信息并解码成utf-8
print(response.read().decode('utf-8'))
如果只是print(response.read())直接对得到的源码进行打印输出,发现,源码中的’\n’等特殊字符会直接当成字符,网页的源码缩进和树状结构不能保留
2021.01.28爬取的百度首页源码:https://wwx.lanzoui.com/iTrhMl7h3tc
测试技巧
一般测试自己的爬虫,可以使用http://httpbin.org网站进行测试。post请求的表单可以有用户名密码、cookie等,作用就是模拟用户登录,用于反反爬虫机制,可以使用上述网站进行post测试
封装表单数据,用于POST方式
1.引包
import urllib.parse # 解析器按一定规则解析数据包
import pickle # 保存html文件
2.定义表单数据
key_values = {"count":"[email protected]", "pwd":"ynagzy0203"}
3.将表单数据解析成网络字节的表单数据
data = bytes(urllib.parse.urlencode(key_values), encoding="utf-8")
urllib.parse中的urlencode将第一个参数字典类型的表单数据编码,成第二个参数字符编码类型的数据
4.核心步骤,urlopen
response = urllib.request.urlopen(“https://mail.qq.com/”, data= data)
urlopen只要有表单数据,那么请求网页的方式就是POST方式,以上方式做到了向服务器提交账号密码模拟浏览器登录从而获得更多的网页访问权限,以达到爬取更过网络资源的目的
5.将爬取到的源码保存到文件
pickle.dump(response.read(),open('./QQmail.html','wb'))
爬取网页超时处理
展示超时
response = urllib.request.urlopen("https://mail.qq.com/", timeout=0.01)
print(response.read().decode("utf-8"))
urlopen的第二个参数timeout指定响应时间宽容度,0.01秒肯定是得不到响应的,这里给0.01是为了故意超时,看到超时这一种情况
解决办法,try-catch捕获处理异常
try:
response = urllib.request.urlopen("http://httpbin.org/get", timeout=0.01) # 第二个参数指定响应时间宽容度
print(response.read().decode("utf-8"))
except urllib.error.URLError as e: # 进行超时处理
print("time out!")
测试技巧
在写爬虫中,很多时候会遇到很多不知名的错误,要善于使用各种技巧进行调试。除了使用httpbin网站对自己的爬虫进行调试还可以使用RESTer插件1
当然也可以在代码中进行对各种状态和变量输出从而达到调试的目的
- 取出状态码
response = urllib.request.urlopen("https://mail.qq.com/")
print(response.status)
# 豆瓣有反爬虫机制,就会得到418返回状态码
response = urllib.request.urlopen("https://www.douban.com/")
print(response.status) # 418是所访问的服务器发现你是爬虫之后返回的状态码
访问QQ邮箱首页的返回码,返回码是200
豆瓣有反爬虫机制,就会得到418返回状态码
-
取出response headers
response = urllib.request.urlopen(“http://www.baidu.com”)
print(response.getheaders()) # 向服务器发送请求的响应头
print(response.getheader(“Server”)) # 获取单个属性
总结:urlopen的返回值是HTTPResponse2对象,其中封装了状态status、response headers
模拟浏览器爬取反爬虫网站源码
模拟浏览器访问网站
先使用httpbin网站进行测试
1.要爬取的网站url
url = "http://httpbin.org/post" # 先进行测试
2.封装表单数据
data = bytes(urllib.parse.urlencode({"count":"[email protected]", "pwd":"yzy0203"}), encoding="utf-8")
3.封装request headers
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"} # 自行封装请求头
4.将url、表单、请求头和方式封装到Requset对象中
req = urllib.request.Request(url=url, data=data, headers=headers, method= "POST") # Request类封装的是url、数据、请求头
5.urlopen发送请求
reponse = urllib.request.urlopen(req) # 发送请求,使用Request作为参数
6.输出爬取到的网页
print(reponse.read().decode("utf-8"))
httpbin网站进行POST提交发现和上述代码输出内容基本一致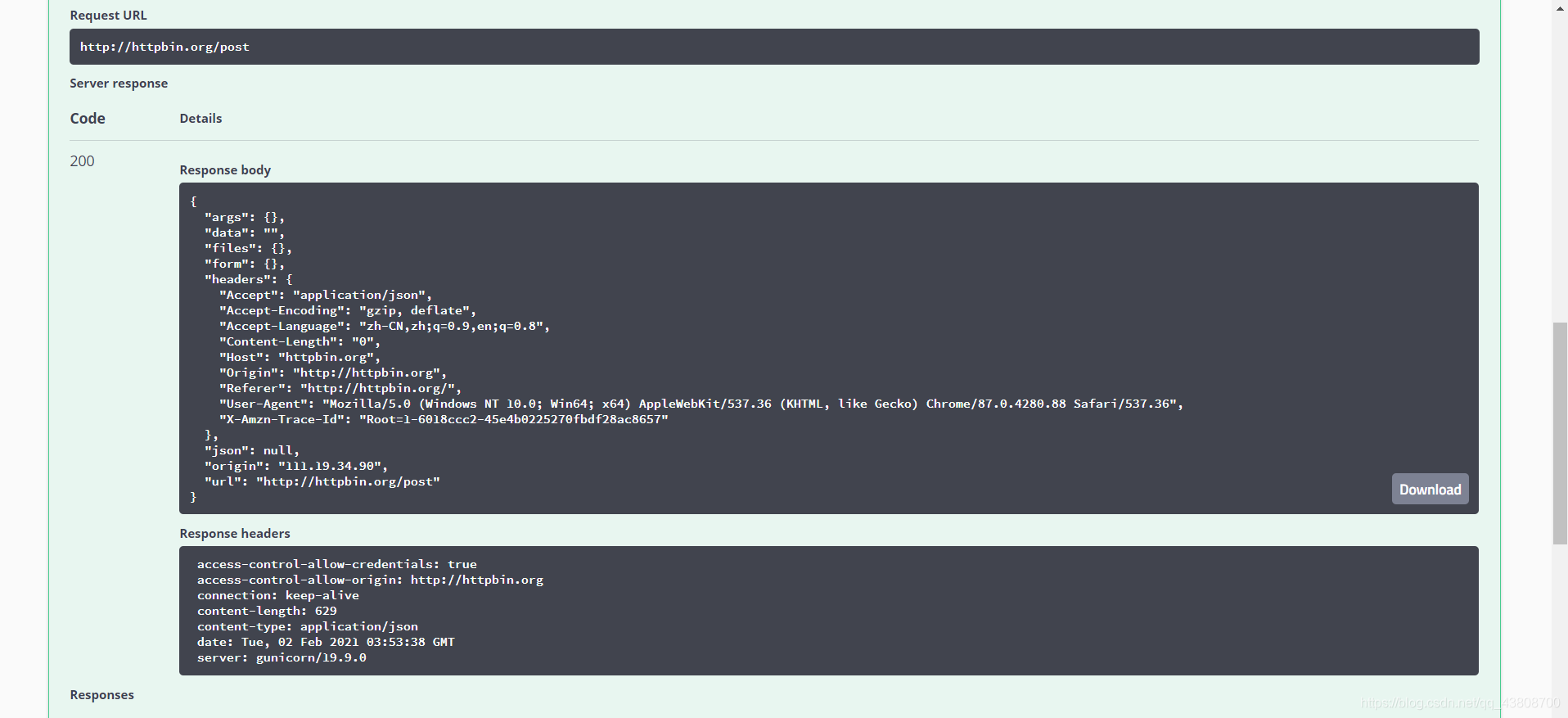
实战爬取具有反爬机制的豆瓣首页
url = "https://www.douban.com"
req = urllib.request.urlopen(url=url)
print(req.status)
直接对豆瓣首页进行爬取,错误返回状态码418
手动对request header进行封装(主要封装user-agent,user-agent可以通过浏览器开发者模式查看),模拟浏览器访问豆瓣,从而爬取数据 使用get方式
import pickle # 保存html文件
url = "https://www.douban.com"
# 请求头自定义用户代理信息:
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"}
req = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(req) # 使用Request作为参数
pickle.dump(response.read(),open('./douban.html','wb')) #后缀.pkl可加可不加
print(response.read().decode("utf-8"))
可以成功爬取:
douban2021.02.02网页源码爬虫爬取结果
任务驱动型开发:爬取有反爬机制的豆瓣Top250电影的25个页面源码
import urllib.request, urllib.error # 指定url,获取网页数据
def main():
# 爬取的网页
baseurl = "https://movie.douban.com/top250?start="
# 爬取25个网页源码
getData()
def getData(baseurl):
datalist = []
for i in range(0, 10): # 一页25条电影
url = baseurl + str(i*25)
html = askURL(url) # 保存获取到的网页源码
print(html)
# 解析过程
return datalist
def askURL(url):
# 头部信息 其中用户代理用于伪装浏览器访问网页
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/87.0.4280.88 Safari/537.36"}
req = urllib.request.Request(url, headers=head)
html = "" # 获取到的网页源码
try:
response = urllib.request.urlopen(req)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"): # has attribute
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
if __name__ == '__main__':
main()