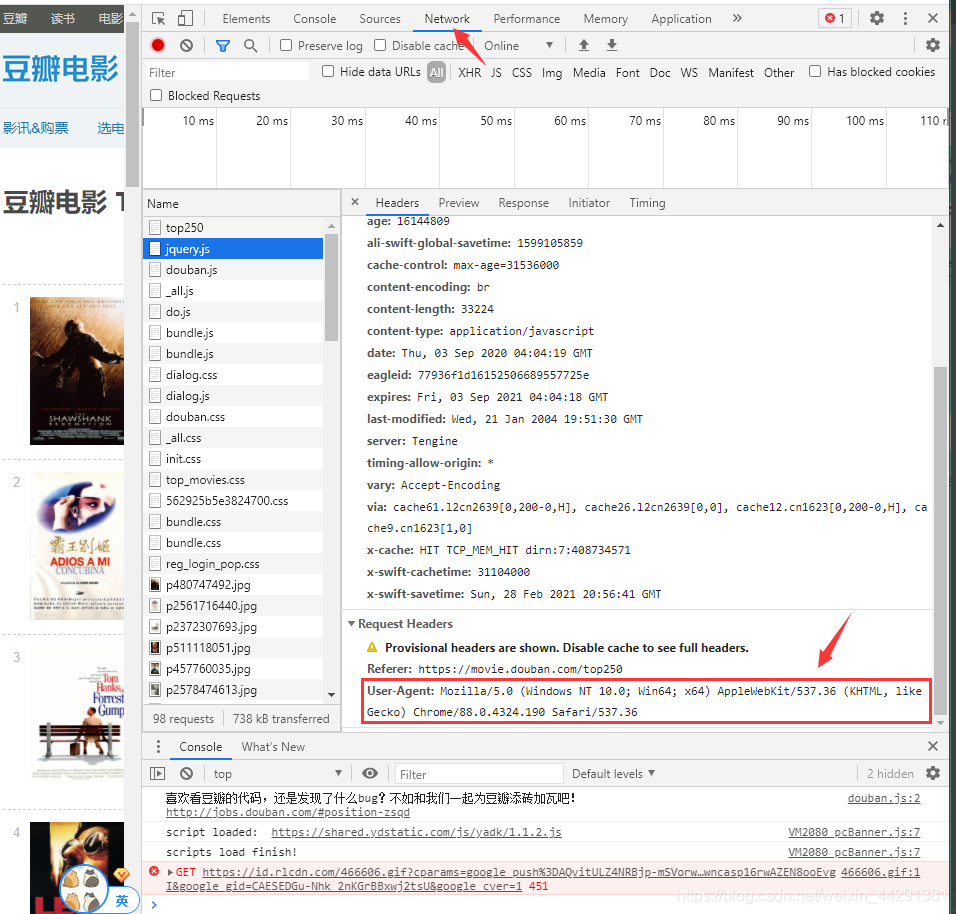
爬虫伪装正常用户登录的信息在当前网页按F12,
下图箭头处复制
import sys
from bs4 import BeautifulSoup #网页解析,获取数据
import re #正则表达式,进行文字匹配
import urllib.request,urllib.error #制定URL,获取网页数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite 数据库操作
def main():
#start后面不写东西表示0,为第一页的第0部电影,一页有25部。所以第二页是25
baseurl = "https://movie.douban.com/top250?start="
#1.爬取网页
datalist = getData(baseurl)
savepath=r'.\\douban250.xls'
#3.保存数据
# saveData()
#爬取网页
def getData(baseurl):
datalist=[]
for i in range(0,10):
url = baseurl + str(i*25)
html = askURL(baseurl) #保存获取到的网页源码
# 2.逐一解析数据
return datalist
#得到指定一个URL的网页内容
def askURL(url):
head = {
#模拟浏览器头部信息,向豆瓣服务器发送消息,下面一定不能写错!
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36'
}
#用户代理,表示告诉豆瓣服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
request = urllib.request.Request(url=url, headers=head)
html = ''
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
#保存数据
def saveData(savepath):
pass
if __name__ == '__main__':
main()
结果如下图,成功爬取豆瓣250前十页的数据
