一、批量标准化(BN,Batch Normalization)
1、BN 简介
a、协变量偏移问题
- 我们知道,在统计机器学习中算法中,一个常见的问题是
协变量偏移(Covariate Shift),协变量可以看作是输入变量。一般的深度神经网络都要求输入变量在训练数据和测试数据上的分布是相似的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。 - 传统的深度神经网络在训练时,随着参数的不算更新,中间每一层输入的数据分布
往往会和参数更新之前有较大的差异,导致网络要去不断的适应新的数据分布,进而使得训练变得异常困难,我们只能使用一个很小的学习速率和精调的初始化参数来解决这个问题。而且这个中间层的深度越大时,这种现象就越明显。由于是对层间数据的分析,也即是内部(internal),因此这种现象叫做内部协变量偏移(internal Covariate Shift)。
b、解决方法
- 为了解决这个问题,Sergey Ioffe’s 和 Christian Szegedy’s 在2015年首次提出了批量标准化(Batch Normalization,BN)的想法。该想法是:不仅仅对输入层做标准化处理,还要对每一中间层的输入(激活函数前)做标准化处理,使得输出服从均值为0,方差为1的正态分布,从而避免内部协变量偏移的问题。之所以称之为
批标准化:是因为在训练期间,我们仅通过计算当前层一小批数据的均值和方差来标准化每一层的输入。 - BN 的具体流程如下图所示:首先,它将隐藏层的输出结果(如,第一层: ,状态值)在 batch 上进行标准化;然后,经过缩放(scale)和平移(shift)处理,最后经过 RELU 激活函数得到 送入下一层(就像我们在数据预处理中将 x 进行标准化后送入神经网络的第一层一样)。
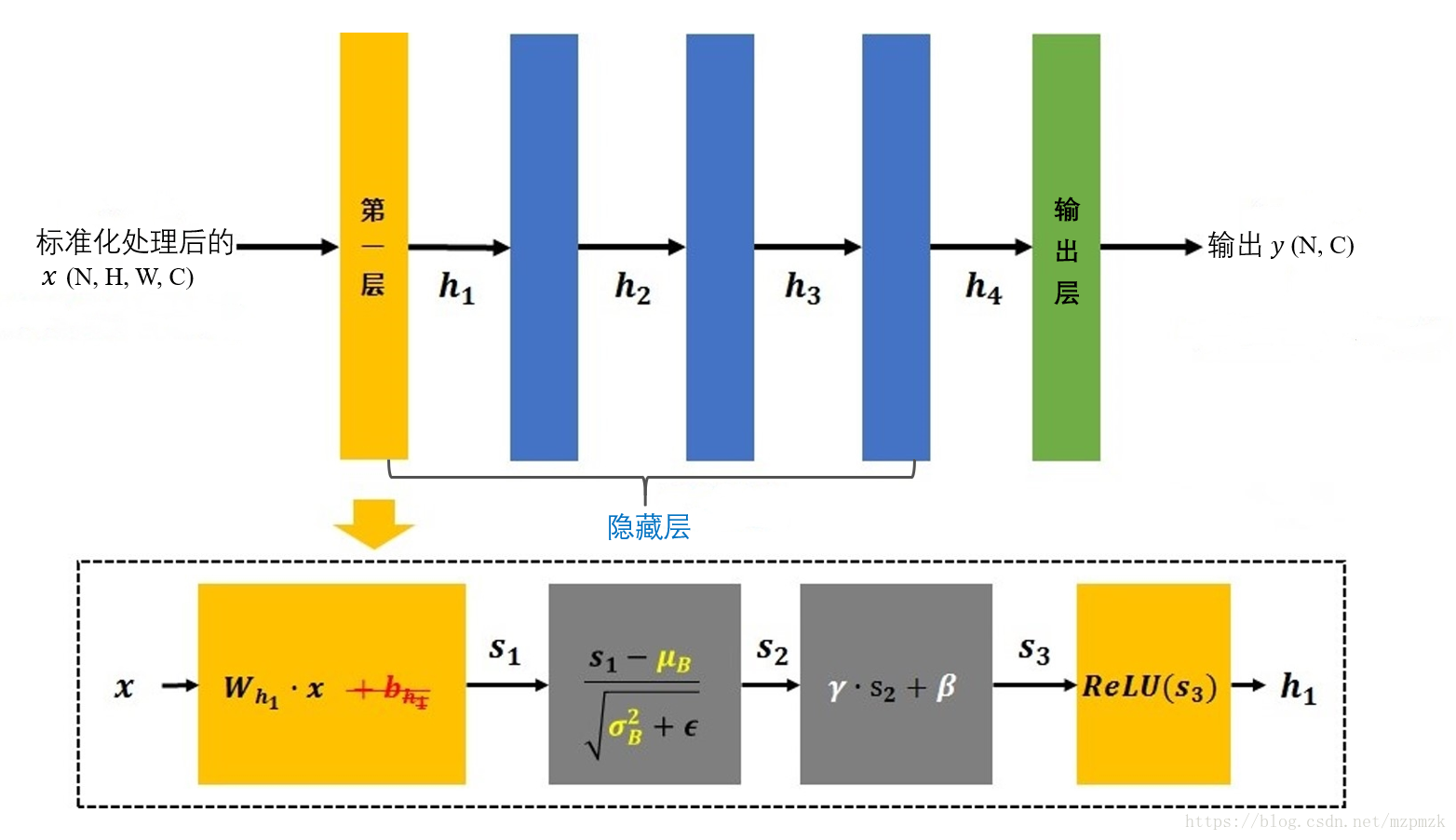
-
和
的解释:
和
都是可学习参数,分别用作对标准化后的值进行
缩放(scale)和平移(shift),提高网络的表达能力(不加此参数的话,中间层的输出将被限制在标准正态分布下)。当参数分别初始化为 和 时,标准化的变量被还原为原来的值。随着网络的训练,网络会学到最合适的 和 ,最终中间层的输出将服从均值为 ,方差为 的正态分布。 - 的解释:为了避免方差为 0 而加入的微小正数(eg:0.001)。
- 的解释:减去第一层 batch 个数据的均值 后, 偏置项 的作用会被抵消掉,所以在使用 BN 的层中没必要加入偏置项 (红色删除线),其平移的功能将由 来代替。
2、BN 的优点
现在几乎所有的卷积神经网络都会使用批量标准化操作,它可以为我们的网络训练带来一系列的好处。具体如下:
- 首先,通过对输入和中间网络层的输出进行标准化处理后,减少了内部神经元分布的改变,使降低了不同样本间值域的差异性,得大部分的数据都其处在非饱和区域,从而保证了梯度能够很好的回传,
避免了梯度消失和梯度爆炸; - 其次,通过减少梯度对参数或其初始值尺度的依赖性,使得我们可以使用较大的学习速率对网络进行训练,从而
加速网络的收敛; - 最后,由于在训练的过程中批量标准化所用到的均值和方差是在一小批样本(mini-batch)上计算的,而不是在整个数据集上,所以均值和方差会有一些小噪声产生,同时缩放过程由于用到了含噪声的标准化后的值,所以也会有一点噪声产生,这迫使后面的神经元单元不过分依赖前面的神经元单元。所以,它也可以看作是一种正则化手段,
提高了网络的泛化能力,使得我们可以减少或者取消 Dropout,优化网络结构。
3、BN 的使用注意事项
- BN 通常应用于输入层或任意中间层,且最好在
激活函数前使用。 - 使用 BN 的层
不需要加 bias 项了,因为减去batch 个数据的均值 后, 偏置项 的作用会被抵消掉,其平移的功能将由 来代替。 BN 的训练阶段均值和方差的求法:全连接层:对 batch 个数据内的每个对应节点(node)分别求均值和方差;二维卷积层:对 batch 个数据内的每一个对应的特征图(feature map)求均值和方差。BN 的测试阶段均值和方差的求法:测试时,使用的是训练集的每一个 BN 层均值和方差,这样做是为了避免在测试阶段只有一个数据实例的情况,因为这种情况下如果使用测试集本身的均值和方差的话,均值就是它本身,方差为 0,标准化后会得到 0,这样就没意义了。所以,我们在训练阶段使用滑动平均的方法来近似计算。
4、TensorFLow 中的 BN 怎么使用?
- Added is_training, a placeholder to store a boolean value indicating whether or not the network is training.
- Passed is_training to the conv_layer and fully_connected functions.
- Each time we call run on the session, we
added to feed_dict the appropriate value for is_training - Moved the creation of train_step inside a
with tf.control_dependenciesstatement. This is necessary to get the normalization layers created with tf.layers.batch_normalization toupdate their population statistics, which we need when performin inference.
##### 设计计算图阶段 #####
# 1、去掉 bias 项,且在此阶段不使用激活函数
linear_output = tf.layers.dense(prev_layer, num_units, use_bias=False, activation=None)
conv_output = tf.layers.conv2d(prev_layer, layer_depth*4, 3, strides, 'same', use_bias=False, activation=None)
# 2、使用 tf.contrib.layers.batch_norm() 或者 tf.layers.batch_normalization()进行标准化处理
# 注意要传入占位符 is_training 表明是训练阶段还是测试阶段
bn_linear_output = tf.layers.batch_normalization(linear_output, training=is_training)
bn_conv_output = tf.layers.batch_normalization(conv_output, training=is_training)
# 3、将标准化后的值传递给激活函数
liner_layer = tf.nn.relu(bn_linear_output)
conv_layer = tf.nn.relu(bn_conv_output)
# 4、训练之前必须先更新所有 BN 层的 moving_mean 和 moving_variance,因为测试阶段要用到训练集的均值和方差
# 另解:设置 tf.contrib.layers.batch_norm() 函数中的参数 updates_collections 值为 None 强制其原地更新,就不用加 with 语句中的控制依赖了
with tf.control_dependencies(tf.get_collection(tf.GraphKeys.UPDATE_OPS)):
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cross_entropy)
*********************************************************************
##### 执行计算图阶段 #####
# 1、添加一个布尔型占位符 is_training 来表明当前是训练阶段还是测试阶段
is_training = tf.placeholder(tf.bool, name="is_training")
# 2、训练阶段将feed_dict 中的参数 is_training 置为 True, 测试阶段置为 False
sess.run(train_step, feed_dict={input_layer: batch_xs,
labels: batch_ys,
is_training: True})
sess.run(accuracy, feed_dict={input_layer: mnist.validation.images,
labels: mnist.validation.labels,
is_training: False})二、实例标准化(IN,Instance Normalization)
- BN 和 IN 其实本质上是同一个东西,只是 IN 是作用于单张图片(对单个图片的所有像素求均值和标准差),但是 BN 作用于一个 batch(对一个batch里所有的图片的所有像素求均值和标准差)。但是为什么 IN 还会被单独提出,而且在
Style Transfer、GAN等任务中大放异彩呢?
- 通过调整 BN 统计量,或学习的参数 和 ,BN 可以用来做 domain adaptation
- Style Transfer 是一个把
每张图片当成一个 domain 的 domain adaptation 问题
- IN 在训练和测试阶段都用,BN 只在训练阶段用,测试阶段用滑动平均值和方差。
三、特征标准化(FN,Feature Normalization)
- FN 是 BN 的特例,只需令 BN 中的缩放和平移参数 、 即可,FN 服从标准正态分布。
- FN 作用于最后一层的特征表示上(FN 的下一层便是目标函数层),it ensures that all of the features have equal contribution to the cost function。
- FN 可提高习得特征的分辨能力,适用于类似人脸识别(face recognition)、行人重检测(person re-identification)、车辆重检测(car re-identification)等任务。

四、参考资料
1、YJango的Batch Normalization–介绍
2、https://github.com/udacity/deep-learning/tree/master/batch-norm
2、tensorflow中 batch normalization的用法
3、深度学习中 Batch Normalization为什么效果好?
4、深度学习(二十九)Batch Normalization 学习笔记
5、为什么会出现 Batch Normalization 层?
6、详解深度学习中的Normalization,不只是BN
7、Batch normalization和Instance normalization 的对比?