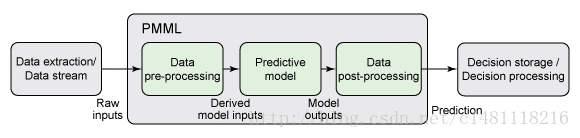
PMML简介
PMML全称预言模型标记模型(Predictive Model Markup Language),以XML 为载体呈现数据挖掘模型。PMML 允许您在不同的应用程序之间轻松共享预测分析模型。因此,您可以在一个系统中定型一个模型,在 PMML 中对其进行表达,然后将其移动到另一个系统中,而不需考虑分析和预测过程中的具体实现细节。使得模型的部署摆脱了模型开发和产品整合的束缚。
PMML标准
PMML 标准是数据挖掘过程的一个实例化标准,它按照数据挖掘任务执行过程,有序的定义了数据挖掘不同阶段的相关信息:
- 头信息(Header)
- 数据字典(DataDictionary)
- 挖掘模式(Mining Schema)
- 数据转换(Transformations)
- 模型定义 (Model Definition)
- 评分结果 (Score Result)
头信息(Header)
PMML文件使用头信息作为开始,它主要用于记录产品、版权、模型描述,建模时间等描述性信息。例如:
<Header copyright="Copyright (c) 2017 liaotuo" description="Random Forest Tree Model">
<Extension name="user" value="liaotuo" extender="Rattle/PMML"/>
<Application name="Rattle/PMML" version="1.4"/>
<Timestamp>2017-07-04 16:33:42</Timestamp>
</Header>其中:
- Header 是标识头信息部分的起始标记
- copyright 包含了所记录模型的版权信息
- description 包含可读的描述性信息
- Application 描述了生成本文件所含模型的软件产品。
- Timestamp 记录了模型创建的时间。
数据字典(DataDictionary)
数据字典定义了所有变量的信息,包括预测变量和目标变量。这些信息包括变量名,量度和类型等。 对于分类变量,可能包含各种不同类型的分类值, 包括有效值 (valid value),遗漏值 (missing value) 和无效值 (invalid value), 它们由 Value 的“property”属性决定;对于连续变量,可以指定一个或多个有效值范围 (Interval)。
<DataDictionary numberOfFields="7">
<DataField dataType="double" displayName="Age" name="Age" optype="continuous"/>
<Interval leftMargin="0" rightMargin="120" closure="closedClosed" />
<DataField dataType="string" displayName="Sex" name="Sex" optype="categorical">
<Value displayValue="F" property="valid" value="F"/>
<Value displayValue="M" property="valid" value="M"/>
</DataField>
<DataField dataType="string" displayName="BP" name="BP" optype="categorical">
<Value displayValue="HIGH" property="valid" value="HIGH"/>
<Value displayValue="LOW" property="valid" value="LOW"/>
<Value displayValue="NORMAL" property="valid" value="NORMAL"/>
<Value displayValue="ABNORMAL" property="invalid" value="ABNORMAL"/>
<Value displayValue="MISSING" property="missing" value="MISSING"/>
</DataField>
<DataField dataType="string" displayName="Cholesterol" name="Cholesterol"
optype="categorical">
<Value displayValue="HIGH" property="valid" value="HIGH"/>
<Value displayValue="NORMAL" property="valid" value="NORMAL"/>
</DataField>
<DataField dataType="double" displayName="Na" name="Na" optype="continuous"/>
<DataField dataType="double" displayName="K" name="K" optype="continuous"/>
<DataField dataType="string" displayName="Drug" name="Drug" optype="categorical">
<Value displayValue="drugA" property="valid" value="drugA"/>
<Value displayValue="drugB" property="valid" value="drugB"/>
<Value displayValue="drugC" property="valid" value="drugC"/>
<Value displayValue="drugX" property="valid" value="drugX"/>
<Value displayValue="drugY" property="valid" value="drugY"/>
</DataField>
</DataDictionary>挖掘模式(Mining Schema)
定义预测变量和目标变量
<MiningSchema>
<MiningField importance="0.589759" name="K" usageType="active"/>
<MiningField importance="0.0328595" name="Age" usageType="active"/>
<MiningField importance="0.0249929" name="Na" usageType="active"
outliers=" asExtremeValues" lowValue="0.02" highValue="0.08"/>
<MiningField importance="0.0333406" name="Cholesterol" usageType="active"/>
<MiningField importance="0.307279" name="BP" usageType="active"
missingValueReplacement="HIGH"/>
<MiningField importance="0.0117684" name="Sex" usageType="active"/>
<MiningField name="Drug" usageType="predicted"/>
</MiningSchema>- 变量的属性由 “usageType” 值决定,该属性未指定或者值为 “active” 代表预测变量, “predicted”代表目标变量。一般来说,一个常见的模型有多个预测变量和一个目标变量, 但是也可以没有预测变量、多个目标变量或者根本没有目标变量。
- 所有在 Mining Schema 中被引用的变量一定会在数据字典中被定义, 但是不是所有出现在数据字典中的变量会在 Mining Schema 中被应用, Mining Schema 定义了数据字典中的一个子集,这个子集才是对模型来说最重要的。
数据转换 (Transformations)
一旦数据字典对数据集做出了定义,那么就可以在其之上进行各种数据转换的预处理操作。这是由于有时用户所提供的数据并不能直接用于建模,需要将原始的用户数据转换或映射成模型可以识别和使用的数据类型,这就需要使用数据转换来完成。譬如,神经网络模型内部仅能处理数值型的数据,如果用户数据中含有离散型数据,如性别包含“男”、“女”二值,那在建模前就需要将性别变量映射成 0 和 1 来分别表示“男”和“女”。
PMML 标准支持一些常用的数据转换预处理操作,并在此基础上支持使用函数表达式的转换。以下所列的是标准所定义的一些简单的数据转换操作:
- 正态化 (Normalization) - 把数据值转化为数值,同时适用于连续性变量和离散变量。
- 离散化 (Discretization) - 把连续性变量转化为离散变量。
- 数据映射 (Value mapping) - 把当前离散变量映射成另一种离散性变量。
- 函数 (Functions) - PMML 内建了大量的常用函数,用户也可以定义自己的函数。
- 聚合 (Aggregation) - 聚合操作,比如求平均值,最大值,最小值等。
如下:给出了一个使用 Discretization 的示例。通过两个给定的区间将连续型变量“Profit”转换成仅含“negative”和“positive”二值的离散变量。
<Discretize field="Profit">
<DiscretizeBin binValue="negative">
<Interval closure="openOpen" rightMargin="0"/>
<!-- left margin is -infinity by default -->
</DiscretizeBin>
<DiscretizeBin binValue="positive">
<Interval closure="closedOpen" leftMargin="0"/>
<!-- right margin is +infinity by default -->
</DiscretizeBin>
</Discretize>如下:给出了一个使用 Functions 的示例,通过使用内建函数 if 和 isMissing 将变量“PREVEXP”中的缺失值替换为指定的均值。值得注意的是,替换了缺失值之后将产生一个新的变量“PREVEXP_without_missing”。
<DerivedField dataType="double" name="PREVEXP_without_missing"
optype="continuous">
<Apply function="if">
<Apply function="isMissing">
<FieldRef field="PREVEXP"/>
</Apply>
<Constant>mean</Constant>
<FieldRef field="PREVEXP"/>
</Apply>
</DerivedField>模型定义 (Model Definition)
具体的模型定义,最新的 PMML 4.0.1 定义了一下十三种模型:
- AssociationModel
- ClusteringModel
- GeneralRegressionModel
- MiningModel
- NaiveBayesModel
- NeuralNetwork
- RegressionModel
- RuleSetModel
- SequenceModel
- SupportVectorMachineModel
- TextModel
- TimeSeriesModel
- TreeModel
这些模型都是帮助使用者从历史性的数据中提取出无法直观发现的,具有推广意义的数据模式。比如说 Association model,关联规则模型,常被用来发现大量交易数据中不同产品的购买关系和规则。使用其分析超市的销售单就可以发现,那些购买婴幼儿奶粉和护肤品的客户同时也会以较大的可能性去购买纸尿裤。这样有助于管理人员作出合理的商业决策,有导向的推动购物行为,比如将上述产品放在相邻的购物架上便于客户购买,从而产生更高的销售额。Tree model,树模型,也是很常用的模型,她采用类似树分支的结构将数据逐层划分成节点,而每个叶子节点就表示一个特别的类别。树模型受到应用领域广泛的欢迎,还有一个重要的原因就是她所做出的预测决策易于解释,能够快速推广。为了支持这些模型,PMML 标准提供了大量的语法来有针对性的表示不同的模型。
评分结果(Score Result)
评分结果集可以在输出元素 (Output) 中定义
<Output>
<OutputField name="$R-Drug" displayName="Predicted Value" optype="categorical"
dataType="string" targetField="Drug" feature="predictedValue"/>
<OutputField name="$RC-Drug" displayName="Confidence of Predicted Value"
optype="continuous" dataType="double" targetField="Drug"
feature="standardError"/>
<OutputField name="$RP-drugA" displayName="Probability of drugA"
optype="categorical" dataType="string" targetField="Drug"
feature="probability" value="drugA"/>
<OutputField name="$RP-drugB" displayName="Probability of drugB"
optype="categorical" dataType="string" targetField="Drug"
feature="probability" value="drugB"/>
<OutputField name="$RP-drugC" displayName="Probability of drugC"
optype="categorical" dataType="string" targetField="Drug"
feature="probability" value="drugC"/>
<OutputField name="$RP-drugX" displayName="Probability of drugX"
optype="categorical" dataType="string" targetField="Drug"
feature="probability" value="drugX"/>
<OutputField name="$RP-drugY" displayName="Probability of drugY"
optype="categorical" dataType="string" targetField="Drug"
feature="probability" value="drugY"/>
</Output>输出元素 : 描述了从模型中获取评分结果值的集合。每一个输出变量指定名称,类型,规则计算和结果特征。 结果特征 (feature): 它是一个结果的标识符 , 它有很多的分类表达,常见统计观念如下:
- 预测价值(predictedValue):它描述了预测统计的目标值。
- 概率(probability):它描述预测统计的目标值的概率值。
- 标准误差(standardError):它描述了标准误差的预测数值。
样例pmml
LR.pmml
<?xml version="1.0"?>
<PMML version="4.3" xmlns="http://www.dmg.org/PMML-4_3" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.dmg.org/PMML-4_3 http://www.dmg.org/pmml/v4-3/pmml-4-3.xsd">
<Header copyright="Copyright (c) 2017 liaotuo" description="Generalized Linear Regression Model">
<Extension name="user" value="liaotuo" extender="Rattle/PMML"/>
<Application name="Rattle/PMML" version="1.4"/>
<Timestamp>2017-07-11 13:18:36</Timestamp>
</Header>
<DataDictionary numberOfFields="4">
<DataField name="am" optype="continuous" dataType="double"/>
<DataField name="cyl" optype="continuous" dataType="double"/>
<DataField name="hp" optype="continuous" dataType="double"/>
<DataField name="wt" optype="continuous" dataType="double"/>
</DataDictionary>
<GeneralRegressionModel modelName="General_Regression_Model" modelType="generalizedLinear" functionName="regression" algorithmName="glm" distribution="binomial" linkFunction="logit">
<MiningSchema>
<MiningField name="am" usageType="predicted"/>
<MiningField name="cyl" usageType="active"/>
<MiningField name="hp" usageType="active"/>
<MiningField name="wt" usageType="active"/>
</MiningSchema>
<Output>
<OutputField name="Predicted_am" feature="predictedValue"/>
</Output>
<ParameterList>
<Parameter name="p0" label="(Intercept)"/>
<Parameter name="p1" label="cyl"/>
<Parameter name="p2" label="hp"/>
<Parameter name="p3" label="wt"/>
</ParameterList>
<FactorList/>
<CovariateList>
<Predictor name="cyl"/>
<Predictor name="hp"/>
<Predictor name="wt"/>
</CovariateList>
<PPMatrix>
<PPCell value="1" predictorName="cyl" parameterName="p1"/>
<PPCell value="1" predictorName="hp" parameterName="p2"/>
<PPCell value="1" predictorName="wt" parameterName="p3"/>
</PPMatrix>
<ParamMatrix>
<PCell parameterName="p0" df="1" beta="19.7028827927103"/>
<PCell parameterName="p1" df="1" beta="0.487597975045672"/>
<PCell parameterName="p2" df="1" beta="0.0325916758086386"/>
<PCell parameterName="p3" df="1" beta="-9.14947126999654"/>
</ParamMatrix>
</GeneralRegressionModel>
</PMML>
rule.pmml
<RuleSetModel modelName="RiskEval" functionName="classification" algorithmName="RuleSet">
<MiningSchema>
<MiningField name="var973" usageType="active" invalidValueTreatment="asMissing" missingValueReplacement="0"/>
<MiningField name="var969" usageType="active" invalidValueTreatment="asMissing" missingValueReplacement="0"/>
<MiningField name="var20" usageType="active" invalidValueTreatment="asMissing" missingValueReplacement="0"/>
<MiningField name="var393" usageType="active" invalidValueTreatment="asMissing" missingValueReplacement="0"/>
<MiningField name="var868" usageType="active" invalidValueTreatment="asMissing" missingValueReplacement="0"/>
<MiningField name="var543" usageType="active" invalidValueTreatment="asMissing" missingValueReplacement="0"/>
<MiningField name="var1213" usageType="active" invalidValueTreatment="asMissing" missingValueReplacement="0.0"/>
<MiningField name="flg" usageType="target"/>
</MiningSchema>
<RuleSet defaultScore="0">
<RuleSelectionMethod criterion="firstHit"/>
<SimpleRule id="RULE1" score="1" confidence="1">
<CompoundPredicate booleanOperator="or">
<SimplePredicate field="var973" operator="greaterOrEqual" value="1"/>
<SimplePredicate field="var969" operator="greaterOrEqual" value="1"/>
<SimplePredicate field="var20" operator="greaterOrEqual" value="7"/>
<CompoundPredicate booleanOperator="and">
<SimplePredicate field="var393" operator="greaterOrEqual" value="2"/>
<SimplePredicate field="var543" operator="notEqual" value="1"/>
</CompoundPredicate>
<CompoundPredicate booleanOperator="and">
<SimplePredicate field="var868" operator="greaterOrEqual" value="1"/>
<SimplePredicate field="var1213" operator="lessThan" value="0.8"/>
</CompoundPredicate>
</CompoundPredicate>
</SimpleRule>
</RuleSet>
</RuleSetModel>