深度学习标准化
引言
何凯明在他的论文《Rethinking ImageNet Pre-training》中不使用ImageNet预训练,直接使用参数随机初始化方式(scratch),成功地训练出目标检测任务的神经网络模型。
为什么使用Batch Normalization不能从scratch训练目标检测任务的模型?
为什么何凯明使用Group Normalization和Synchronized Batch Normalization就能训练出来?
深度网络训练的问题
总所周知,深度网络训练会遇到两个大问题:梯度消失和梯度爆炸。
假设网络没有使用非线性函数,不考虑偏置b,设每层网络层输入为 ,参数是 ,输出为 ,每一层网络层的操作是
梯度消失
假设 ,即
随着k的增大,x的值越来越小,从而梯度呈指数级别下降,接近于0,这会导致梯度下降参数更新的非常缓慢,降低收敛速度。
梯度爆炸
假设 ,即
随着k的增大,x的值越来越大,从而梯度呈指数级别上升,甚至超出数据类型能够表达的最大的值,这会导致梯度下降参数变化范围很大,影响模型收敛。
因为梯度消失和梯度爆炸问题,我们在训练网络时都要小心翼翼地设置参数,
- 模型参数,一般由均值为0,方差为0.01的高斯分布初始化
- 学习率,学习率一般很小,比如0.0015(BN论文,训练Inception网络学习率使用0.0015)
使用非线性激活函数可以限制输出值x的取值范围,在一定程度上消除梯度消失和梯度爆炸的影响。
-
Sigmoid 可以把输出值限制在0到1之间,可以消除梯度爆炸的影响。但是x的值一般都非常大,经过Sigmoid激活函数之后,x的值落在Sigmoid的饱和区域(如下图的红色部分),饱和区域的梯度值接近与0,从而减慢了训练的速度。

-
ReLU ReLU是为了克服Sigmoid具有缺点,模仿生物神经激活函数而提出的。ReLU把一些对梯度没有贡献的神经元设置为0,增加网络的稀疏性,而且ReLU计算量比Sigmoid少,但是ReLU并没有很好的消除梯度消失和梯度爆炸的影响。
Internal Covariate Shift:当深度网络浅层网络参数的发生细微变化,这种变化结果网络传输到深层网络,导致网络层输出数据发生很大的变化,从而网络层参数要发生很大的变动以适应输入数据的变化,这种深度网络中在训练过程中内部节点的数据分布变化的现象,称为Internal Covariate Shift。
为了消除梯度消失、梯度爆炸和Internal Covariate Shift的影响,受机器学习对样本进行归一化的启发,目前已经提出了许多深度学习的标准化操作,比如Batch Normalization、Synchronized Batch Normalization、Group Normalizaiton等。
Batch Normalization
论文:《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》
作者:Sergey Ioffe & Christian Szegedy
团队:Google Team
期刊:ICML 2015 (International Conference on Machine Learning,国际机器学习大会)
既然深度神经网络的网络层的输入输出数据经常发生大的变动,那么对这些数据添加一个线性变换,把这些数据标准化,从而限制了这些数据的数据分布,使得训练的时候网络层更加稳定。
线性变换/标准化公式:
其中
是需要计算均值和标准差的数据子集,i是数据的序号,表示数据的个位置。
- 传统神经网络
在传统的神经网络中,数据的维度是
,N表示batch size,C表示当前网络层的神经元个数。
用数学公式表达
:
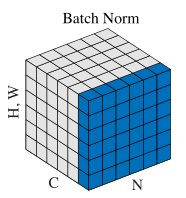
- 卷积神经网络
在卷积神经网络中,数据维度是是 ,N表示batch size,C表示数据的channels个数,H和W分别表示feature map的高和宽。
用数学公式表示 :
用图来表示:
接着要考虑对网络中的哪个位置的数据进行标准化操作。假设网络层的操作是
其中x表示输入数据,z表示输出数据,可以进行标准化的数据有:
、
和
。
- ,输入数据之前经过激活函数,数据的分布已经发生改变,再进行标准化操作效果不大。
- ,该层网络层的输出数据等于下层网络层的输入数据。
- ,经过线性变换之后,数据的分布发生改变,数据发散了,这时可以对数据标准化,控制数据的分布。
假设Batch Normalization的标准化操作为
,或者说BN网络层,那么BN层的位置在
标准化操作改变了数据的分布,可能使得网络层失去原来的特征表征能力。为了消除这个问题,作者为每个标准化后的数据值设置了一对可学习的参数
和
,用于还原原来的分布,还原操作为
注意,当网络为卷积神经网络,
的子集不是标准化时的子集,变为
用图来表示为:
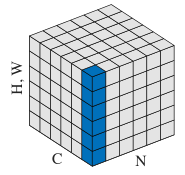
即一个feature map共同使用一对 和 。
标准化操作:
还原操作:
当
时,
,即新数据与原数据相同,所以BN层能够学习到自身映射能力,能够减轻标准化造成网络层损失特征表征能力带来的问题。
因为
,偏置b作用被减去均值取消了,又加在
上,所以b可以去掉,因此最终BN操作为
网络模型使用BN层,在使用模型预测时会出现问题。因为在模型预测/测试阶段,输入数据是没有batch的,没办法计算均值 和标准差 ,因此标准化公式中的均值 和标准差 需要设定。如果设定的均值 和标准差 不能体现测试集的统计特征,预测结果就会有很大的影响。
一般的处理是使用训练过程中均值 和标准差 的平均值,用训练集的统计值去近似测试集的统计值。
有一点需要注意的是,用于测试的方差
是总体无偏方差估计值
优点:
- 训练速度更快。因为网络的数据分布更加稳定,模型更容易学习。
- 使用更大的学习率。因为网络的数据分布更加稳定,使用更大的学习率不会轻易造成损失函数曲线发散情况。使用更大的学习率能够加快训练的收敛速度。
- 不需要太关注模型参数的初始化。模型的随机初始化结果对模型的训练没有太大的影响。
- 正则化效果。Mini-batch的BN层是使用mini-batch的统计值近似训练集的统计值,使得BN层具有正则化效果。
缺点:
- BN依赖batch size,对batch size敏感。当batch size太小时,batch的统计值不能代表训练集的统计值,使得训练过程更加困难。
- 在迁移学习fine-tune阶段,模型的BN层参数固定不变,这是不合理的,因为迁移学习的预训练数据集和目标数据集有非常大的不同。
- 不能用于测试阶段。测试阶段使用训练集的统计值去近似训练集的统计值是不合理的。
BN效果
简单神经网络数据变动情况(MINIST,3层隐藏层)

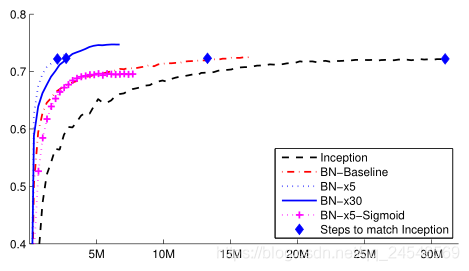
卷积神经网络训练效果(ImageNet,Inception网络)
Synchronized Batch Normalization
论文:《MegDet: A Large Mini-Batch Object Detector》
作者:Chao Peng & Tete Xiao & Zeming Li
团队:Face++ Team
期刊:CVPR 2018
提出了一种使用大Mini-batch训练目标检测网络的方法。(加GPU)
针对目标检测网络训练问题:
- Mini-batch size太小,在Faster R-CNN中batch size为2(张图片),Mask R-CNN中batch size为16(张图片),导致训练时间太长。
- Fine-tune阶段固定BN层的参数,使用预训练数据集(ImageNet)的统计值近似目标数据集(COCO)的统计值,但这两种数据集的数据有很大的不同。
- 正负样本(region proposals)不平衡,如下表所示,正负样本之比不足1/3。
| Epoch | Batch Size | Ratio(%) |
|---|---|---|
| 1 | 16 | 5.58 |
| 1 | 256 | 9.82 |
| 6 | 26 | 11.77 |
| 6 | 256 | 16.11 |
| 12 | 16 | 16.59 |
| 12 | 256 | 16.91 |
只要mini-batch size变大,上述的问题可以得到很好的解决。作者的想法就是加GPU,GPU的数量越多,mini-batch size就能越大。
与一般的多GPU训练方法不同,一般的多GPU训练方法都是每个GPU单独计算GPU内存中样本的统计值,这是异步的BN。而作者提出的多GPU训练方法是同步的。
一次Synchronized Batch Normalization(SyncBN)操作要同步两次,第一次是计算所有输入数据的均值,第二次是计算所有输入数据的方差。其中又包括两次广播过程,分别把计算得到的均值和方差广播给所有GPU。如下图所示

实验效果(COCO, ResNet-50+FPN)
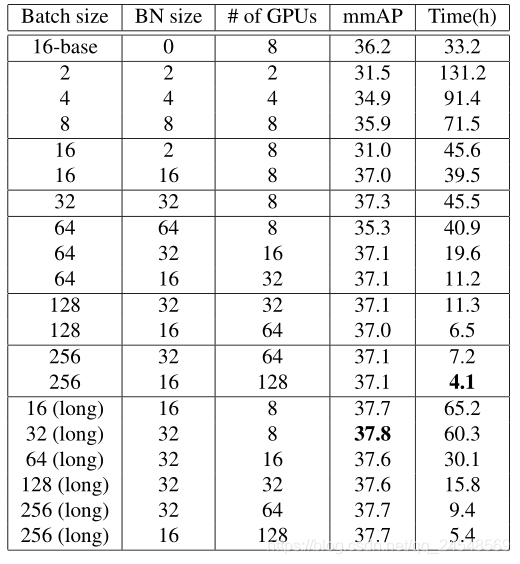
不同batch size比较(COCO, ResNet-50+FPN)
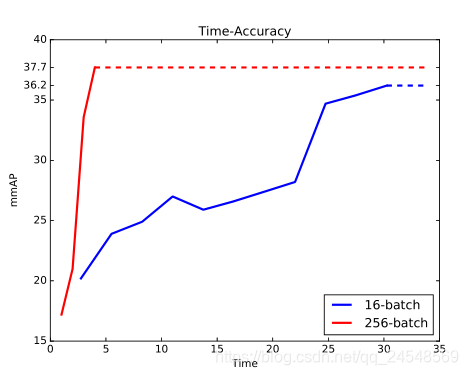
奇怪的结果(COCO, ResNet-50+FPN)

训练同样epochs的数据,256-batch的BN统计值准确性应该比16-batch的统计值的准确性要高,256-batch应该学习的更好,但是实验结果却是反过来,16-batch先学到东西,经过15个epochs之后256-batch才追赶16-batch。
优点:
- 加快训练速度;
- fine-tune能进行有效的BN;
- 缓解正负样本不平衡问题。
使用条件艰难:
- 需要很多GPU!作者使用128个GPU才使得batch size达到256;
- SyncBN的实现需要技巧,作者使用NVIDIA Collective Communication Library (NCCL)实现同步机制。
Group Normalization
论文:《Group Normalization》
作者:Yuxin Wu & Kaiming He
团队:Facebook AI Research (FAIR)
期刊:ECCV 2018
作者针对的是BN对batch的依赖引起的问题:
- 训练使用的batch size不是固定的;
- 模型预测或测试时没有“batch”的概念的;
- batch size太小导致训练缓慢,而且影响BN统计值的准确性。
SIFT、HOG和GIST经典特征被设计成分组表征,而且包括分组标准化。作者从中受到启发,对卷积网络的channels进行分组,对每个channels分组分别进行标准化处理。
与Group Normalization (GN)类似的还有Layer Normalization (LN)和Instance Normalization (IN)。
标准化公式:
其中
LN的
为
IN的
为
GN的
为
BN的
为
图解:
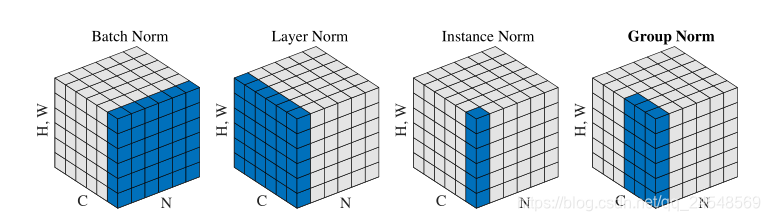
LN和IN是GN的极端情况。
当G等于1时,GN就变成了LN,GN的限制没有LN那么严格,模型依然有很大的灵活性可以在每个分组学习到不同的分布。
当 等于1时,GN就变成IN,而IN只依赖空间维度,没有考虑都channel之间的依赖关系。
GN的实现非常简单

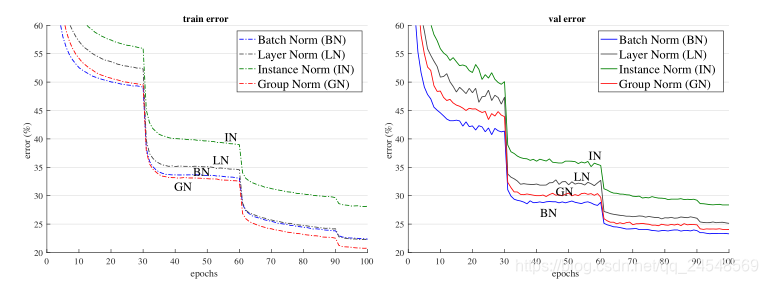
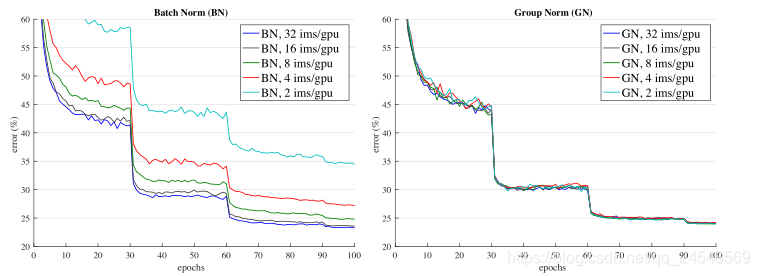
训练效果——错误率曲线(ImageNet,ResNet-50,8 GPU,32 images/GPU)
训练效果——ImageNet classification error vs. batch sizes(ImageNet,ResNet-50,8 GPU)
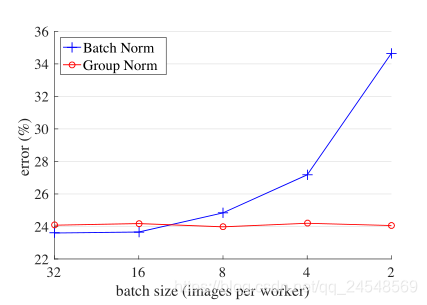
训练效果——对batch sizes的敏感度(ImageNet,ResNet-50,8 GPU)
VGG-16在conv5_3的输出(在normalization和ReLU之间)的特征分布(ImageNet,32 images/GPU)

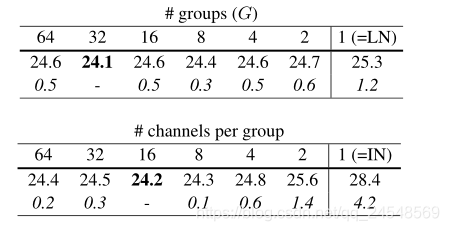
GN的不同的分组数和每组的channels数的比较
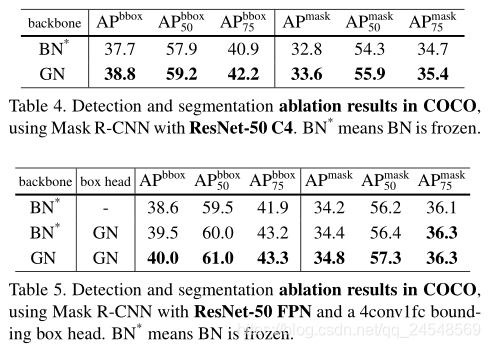
目标检测和分割的训练效果
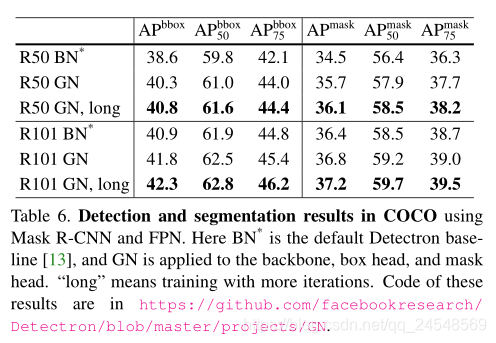
目标检测和分割的训练效果
优点:
- 不依赖batch size;
- 可以在预测时使用。