Redis 缓存常见问题 :缓存雪崩,缓存击穿,缓存穿透,缓存预热
在之前的博客中,我介绍了Redis缓存的一些常见问题,如:缓存雪崩、缓存击穿、缓存穿透等。这次就来介绍一下Redis的缓存一致性的问题。
对于缓存和数据库的更新操作,主要分为以下两种
- 先删除缓存,再更新数据库
- 先更新数据库,再删除缓存
首先可能会带来疑惑的点是,为什么这里是删除缓存而不是更新缓存?
按照常理来说,更新的效率通常都会比删除高,因为我们在删除了缓存后当有读操作到来时,当其查询缓存不存在时,就会去查询数据库,并将读取到的值写入到缓存中,这样的效率明显比更新低。
但是我们还需要考虑一个问题,即缓存的使用率问题。如果在短时间内对数据库进行了10000次更新操作,那么缓存也必定会进行10000次的更新操作,那这个缓存它真的有用到那么多次吗?如果它仅仅是一个冷门数据,可能在这期间内只进行了仅仅几次的查询操作,那我们的这些更新操作不是会显得很多余吗?
所以,我们才会去使用删除。因为在我们删除缓存后,只有在其真正使用到这个数据的时候,才会将其写入缓存,因此我们就不用每次都对缓存进行更新操作,从而保证效率。
先删除缓存,再更新数据库

对于这种情况,能够保证缓存的一致性吗?
答案肯定是否定的,例如下面这种情景
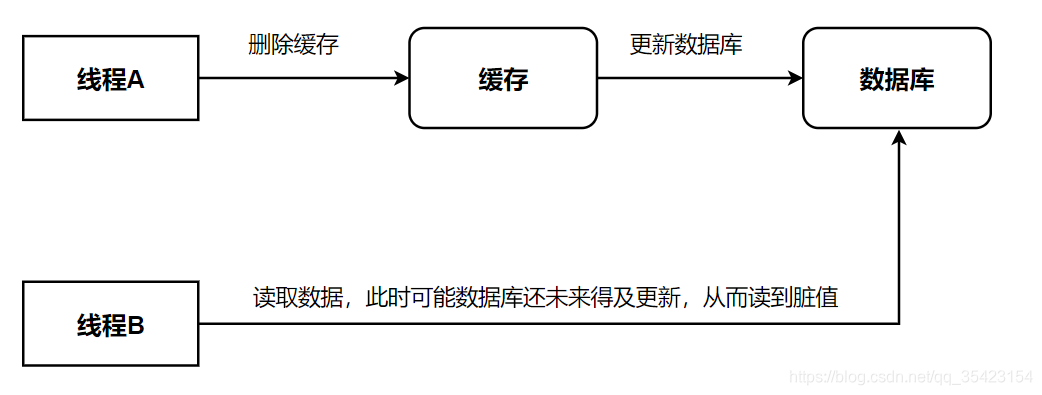
- 线程A写入数据,此时先删除缓存
- 线程B读取数据,查询缓存不存在,直接去查询数据库
- 线程B将查询到的旧值写入至缓存中
- 线程A将新数据更新至数据库中
对于上述这种情况,线程B在线程A更新数据库之前就提前读取了数据库,从而读取到了旧值,而后线程B将读取到的旧值再次写入缓存中,就出现了缓存不一致的情况。
那么这个问题如何解决呢?
这时候就需要引入延时双删的机制
延时双删
为了避免在更新数据库的时候,其他的线程读取到了数据库中的旧值并将其写入缓存这种情况,我们会在数据库更新完后等待一段时间,再次删除缓存,来保证下一个到来的线程能够将正确的缓存更新回去。
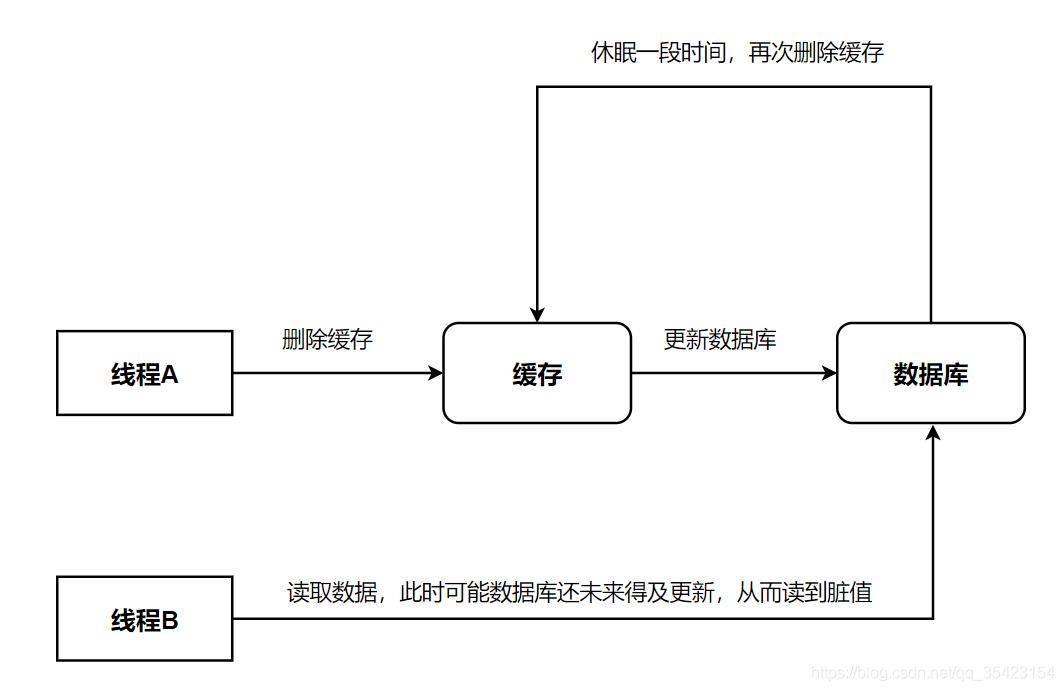
流程如下
- 线程A写入数据,此时先删除缓存
- 线程B读取数据,查询缓存不存在,直接去查询数据库
- 线程B将查询到的旧值写入至缓存中
- 线程A将新数据更新至数据库中,休眠一段时间
- 线程A将缓存再次删除,来确保缓存的一致性
- 其他线程查询数据库,将正确的值更新至缓存中
那么,为了保证我们能够将错误的缓存删除,所以我们的sleep时间只需要大于线程读写缓存的时间即可
先更新数据库,再删除缓存
那么如果我们先更新数据库,再更新缓存呢?

对于这种操作,缓存不一致的情况就更加明显了。由于磁盘I/O速度慢,在更新数据库、删除缓存这段操作之前,其他线程读取到的都是原本缓存中的旧值。甚至可能会由于缓存删除失败(如缓存服务当前不可用的情况)从而导致严重的缓存不一致问题。
那么如何解决这个问题呢?可以使用以下几种方法
修改缓存过期时间
这是解决这个问题最简单的方法,同时也是治标不治本的方法。
我们可以将缓存过期时间变短,使其每隔一段时间就会去数据库中加载数据,对于更新不频繁的数据来说,就可以很好的解决不一致的问题,但若是更新特别频繁的热点数据,这个方法则失去了作用。
由于这个方法的适用面小,且实时性和一致性不高,所以我们通常都会选择使用消息队列来解决这个问题。
消息队列
我们可以引入一个消息队列来解决这个问题,在更新数据库后,我们往消息队列中写入数据,等到消费者从消息队列中取出数据时,再将缓存删除。借助消息队列的消息重试机制来保证我们一定能够成功删除缓存,从而确保缓存的一致性。

但是这种方法也存在几个问题
- 引入消息队列后可能会因为消息的处理导致一定程度的延迟,从而引起短期内的消息不一致
- 引入消息队列后导致问题整体复杂化
所以我们只有在对实时性和一致性要求不高的情况下才会选择这种做法