

目录

Redis企业级解决方案_Redis脑裂

什么是Redis的集群脑裂
Redis的集群脑裂是指因为网络问题,导致Redis Master节点跟Redis slave节点和Sentinel集群处于不同 的网络分区,此时因为sentinel集群无法感知到master的存在,所以将slave节点提升为master节点。

注意:
此时存在两个不同的master节点,就像一个大脑分裂成了两个。集群脑裂问题中,如果客户端还在基于原来的master节点继续写入数据,那么新的Master节点将无法同步这些数据,当网络问题 解决之后,sentinel集群将原先的Master节点降为slave节点,此时再从新的master中同步数据, 将会造成大量的数据丢失。
解决方案
redis.conf配置参数:
min-replicas-to-write 1
min-replicas-max-lag 5

1.Redis的集群脑裂是指_____问题。网络
2.Redis的集群脑裂通过配置____命令解决。min-replicas-max-lag
Redis企业级解决方案_缓存预热

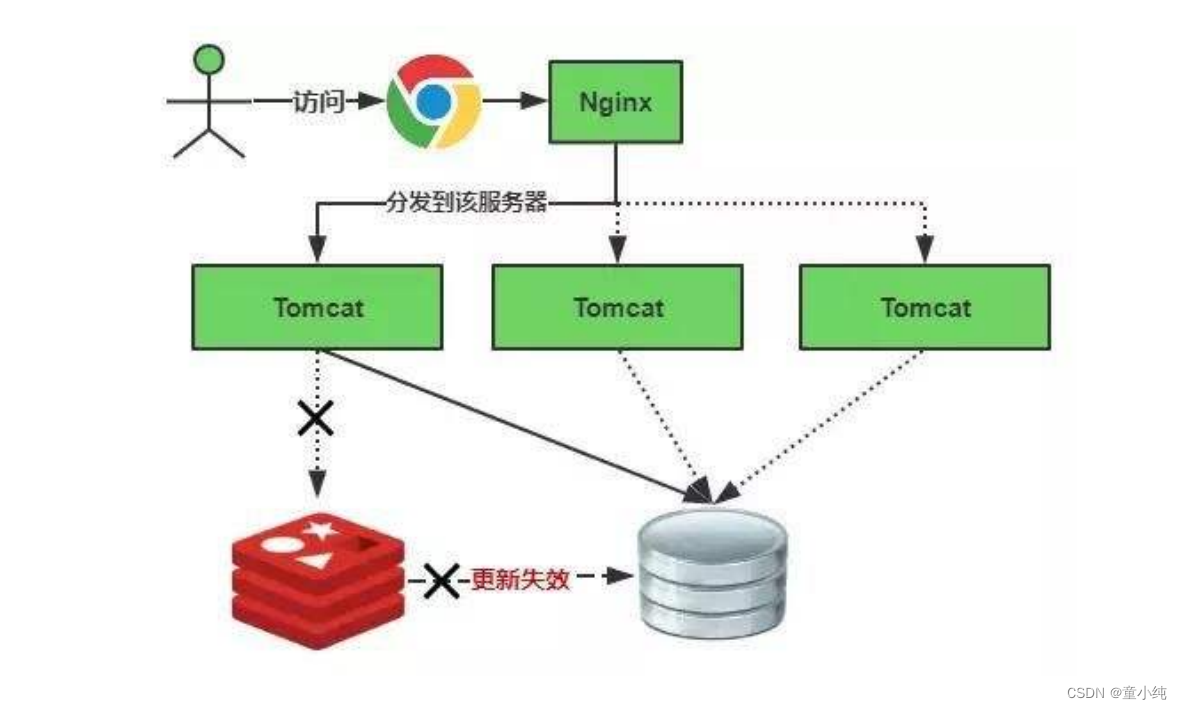
缓存冷启动
缓存中没有数据,由于缓存冷启动一点数据都没有,如果直接就对外提供服务了,那么并发量上来 Mysql就裸奔挂掉了。
缓存冷启动场景
新启动的系统没有任何缓存数据,在缓存重建数据的过程中,系统性能和数据库负载都不太好,所以最好是在系统上线之前就把要缓存的热点数据加载到缓存中,这种缓存预加载手段就是缓存预热。


1.Redis技术中缓存预热主要解决____问题。 缓存冷启动
Redis企业级解决方案_缓存穿透

概念
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别 大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。


解决方案
1. 对空值缓存:如果一个查询返回的数据为空(不管数据是否存在),我们仍然把这个空结果缓存, 设置空结果的过期时间会很短,最长不超过5分钟。
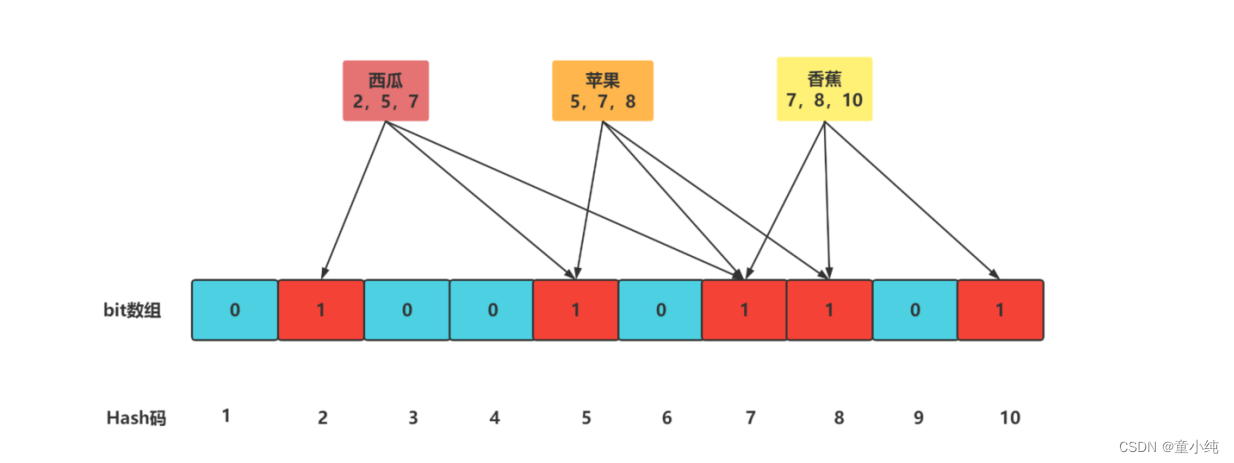
2. 布隆过滤器:如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起 来,然后通过比较确定。
布隆过滤器
什么是布隆过滤器
布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效 地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。

代码实现
引入hutool包
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.7.17</version>
</dependency>java代码实现
// 初始化 注意 构造方法的参数大小10 决定了布隆过滤器BitMap的大小
BitMapBloomFilter filter = new BitMapBloomFilter(10);
filter.add("123");
filter.add("abc");
filter.add("ddd");
boolean abc = filter.contains("abc");
System.out.println(abc);
1.布隆过滤器是一种数据库结构,底层是_____。 bit数组
2.Redis技术中缓存穿透主要指____问题。 缓存和数据库中都没有的数据
Redis企业级解决方案_缓存击穿
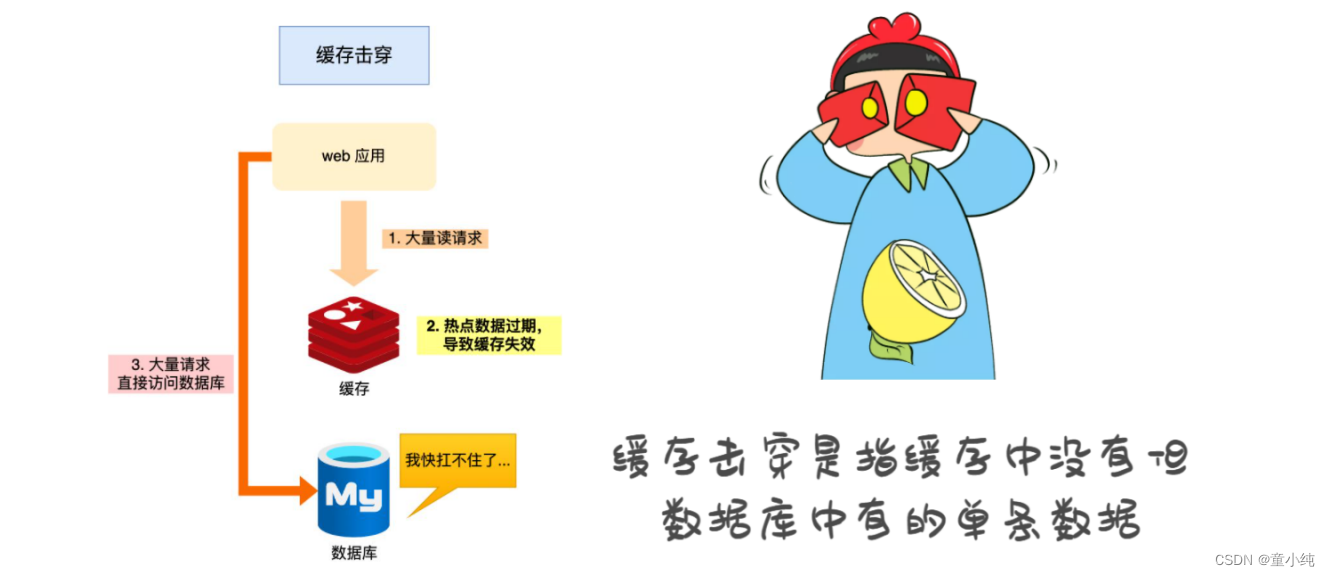
概念
某一个热点 key,在缓存过期的一瞬间,同时有大量的请求打进来,由于此时缓存过期了,所以请求最 终都会走到数据库,造成瞬时数据库请求量大、压力骤增,甚至可能打垮数据库

解决方案
代码实现
public String get(String key) throws InterruptedException { String value = jedis.get(key); // 缓存过期 if (value == null){ // 设置3分钟超时,防止删除操作失败的时候 下一次缓存不能load db Long setnx = jedis.setnx(key + "mutex", "1"); jedis.pexpire(key + "mutex", 3 * 60); // 代表设置成功 if (setnx == 1){ // 数据库查询 //value = db.get(key); //保存缓存 jedis.setex(key,3*60,""); jedis.del(key + "mutex"); return value; }else { // 这个时候代表同时操作的其他线程已经load db并设置缓存了。 需要重新重新获取缓存 Thread.sleep(50); // 重试 return get(key); } }else { return value; } }

1.Redis技术中缓存击穿指______问题。 缓存中没有但数据库中有的数据
2.Redis技术中缓存击穿如何解决。加互斥锁
Redis企业级解决方案_缓存雪崩

概念
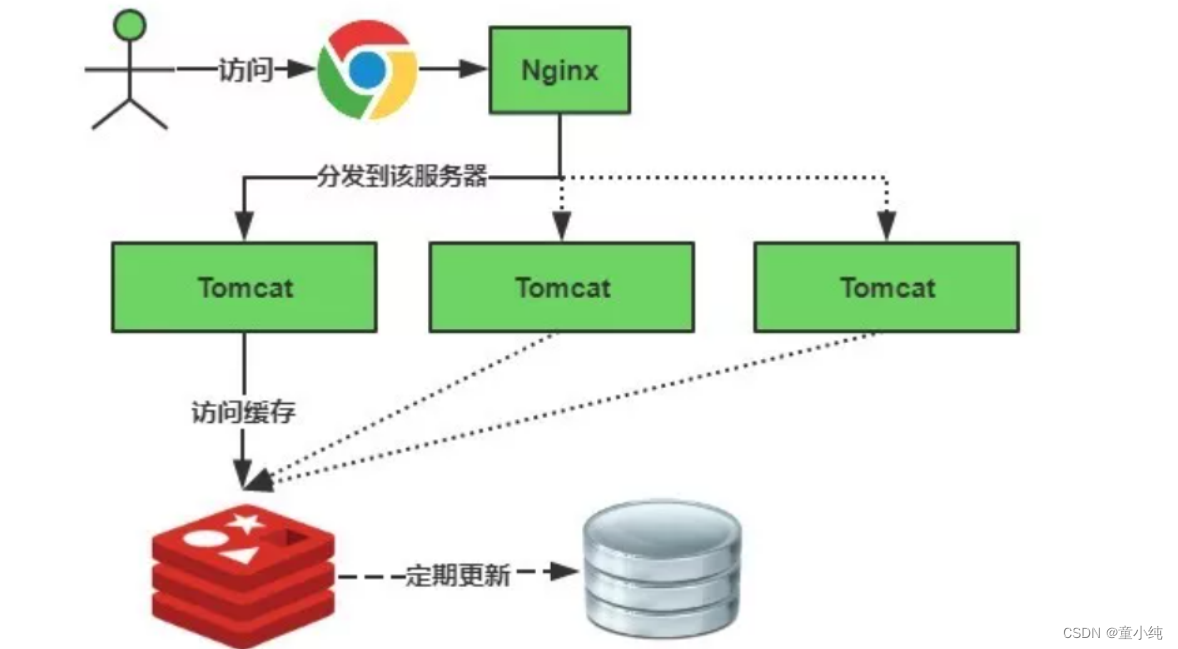
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发 到DB,DB瞬时压力过重雪崩。
缓存正常从Redis中获取,示意图如下:
缓存失效瞬间示意图如下:
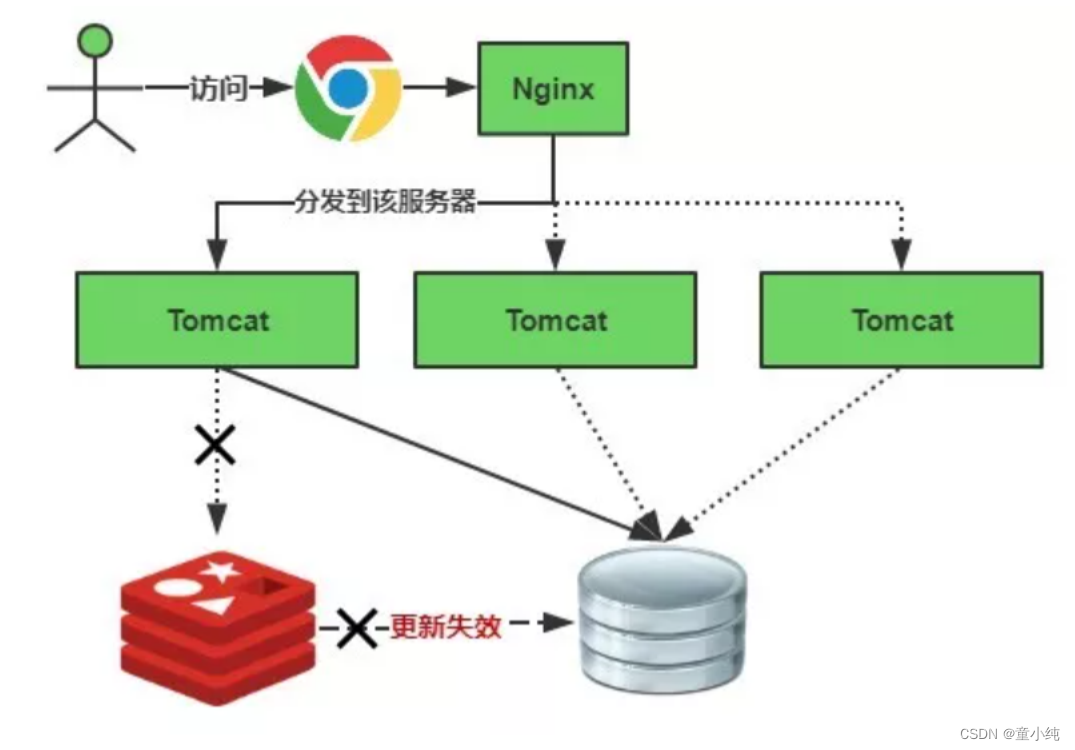
解决方案
过期时间打散:既然是大量缓存集中失效,那最容易想到就是让他们不集中生效。可以给缓存的过期时间时加上一个随机值时间,使得每个 key 的过期时间分布开来,不会集中在同一时刻失效。
热点数据不过期:该方式和缓存击穿一样,也是要着重考虑刷新的时间间隔和数据异常如何处理的情况。
加互斥锁: 该方式和缓存击穿一样,按 key 维度加锁,对于同一个 key,只允许一个线程去计算, 其他线程原地阻塞等待第一个线程的计算结果,然后直接走缓存即可。
加锁排队代码如下:
public Object GetProductListNew(String cacheKey) {
int cacheTime = 30;
String lockKey = cacheKey;
// 获取key的缓存
String cacheValue = jedis.get(cacheKey);
// 缓存未失效返回缓存
if (cacheValue != null) {
return cacheValue;
} else {
// 枷锁
synchronized(lockKey) {
// 获取key的value值
cacheValue = jedis.get(cacheKey);
if (cacheValue != null) {
return cacheValue;
} else {
//这里一般是sql查询数据
// db.set(key)
// 添加缓存
jedis.set(cacheKey,"");
}
}
return cacheValue;
}
}
注意: 加锁排队只是为了减轻数据库的压力,并没有提高系统吞吐量。
1.Redis技术中缓存雪崩指____问题。缓存中数据大批量到过期时间
2.Redis技术中缓存雪崩____解决。 缓存数据的过期时间设置随机
Redis企业级解决方案_Redis开发规范



示例
# 表名 主键 主键值 存储列名字 set user:user_id:1:name xiaoton set user:user_id:1:age 20 #查询这个用户 keys user:user_id:9*
value设计
拒绝bigkey
防止网卡流量、慢查询,string类型控制在10KB以内,hash、list、set、zset元素个数不要超过5000。
命令使用
1、禁用命令
禁止线上使用keys、flushall、flushdb等,通过redis的rename机制禁掉命令,或者使用scan的方式渐 进式处理。
2、合理使用select
redis的多数据库较弱,使用数字进行区分,很多客户端支持较差,同时多业务用多数据库实际还是单线 程处理,会有干扰。
3、使用批量操作提高效率
4、不建议过多使用Redis事务功能
Redis的事务功能较弱(不支持回滚),而且集群版本(自研和官方)要求一次事务操作的key必须在一个slot 上。

客户端使用
1. Jedis :https://github.com/xetorthio/jedis 重点推荐
2. Spring Data redis :https://github.com/spring-projects/spring-data-redis 使用Spring框架时推荐
3. Redisson :https://github.com/mrniko/redisson 分布式锁、阻塞队列的时重点推荐
1、避免多个应用使用一个Redis实例
不相干的业务拆分,公共数据做服务化。
2、使用连接池
可以有效控制连接,同时提高效率,标准使用方式:
执行命令如下: Jedis jedis = null; try { jedis = jedisPool.getResource(); //具体的命令 jedis.executeCommand() } catch (Exception e) { logger.error("op key {} error: " + e.getMessage(), key, e); } finally { //注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。 if (jedis != null) jedis.close(); }
1.Redis技术中下列符合key设计__。user:id.1.age
Redis企业级解决方案_数据一致性
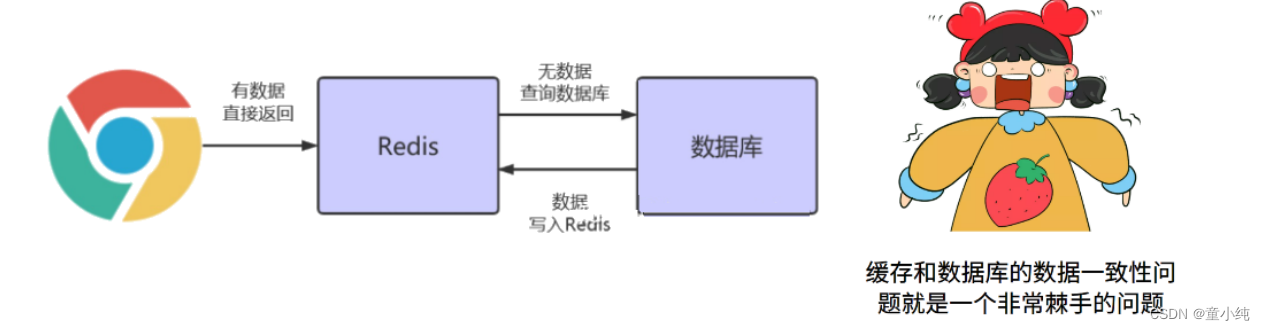
缓存已经在项目中被广泛使用,在读取缓存方面,大家没啥疑问,都是按照下图的流程来进行业务操作。
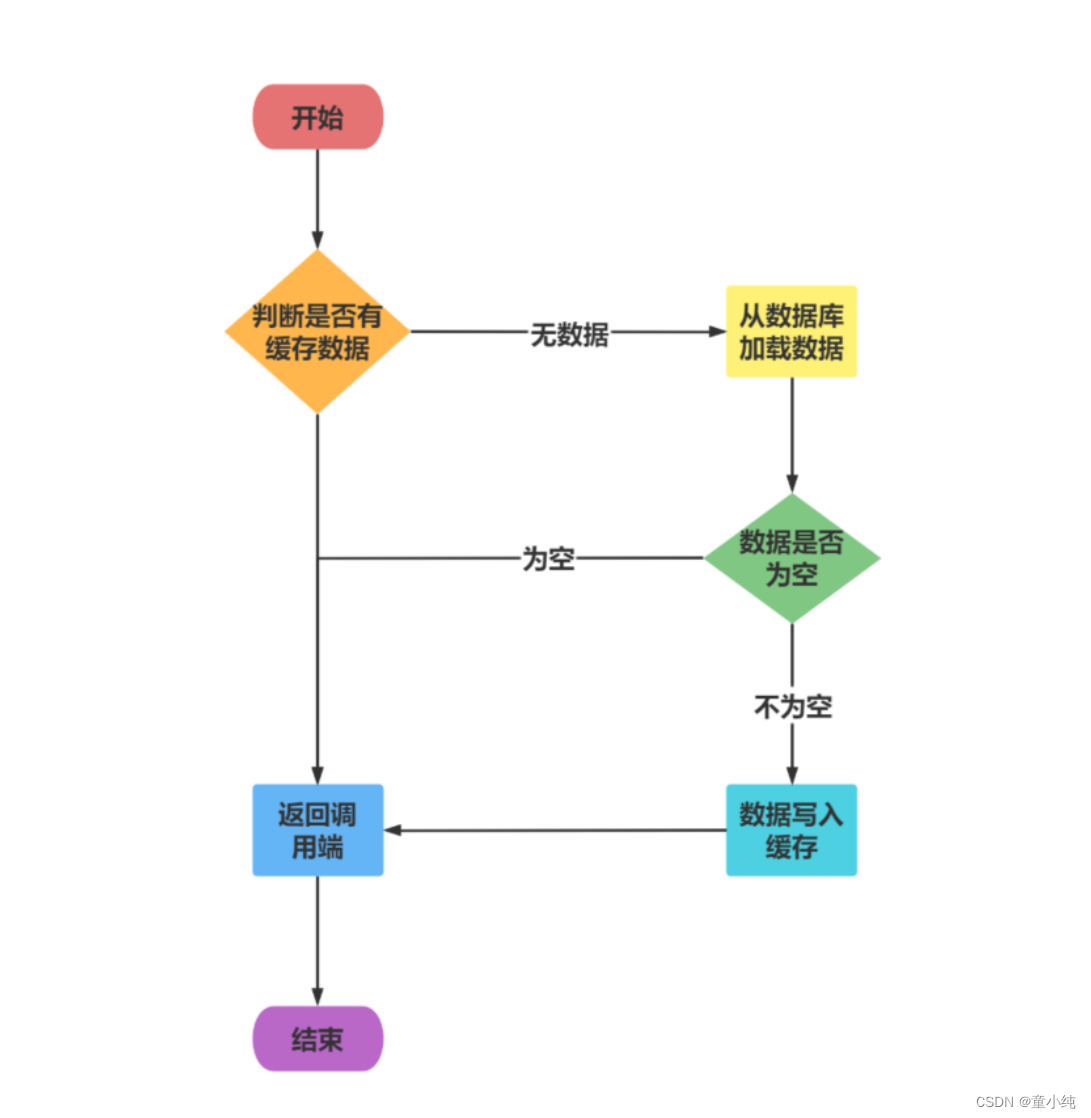
缓存说明: 从理论上来说,给缓存设置过期时间,是保证最终一致性的解决方案。
三种更新策略
1. 先更新数据库,再更新缓存
2. 先删除缓存,再更新数据库
3. 先更新数据库,再删除缓存
先更新数据库,再更新缓存
这套方案,大家是普遍反对的。为什么呢?
线程安全角度
同时有请求A和请求B进行更新操作,那么会出现
(1)线程A更新了数据库
(2)线程B更新了数据库
(3)线程B更新了缓存
(4)线程A更新了缓存 这就出现请求A更新缓存应该比请求B更新缓存早才对,但是因为网络等原因,B却比A更早更新了缓存。 这就导致了脏数据,因此不考虑。
先删缓存,再更新数据库
先更新数据库,再延时删缓存
1.Redis技术中哪一种保证数据一致性最合理。设置过期时间


