转载:https://blog.csdn.net/Dustin_CDS/article/details/79595297
使用Redis缓存的模式的有很多种,下面就逐一介绍。
一、数据库和redis分别处理不同的数据类型
数据库处理要求强一致实时性的数据,例如金融数据、交易数据;
redis处理不要求强一致实时性的数据,例如网站最热贴排行榜;
二、Cache-Aside模式
Cache-Aside模式的意思是业务代码直接维护缓存,这是最常用的一类模式。
2.1 读场景
先从缓存获取数据,如果缓存没有命中,则回源到数据库获取源数据。
将数据放入到缓存,下次即可从缓存中获取数据。
放入缓存的可以是异步的(创建一个新的线程),也可以是同步的,根据实际情况自己选择。
2.2 非高并发情况下的写场景
先将数据写入数据库,写入成功后立即同步将数据写入缓存。
2.3 写多读少的写场景
先将数据写入数据库,写入成功后,将缓存数据过期/删除,下次读取时再加载缓存。
这样的好处是避免了不必要的写缓存操作。
2.4 高并发情况下的写场景
先写缓存,再定期更新数据库:
异步化,先写入redis的缓存,就直接返回;定期或特定动作将数据保存到mysql,可以做到多次更新,一次保存。
三、Cache-As-SoR(Redis不支持)
SoR:system of record,记录系统,或者叫数据源;数据库是数据源的一种。
Cache-As-SoR即把Cache看作SoR,所有操作都是对Cache进行,然后Cache再委托给SoR进行真实的读写。即业务代码中只看到Cache的操作,看不到关于SoR相关的代码。
3.1 Read-Through
业务代码读Cache,如果不命中,由Cache读SoR。使用Read-Through模式需要一个CacheLoader组件来回源到SoR加载数据。Guava Cache和Ehcache 3.X都支持该模式。
3.2 Write-Through
对应Read-Through,需要有一个CacheWriter组件来回写SoR。Guava Cache不支持,Ehcache 3.X支持该模式。
3.3 Write-Behind
与 Write-Through 的区别是,Write-Through是同步写SoR,Write-Behind是异步写,从而可以实现批量写、合并写、延时写和限流。
四、订阅/曾量更新模式
canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB)。
基于日志增量订阅&消费支持的业务:
- 数据库镜像
- 数据库实时备份
- 多级索引 (卖家和买家各自分库索引)
- search build
- 业务cache刷新
- 价格变化等重要业务消息
4.1 MySQL主备复制原理
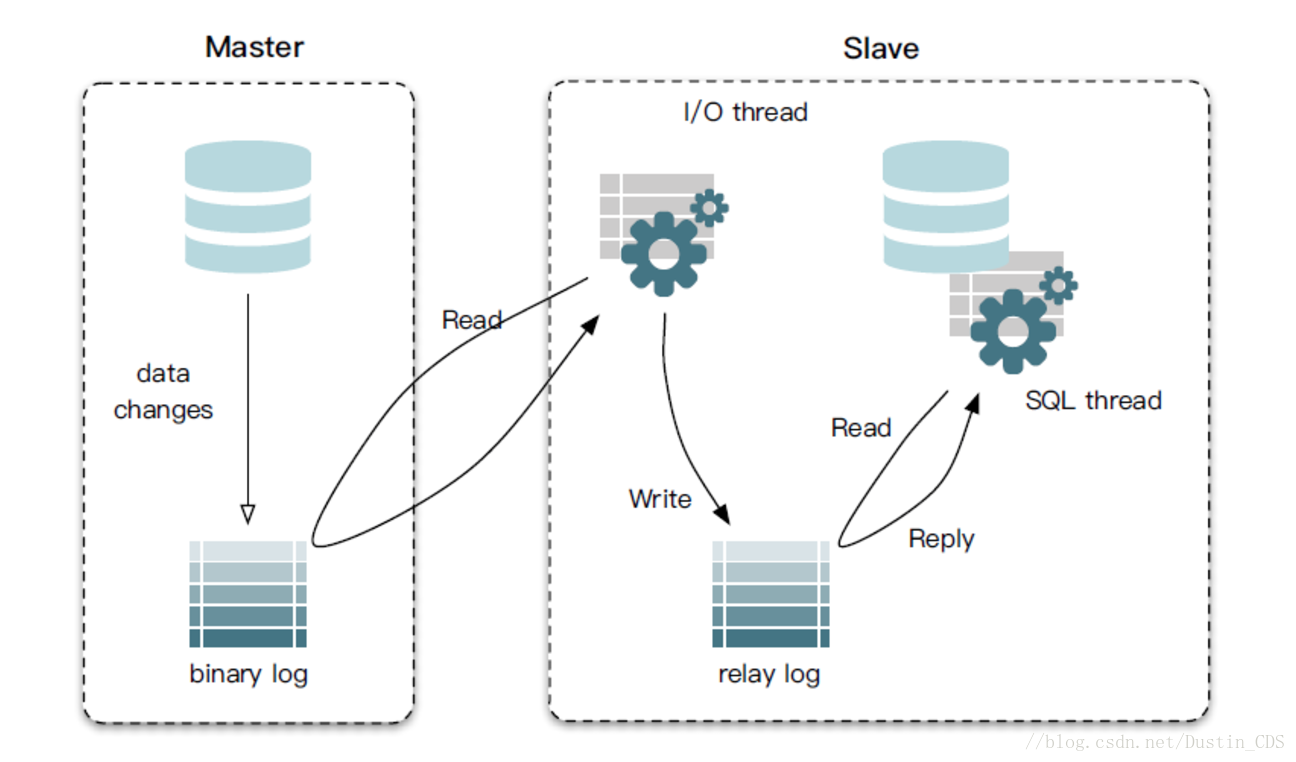
从上层来看,复制分成三步:
master将改变记录到二进制日志binlog中(binary log events可以通过show binlog events进行查看);slave将master的binlog events拷贝到它的中继日志relay log;- slave**重做**中继日志中的事件,将改变反映它自己的数据。
4.2 canal的工作原理
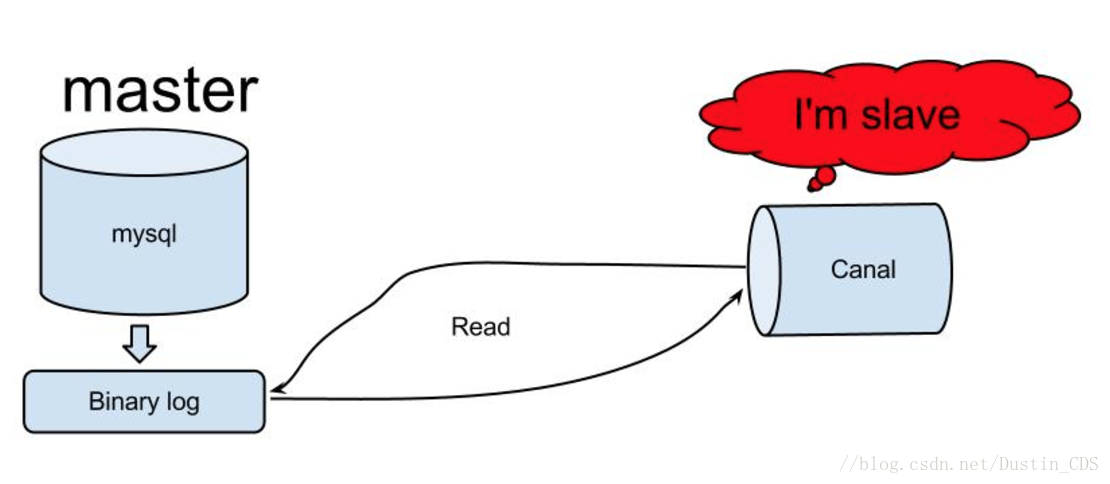
原理相对比较简单:
canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump请求;- mysql master收到dump请求,开始推送binary log给slave(也就是canal);
- canal解析binary log对象;
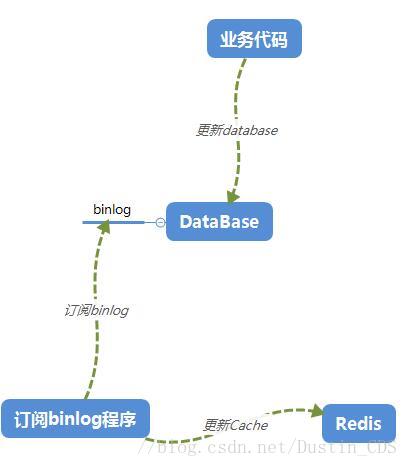
4.3 通过Canal订阅MySQL的Binlog并更新Redis
package com.datamip.canal;
import java.awt.Event;
import java.net.InetSocketAddress;
import java.util.List;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry.Column;
import com.alibaba.otter.canal.protocol.CanalEntry.Entry;
import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;
import com.alibaba.otter.canal.protocol.CanalEntry.EventType;
import com.alibaba.otter.canal.protocol.CanalEntry.Header;
import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.InvalidProtocolBufferException;
public class App {
public static void main(String[] args) throws InterruptedException {
// 第一步:与canal进行连接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("192.168.23.170", 11111),
"example", "", "");
connector.connect();
// 第二步:开启订阅
connector.subscribe();
// 第三步:循环订阅
while (true) {
try {
// 每次读取 1000 条
Message message = connector.getWithoutAck(1000);
long batchID = message.getId();
int size = message.getEntries().size();
if (batchID == -1 || size == 0) {
System.out.println("当前暂时没有数据");
Thread.sleep(1000); // 没有数据
} else {
System.out.println("-------------------------- 有数据啦 -----------------------");
PrintEntry(message.getEntries());
}
// position id ack (方便处理下一条)
connector.ack(batchID);
} catch (Exception e) {
// TODO: handle exception
} finally {
Thread.sleep(1000);
}
}
}
// 获取每条打印的记录
@SuppressWarnings("static-access")
public static void PrintEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
// 第一步:拆解entry 实体
Header header = entry.getHeader();
EntryType entryType = entry.getEntryType();
// 第二步: 如果当前是RowData,那就是我需要的数据
if (entryType == EntryType.ROWDATA) {
String tableName = header.getTableName();
String schemaName = header.getSchemaName();
RowChange rowChange = null;
try {
rowChange = RowChange.parseFrom(entry.getStoreValue());
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
EventType eventType = rowChange.getEventType();
System.out.println(String.format("当前正在操作 %s.%s, Action= %s", schemaName, tableName, eventType));
// 如果是‘查询’ 或者 是 ‘DDL’ 操作,那么sql直接打出来
if (eventType == EventType.QUERY || rowChange.getIsDdl()) {
System.out.println("rowchange sql ----->" + rowChange.getSql());
return;
}
// 第三步:追踪到 columns 级别
rowChange.getRowDatasList().forEach((rowData) -> {
// 获取更新之前的column情况
List<Column> beforeColumns = rowData.getBeforeColumnsList();
// 获取更新之后的 column 情况
List<Column> afterColumns = rowData.getAfterColumnsList();
// 当前执行的是 删除操作
if (eventType == EventType.DELETE) {
PrintColumn(beforeColumns);
}
// 当前执行的是 插入操作
if (eventType == eventType.INSERT) {
PrintColumn(afterColumns);
}
// 当前执行的是 更新操作
if (eventType == eventType.UPDATE) {
PrintColumn(afterColumns);
}
});
}
}
}
// 每个row上面的每一个column 的更改情况
public static void PrintColumn(List<Column> columns) {
columns.forEach((column) -> {
String columnName = column.getName();
String columnValue = column.getValue();
String columnType = column.getMysqlType();
boolean isUpdated = column.getUpdated(); // 判断 该字段是否更新
System.out.println(String.format("columnName=%s, columnValue=%s, columnType=%s, isUpdated=%s", columnName,
columnValue, columnType, isUpdated));
});
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
需要注意的是,缓存的更新会存在延迟,所以缓存可根据不一致容忍度设置合理的过期时间。