-
支持向量机SVM为什么需要优化?
支持向量机是机器学习中常见的一种算法,特别是软间隔的支持向量机在解决非线性的分类与回归问题时特别常见,其相比硬间隔的支持向量机而言,增添了松弛变量,能够允许一些错误的发生,通过参数惩罚因子c衡量松弛变量,当惩罚因子变大,要求松弛变量的值尽量小,对错误的容忍度减小,但这就牵扯到一个参数c的如何选取,这与最终SVM模型的泛化能力挂钩
同时我们知道在做非线性问题时,我们需要用到核技巧,将低维的线性不可分数据映射到高维直到线性可分,如果我们一直向高维进发,我们是有能力将数据完全线性划分开,但是这样就可能会引发过拟合,也会影响最终SVM模型的泛化能力,因此我们在做核技巧时也需考虑一些影响模型泛化能力的因素;我们通常使用的非线性核——高斯核(RBF),而高斯核有一个参数gamma(简称g),参数g主要是对低维的样本进行高度度映射,gamma值越大映射的维度越高,训练的结果越好,但是越容易引起过拟合,即泛化能力低,也就是我们之前提到的问题
综上两个方面,我们有必要考虑SVM模型的泛化能力,毕竟我们需要的是一个具有鲁棒性的泛化模型;而不是一份训练集数据的"COPY",因此我们需要考虑如上两个参数c与g的选取,那么如何选取这两个参数呢,我们采用的是一种随机局部搜索策略——粒子群算法 -
基础版的粒子群算法(PSO)
粒子群算法通俗的解释,其实就是一堆的粒子,跟随着其中离目标最近的粒子在搜索空间中跑来跑去搜索;就像其中一个粒子说俺旁边就是目标,于是乎一大堆粒子都蜂拥而至向着靠近,离目标的远近通过适应度函数衡量,这也是所有智能群算法的套路,用到的公式如下:
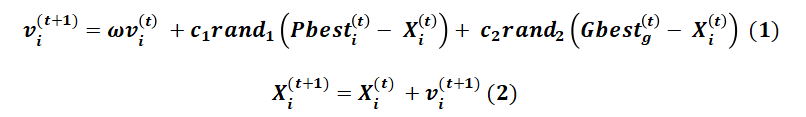
其中每一个粒子都具有速度属性Vi,与位置Xi;在每一次迭代过程中,速度与位置的更新公式如上;速度的更新是依据两个方面进行,首先是个体认知方面,首先它有一个个体认知的加速度c1参数,它作为根据个体历史最优值更新速度时的参数;社会认知方面,它有一个社会认知加速度c2,它作为根据社会(全局)历史最优值更新速度时的参数;如上公式的表达已经很清楚,Pbesti(Personal)即是个体历史最优,Gbesti(Global)即是社会(全局)历史最优,Xi即是当次迭代粒子的位置;而最后一个参数w,即为惯性因子w,与原速度相乘,顾名思义可以理解为保持原速度的量化标准;关于位置的更新就没什么好说的,公式清晰明了
但是基础的粒子群算法具有的缺点还是很明显的,面临的两个最大的问题是收敛的速度和陷入局部最小值;这是很致命的,特别是在搜索的后期一大堆的粒子都聚集在一起,移动速度还慢,聚集在最优解附近算运气好,但是聚集在局部最优时跑都跑不出去,于是乎有人提出了改进的粒子群算法,自适应的粒子群算法 -
自适应的粒子群算法(APSO)
自适应的粒子群算法,在原有的基础上,它增加了3个改进的方面:
① 进化状态评估(ESE):
每一次粒子群移动后,都有一个全局的状态记录,目的是为了收敛的状态进行评估和划分,为后面自适应参数(c1,c2,w)提供基础状态的划分步骤:
步骤一:计算每个粒子i的相对于其他粒子的平均距离(欧式距离),与其他粒子都计算一遍距离,最后求平均值;公式如下:

其中N是种群的大小,D为问题的维数,在我们优化SVM问题中,问题的维数为2,因为我们只优化2个参数(c,g)
步骤二:在众多di中选取dg,g为当前最优粒子的下标, 故dg代表了当前最优粒子与其他粒子的平均距离;同时选取中dmax与dmin,最大与最小平均距离;计算进化因子f;公式如下:

步骤三:根据进化因子f,选择当前隶属于哪一种状态,如下图,采用有规则基准的方式:

在提出该算法的论文中,对于这部分的描述我不是很理解,但根据该图来理解还是很直观的:
我们将状态划分为四类:
S1探索(Exploration)、S2发现(Exploitation)、S3收敛(Convergence)、S4跳出(Jumping-out)
我们通过上图,即可判断当前应该选择哪一种状态:(1) f < 0.3:
我们可以看见上图在0.2~0.3部分是有两种状态S1与S2交织的,如果f落在该范围,我们需要选择其中一个,那么我们需要判断之前是什么状态,如果之前状态是S1(即在图中位于S2之后),那么此时状态可以改变为S2,否则状态要变化为S1;这样做是由于不能过度切换状态,需要保持划分的稳定性,因此在f<0.3还是划分到S1
(2) 0.3 <= f < 0.6:
与上面同样的分析方式,在重叠部分0.4~0.6,也是需要判断上一次状态是否是S4,如果是,那么状态可以变化到S1;否则状态为S2扫描二维码关注公众号,回复: 12460234 查看本文章
(3) 0.6 <= f < 0.8:
在重叠部分0.7~0.8,需要判断上一次状态是否是S3,如果是,那么状态可以变化到S4;否则状态为S1
(4) f >= 0.8:
均是划分为状态S4综上,虽然说在有重叠部分的划分依据看起来很玄学,但是其实可以直接用以下一个序列表达:S1=>S2=>S3 =>S4 => S1
如果位于分段中的重叠部分,需要判断是变化为分段中占大面积的状态还是占小面积的状态,只需要观察以上序列中,上一次的状态是否是小面积状态的前驱,如果是则变化为小面积状态,否则变化为大面积状态;比如,当前位于0.3 <= f < 0.6段,大比例状态是S2,小比例状态是S1;如果上一次状态是S4(S4 => S1,S4是S1的前驱),那么此时变化为S1;否则变化为S2②自适应参数(AP):
惯性因子w自适应:惯性权重是PSO算法中平衡全局和局部的搜索能力,w应该在探索阶段很大,而在开发阶段减小;w不是单纯的随着时间变化的,而应该随着进化状态的而变化,故w应该与进化因子f有如下的关系:

本文中w初始化设定是0.7,在跳出状态和探索状态下,较大的f和较大的w更有利于全局搜索,相反在开发状态和收敛状态下f较小,w会减小更有利于局部的搜索
加速度参数的控制:
(1) 参数c1:个体认知加速度,促进该粒子获得它历史上最好的位置,有利于开发局部中最好的解,增加粒子群的多样性
(2) 参数c2:社会认知加速度,它能推进粒子向全局中最好的区域收敛,加快收敛速度关于加速度参数的自适应变化,可以根据不同状态施以不同策略:
策略1:在探索状态下,我们可以增大个体认知加速度c1,增加粒子个体们分散在搜索空间中的搜索广度,进行开始阶段的泛搜;帮助粒子探索自身的最好个体,强调个体认知的过程,避免粒子过早聚集在最好粒子周围,陷入局部最优;相反地,弱化社会认知,减小社会加速度c2,不宜在搜索阶段就让粒子们过早地聚集起来,否则可能会滞留在局部最优中
策略2:在发现状态下,我们选择轻微增加个体认知加速度c1,轻微减小c2;这个状态下,粒子使用局部信息,种群朝着可能的局部最优区域移动,因此,轻微增加c1可以使c1维持在一个较大的值,可以强调在pBesti(个体最优)周围的搜索和开发。全局最优的粒子gBesti并不一定在这个状态处在真正的最优区域。所以轻微减小c2可避免算法过早收敛,陷入局部最优值
策略3:在收敛状态下,轻微增加c1与c2;在收敛状态下,群体似乎找到了全局的最优区域,因此,增加c2主要为了引领其他粒子向可能的全局最优区域移动。此时c1的值应该减小,这样有利于加速算法的收敛,但是这样的策略会使两个参数过早的到值达上下边界(会在下文中介绍边界的大小定义)这样可能会出现一种情况:即局部最优区域被当成全局最优区域,迅速收敛,最终陷入局部最优解;所以在此状态下,应该对c1 和c2都进行轻微的增加
策略4:在跳出状态下,减小c1并增加c2;此时粒子们跳出局部最优,跳出原先的聚类,此时急需朝着更优的方向前进,即原先聚在一起的粒子们会向某一个更优的粒子领导者前进,需要尽可能快地到达该领导者周围,因此,需要大一些的社会认知加速度c2,同时弱化个体认知加速度c1,放一放各自手头的工作,先响应号召
关于加速度参数的上下边界:
(1) 加速度率δ:为了使每一次变化c1与c2不太突兀,因此引入了加速度率δ,即每一次c1与c2变化不能超过δ,而δ的取值从[0.05,0.1]中随机产生;如果是轻微变化,则就不能超过0.5δ
(2) 归一化:应该保证每一次c1+c2不能超过4,因此需要对c1与c2进行归一化,使其和不超过4
③ 精英学习策略(ELS):
在实验中的有些情况下,单纯使用ESE来动态更新w和c1和c2,出现了算法不收敛的情况下,因此ELS是用于帮助全局最优粒子gBest在收敛状态时跳出局部最优区域;推进tgBest向着一个潜在最好区域前进
ELS选择了目标问题的其中随机一个维度进行变化,加入高斯扰动,过程如下:
 其中σ是精英学习率,随着进化的代数而变化:
其中σ是精英学习率,随着进化的代数而变化:
 其中σmax、σmin根据经验显示分别为1与0.1
其中σmax、σmin根据经验显示分别为1与0.1 -
APSO & SVM
在文章的最后会给出APSO优化SVM的代码,由于我们只需优化两个参数,其实问题的维度只有2维,即每一个粒子的位置向量只有2维,在APSO优化算法中我们只需嵌入一个计算适应度的函数;那么如何选取这个适应度函数呢?即如何评判参数的好坏呢?我们选用的方法是K-CV,即使用某一组c,g的SVM对训练数据集进行K折交叉验证,得到的评分结果,作为我们的适应度值;那么适应度函数实际上就是一次SVM的训练;我们使用matlab能够很简单的调用svmtrain作为我们的适应度函数;我使用的是10折交叉验证
-
相关代码(matlab代码)
自适应的粒子群算法(APSO)优化支持向量机(SVM)
猜你喜欢
转载自blog.csdn.net/Master1_/article/details/113726586
今日推荐
周排行