import torch
#构建的例子模型是线性模型 y=w*x
x_data=[1.0,2.0,3.0]
y_data=[2.0,4.0,6.0]
w=torch.tensor([1.0]) #构建一个1阶张量,就是一个一维数组。张量是神经网络的计算单元
w.requires_grad=True #这个张量是需要计算梯度的,默认不计算,让张量计算梯度,才能进行反向传播
def forward(x):
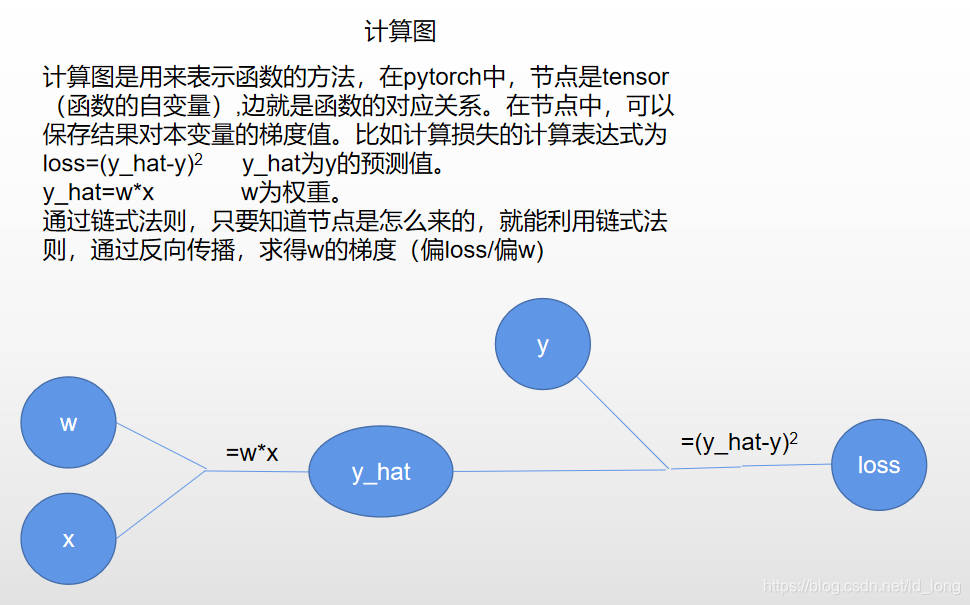
return x*w #*号已经被重载了。x会转换为张量。张量的运算实际上是在构建计算图。
#返回的结果也是一个张量。这个结果张量是可以反向传播的。
def loss(x,y):
y_hat=forward(x) #y_hat 是预测值。它是个张量,尽管这个张量只有一个数,
#但是张量的计算是构建计算图,如果用这个张量去计算,也能得到结果,
#但由于构建的是计算图,内存消耗会非常大。
return (y_hat-y)**2 #返回预测值相对于实际值的损失。返回的是个张量
for cycle in range(1000): #进行1000轮学习
for x,y in zip(x_data,y_data):
l=loss(x,y)
l.backward()
print('\tgrad:',x,y,w.grad.item()) #注意grad也是张量,打印是我们只关心它的值,
#通过item()就能访问它的值。
w.data=w.data-0.01*w.grad.data#注意不能写成:w=w-0.01*w。这样子是构建计算图。
#原来的w还是在内存中的。只是无法被直接访问。而我们希望的是更新原来的w的值,不希望构建计算图。
#所以修改的只是w.data。
w.grad.data.zero_() #这里要显式得对之前计算过的梯度清0。
#我们修改了data,但是原来的梯度其实还在的。如果不清零。
#下次计算梯度的时候,会把上次计算的加上去,使下次的梯度不是真正的梯度。而是梯度和。
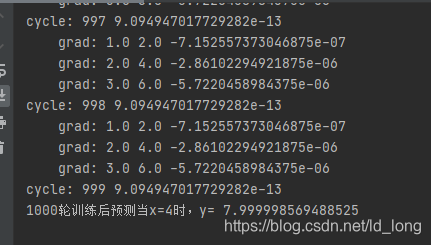
print("cycle:",cycle,l.item())
print("1000轮训练后预测当x=4时,y=",forward(4).item())
运行结果