1 什么是微博
微博是中国最大,最受欢迎的社交媒体网络平台。该网站是一个微博客平台(类似于 Twitter 或 Reddit),其功能包括消息传递,对文章进行评论,重新发布以及基于上下文浏览等的视频和图片推荐。2019 年,微博的每日活跃用户(DAU)超过 2.2 亿,每月活跃用户(MAU)达到 5.16 亿。基于人们的社交活动(例如,在世界范围内发布和共享新闻等),微博团队开发了一个社交网络,该社交网络可以将用户连接起来,并根据他们的活动和兴趣将内容分发到个人。

2 微博的机器学习平台(WML)
如下图所示,微博的机器学习平台(WML)由多层体系结构组成,从集群和资源管理一直到建模和推理训练组件。作为平台的核心,我们的集群部署由在线,离线和高性能计算集群组成,运行我们的应用程序和管道。
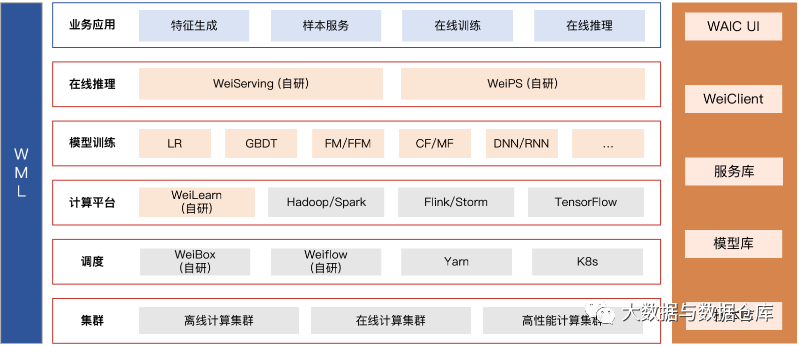
集群层之上是我们平台的调度层,该层由两个内部开发的框架(WeiBox 和 WeiFlow)组成,用于以统一的方式将作业提交给不同的集群。我们还利用YARN和Kubernetes用于资源管理。机器学习平台的第三层包含计算层,该层与我们内部开发的 WeiLearn 框架一起提供(在本文的以下各节中进行了详细说明),该框架使我们平台的用户可以定义自己的算法并构造自己的算法 UDF 以及多个集成的数据处理框架,例如 Hadoop,Flink,Storm 和 TensorFlow。我们架构的模型训练和在线预测层位于最顶层,可为公司提供不同的应用场景,包括特征生成,样本生成,在线模型训练和在线推断等。
为了更深入地了解微博中机器学习的执行方式,让我们介绍一下我们自己内部开发的两个用于微博机器学习的框架:WeiLearn 和 WeiFlow。
WeiLearn(在下面的图 3 左侧进行了说明)是在 Weibo 上建立的,它是我们的开发人员编写和插入自己的 UDF 的框架,它通过三个主要步骤进行操作:用于离线数据处理作业的 Input,Process 和 Output 和 Source,Process 和 Sink 处理我们的实时数据处理工作。另一方面,WeiFlow 是使用 Cron 表达式处理任务依赖性和计划的工具,例如从特定任务重新运行或在特定时间段回填多天的数据。
![]()
经过几次成功的迭代后,微博的机器学习平台现在在模型训练中支持超过 1000 亿个参数,每秒支持超过 100 万个查询(QPS),同时在早期的版本中我们成功的将迭代周期从每周的节减少到 10 分钟。
![]()
3 Apache Flink 在微博用于机器学习
Flink 在微博的机器学习平台中以及在我们平台的实时计算中均扮演着重要角色。实时计算平台的基础架构层由Apache Flink、Apache Storm集群构成,同时包含用于度量和监控的 Grafana 。Apache Flume and the ELK stack (ElasticSearch + Logstash + Kibana) 作为我们的日志记录系统。
使用 Flink 独特的抽象集及其统一的 API,我们能够在微博上强化我们的机器学习pipeline。我们之前有用于在线和离线模型以及推理训练的单独管道,每个管道使用不同的计算引擎,包括 Storm,Flink,Spark Streaming,Hive 和 MapReduce。最重要的是,我们有多个应用程序开发框架要使用和实现,这直接提升了开发团队的维护开销。
我们很快就开始问自己,是否需要维护两个不同的处理框架来满足我们的需求,在大多数情况下,答案是否定的。这就是我们开始使用Apache Flink作为核心将离线和实时数据集成到单个统一机器学习管道的过程。
![]()
4 Flink 在微博的在线模型训练管道
Flink 正在我们的在线模型训练管道中使用,如下图 6 所示。我们通过使用 Apache Flink 的计时器和状态来做过滤,映射和执行多流联接,从而将 Flink 用于管道的sample生成服务。然后,我们将数据集合输入到样本池中,即样本元数据的集合。样本池生成后,我们的模型训练服务(WeiLearn)会使用样本流来执行特征处理,特征预测和梯度参数计算,然后再将参数存储到 WeiPS。WeiPS 是我们的内部参数服务,包含两个单独的集群,一个集群用于在线预测,一个集群用于在线模型训练,以确保我们的在线模型预测工作的稳定性。最后一步 我们使用 CI / CD 和 CT / CD 工具来不断训练和部署我们的模型,自动执行的模型评估,稳定性和一致性检查。然后使用以下方式将模型提供给我们的分类服务fbthrift RPC 来实现最佳性能。
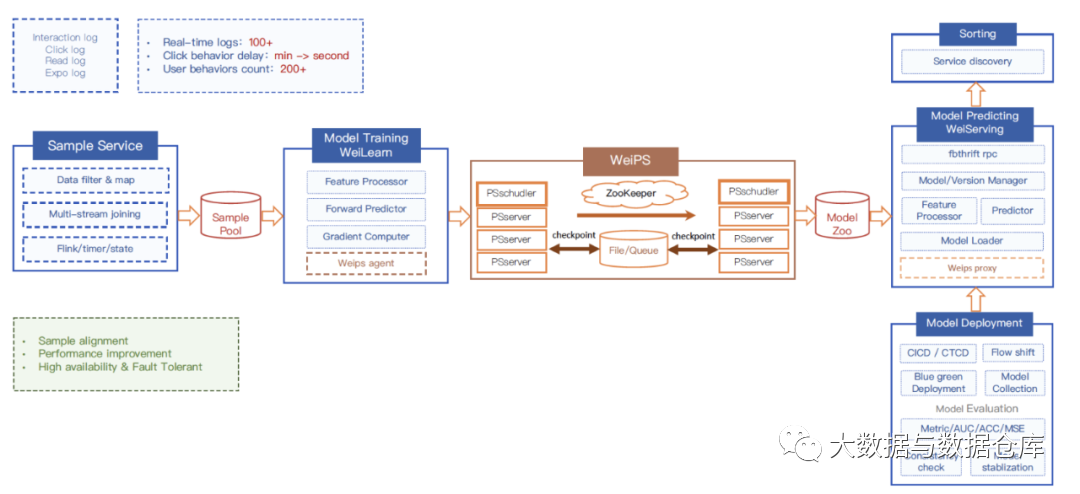
5 使用 Apache Flink 进行示例生成和多流联接
如前所述,Apache Flink 在微博机器学习平台的样本生成和样本池服务中起着至关重要的作用(如下图 7 所示)。我们的服务将离线数据和实时事件合并,并输入到基于 Apache Flink 的统一数据处理层,该层执行常规计算,多流连接和深度学习。在这里,我们引入了在线和离线数据上的一些附加特征(包括微博帖子,用户关系和多媒体内容)。一旦计算完成,就将结果与我们的样本池服务共享,然后再用于模型训练。

使用 Flink 的一大优点是该框架可以轻松执行多流联接。微博的样本服务将不同的数据源作为过滤和映射功能的输入(UDF 可以由本文前面解释的 WeiLearn 平台引入),如下所示:
@Override
public boolean filter(Tuple2<string, defaultoutmodel=""> data) throws Exception {
if (this.isEmptyTuple(data)) {
return false; // filter out empty records
}
DefaultOutModel outModel = data.f1;
String business = outModel.getRecord("business");
if (business.isEmpty() || !("xxx").equals(business)){
return false; // only consider "xxx" business
}
}
@Override
public Tuple2<string, defaultoutmodel=""> map(String source) throws Exception {
Map<string, string=""> detailMap = JsonUtil.fromJsonToObject(source, Map.class);
DefaultOutModel outModel = new DefaultOutModel();
// put into output
outModel.putRecord("lk_hour",
String.valueOf(detailMap.get("lk_hour")));
// put read from feature engineering into output
this.appendFeature(outModel, getFeature("userGender"));
String blogId = String.valueOf(detailMap.get("blogId"));
String userId = String.valueOf(detailMap.get("userId"));
// key = userId_blogId, value = output
this.processOut(Tuple2.of(userId + "_" + blogId, outModel));</string,></string,></string,>
然后,在应用其他过滤和映射功能或附加其他功能之前,按键分发数据并进入 10 分钟时间窗口内将其结合起来。
现在,让我们解释一下 Apache Flink 中联接时间窗口函数的使用如何使我们有效地管理无序或迟到事件。我们经常发现我们的某些事件会立即到达我们的窗口功能,例如“ click”事件,而其他事件类型(例如“ read”事件)可能会在几秒/分钟后到达。时间窗口功能可在 10 分钟的时间范围内收集用户的活动。然后,在将合并的结果作为输出发送到 Sample Stream 之前,我们将每个事件作为键值对存储在RocksDB中。这样做意味着我们能够保证将不同类型的事件有效地结合在一起。
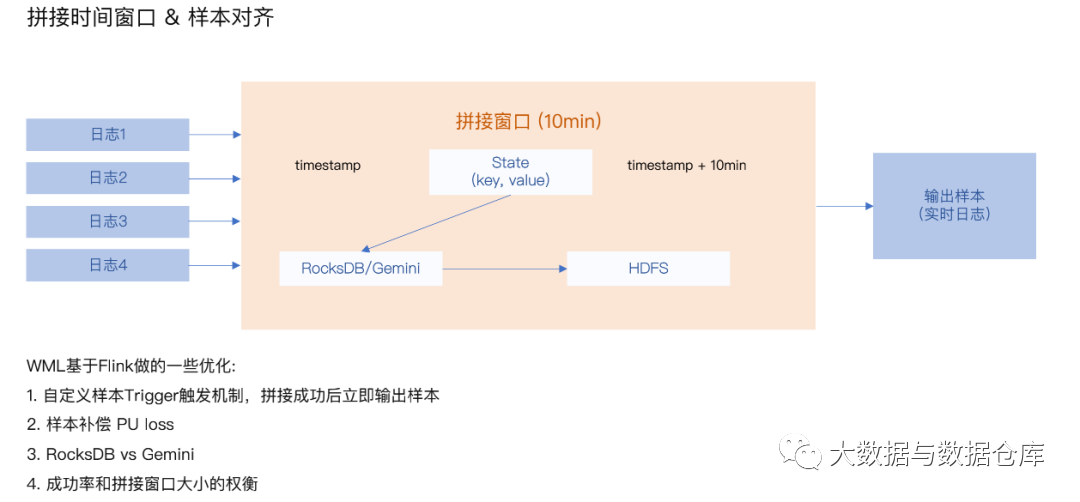
6 Flink 在微博的后续使用
如前几节所述,通过使用 Apache Flink,我们能够在微博上统一我们的在线和离线机器学习管道。由于这种统一不能应用于我们所有的内部用例,因此我们使用 Flink 的下一步包括为使用 Apache Flink 构建统一的数据仓库 ( https://flink.apache.org/features/2020/03/27/flink-for-data-warehouse.html )而付出的巨大努力。我们的一些工作包括增加对 SQL(Flink SQL 和 Hive SQL)的使用,以此为组织中的批处理和流处理作业提供单一代码库和开发模式。我们还希望提供适当的抽象 API,为我们的开发人员提供统一的表注册 API 和模式注册表,连接器和格式的元数据,如下图所示。
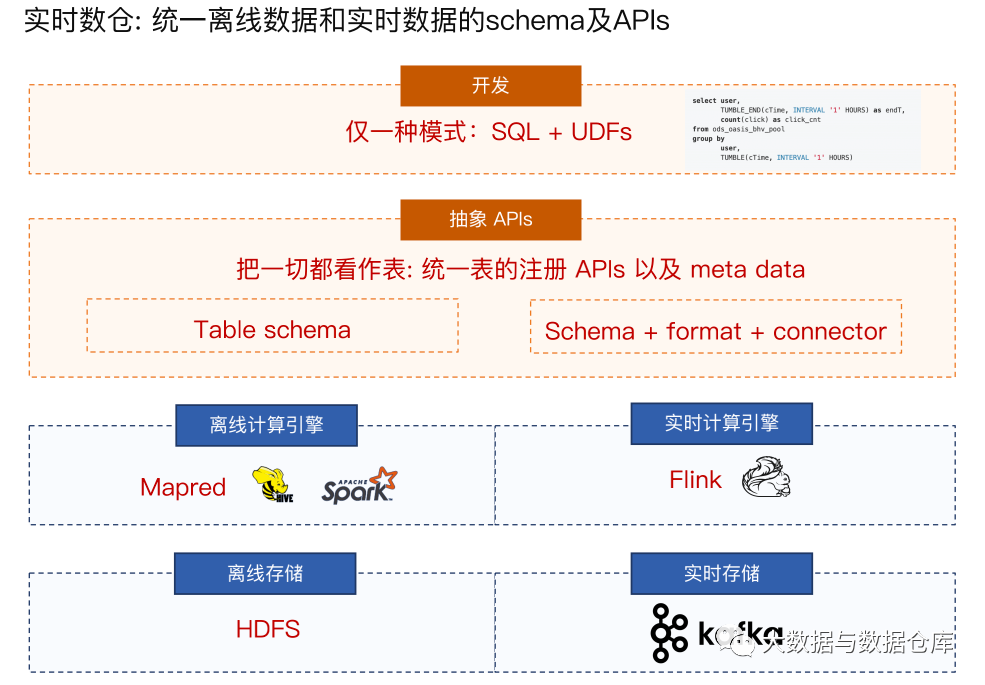
( https://flink.apache.org/ )为我们统一微博的批处理和流处理工作做出了巨大的贡献。该框架具有极高的可扩展性,可扩展到数百个实例,并处理为我们的机器学习管道处理的 PB 级数据。有关在微博上使用 Flink 的更多信息,包括我们如何执行加入时间窗以及我们使用 Flink 和 Tensorflow 进行深度学习的计划,可以观看我们的 Flink Forward Virtual 2020 PPT

回复 flink 获取Flink Forward 2020 PPT。
猜您喜欢
往期精选▼
Spark Shuffle调优之调节map端内存缓冲与reduce端内存占比
Flink中Checkpoint和Savepoint 的 3 个不同点