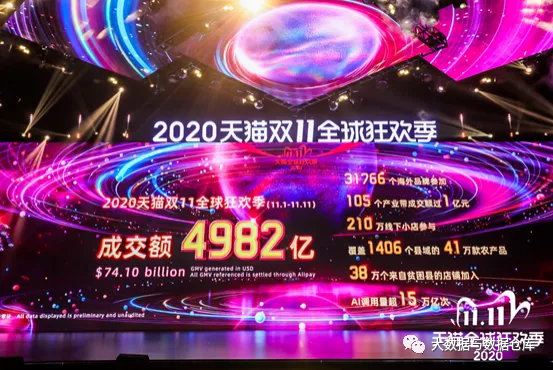
随着双11在11月12日午夜结束,2020 双十一购物节的商品总销售额(GMV)达到741亿美元。在Apache Flink的支持下,整个节日期间,GMV数值将稳定地实时显示在我们的大屏幕中。此外,在今年的活动中,基于Flink的阿里巴巴实时计算平台成功通过了年度测试。
除GMV仪表板外,Flink还为许多其他关键服务提供了支持。这些服务包括用于搜索和推荐的实时机器学习,实时广告反欺诈,菜鸟订单状态的实时跟踪和反馈,ECS实时攻击检测以及对大型基础架构的监视和警报。实时业务和数据量每年都在急剧增加。
今年,实时计算的峰值速率达到了每秒40亿条记录,而数据量达到了惊人的每秒7 TB。这相当于在一秒钟内阅读五百万本《新华字典》。
到目前为止,阿里云的实时计算工作数量已超过35,000。计算集群规模已扩展到超过150万个CPU,是迄今为止全球最大的Apache Flink集群。到目前为止,Flink已经满足了阿里巴巴数字经济的所有实时计算需求,并为客户,商家和运营人员提供了更好的。
此外,在今年的全球购物节期间,Flink首次对流和批处理进行了统一,并成功经受了阿里巴巴核心业务场景在稳定性,性能和效率方面的严格测试。
流和批处理的统一始于很久以前的阿里巴巴。Flink最初用于阿里巴巴的实时搜索和推荐方案中,在该方案中,索引构建和功能工程基于Apache Flink中统一流和批处理的初始版本。但是,在今年的双11中,Apache Flink进一步增强了流批统一的能力,以通过实时和离线数据之间的交叉验证来帮助阿里巴巴数据平台实现更准确的数据分析和业务决策。
阿里巴巴提供两种类型的数据报告:实时报告和离线报告。前者在双11提升方案中扮演重要角色。它可以为商人,运营人员等提供各种维度的实时信息。它还可以帮助他们及时做出决定,以提高平台和我们的业务效率。
以实时营销数据分析为例,运营人员和决策者需要比较不同时期的大型促销结果,例如促销日上午10:00的营业额与前一天同时的营业额。通过比较,他们可以确定当前的营销效果以及是否有必要执行其他活动或对促销执行任何控制机制。
在以前的场景中,需要两种数据分析报告。第一个是基于每晚的批处理计算的离线数据报告,第二个是通过流处理生成的实时数据报告。通过比较和分析实时和历史数据,可以及时,安全,准确地制定决策,以确保获得最佳结果。
如果没有统一的Apache Flink支持的流批一体化处理,则离线报告和实时报告将需要由单独的批处理和流引擎生成,从而导致开发成本翻倍,维护开销增加。由于分别使用了不同的引擎,这使得数据处理的一致性难以保证
使用单个引擎统一流和批处理进意味着离线和实时分析保持一致。借助Apache Flink中成熟的流和批处理统一架构,我们在搜索和推荐用例中成功部署了该架构。
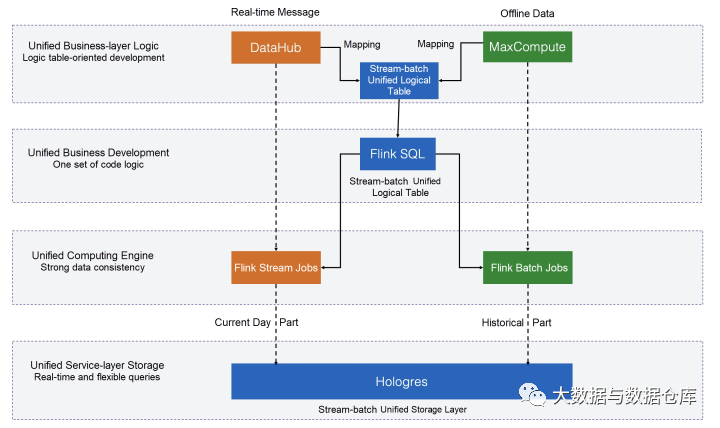
今年,由Flink和阿里巴巴的数据平台团队共同开发的流和批处理统一计算框架在双11期间首次亮相并用于该公司的核心数据用例场景。
由于流和批次的统一,多种计算处理模式只需要一组代码,而计算速度却是其他框架的两倍,而查询速度则是四倍。统一的批处理和流传输还使开发和生成数据报告的速度提高了四到十倍,并确保了实时和离线数据的完全一致性。
除了提高业务开发效率和计算性能外,统一的流和批处理计算体系结构还提高了群集资源的利用率。随着近年来的快速扩展,阿里巴巴的Flink实时集群现在包含数百万个CPU,并运行着数以万计的实时计算任务。
白天,计算资源被占用以进行实时数据处理。到了晚上,空闲的计算资源可以免费用于离线批处理。批处理和流处理都使用相同的引擎和资源,从而大大节省了开发,运营和管理以及资源成本。在今年的双11中,基于Flink的批处理和流应用程序未申请任何其他资源。批处理模式重用了Flink实时计算集群,极大地提高了集群利用率,并节省了大量资源开销。这种有效的资源利用模式也为后续更多的业务创新奠定了基础。
Apache Flink流批量统一,投入巨大精力
Flink的流和批处理体系结构的完全统一并不是一蹴而就的。在Flink的早期版本中,流和批处理在API和运行时方面都没有完全统一。随着Flink 1.9的发布,社区加快了框架流批量统一的改进和升级。Flink SQL是用户最主流的API,它率先实现了流批量统一语义。这允许用户仅使用一组SQL语句进行流和批处理管道开发,从而大大降低了开发成本

从功能的角度来看,Flink仍然是使用SQL和DataStream API的流和批处理计算的组合。用户代码以流模式或批处理模式执行。但是,某些业务场景通过在流计算和批处理之间自动切换,对流-批处理统一提出了更高的要求。
例如,在数据集成和数据湖的情况下,首先需要将数据库中的全套数据同步到HDFS或云存储服务。然后,数据库中的增量数据需要自动同步。在这种同步期间执行统一的流和批处理ETL处理。Flink将来将支持更智能的流批量统一方案。
阿里巴巴基于Flink的流批量统一的发展
阿里巴巴是中国第一家选择Flink的企业。2015年,搜索和推荐团队希望选择一种新的大数据计算引擎,以应对未来5至10年的挑战。新的计算引擎将有助于处理搜索和推荐后端中的大量项目和用户数据。考虑到电子商务行业对短等待时间的高要求,该团队希望新的计算引擎能够进行大规模批处理和毫秒级的实时处理。换句话说,引擎应该是流批量统一引擎。
那时,Spark的生态系统已经成熟,并且通过Spark Streaming提供了流批量统一功能。Flink被认为是一年前的顶级Apache项目。在对Spark和Flink进行研究和讨论之后,该团队同意,尽管Flink生态系统当时还不成熟,但其基于流处理的体系结构更适合流批量统一。因此,团队很快决定基于阿里巴巴内部Flink的内部改进和优化,构建用于搜索和推荐的实时计算平台。
经过团队一年的努力,基于Flink的实时搜索和推荐计算平台成功支持了2016年双十一全球购物节。阿里巴巴通过在核心场景的实践对基于Flink的实时计算引擎有了更深入的理解。在这之后,阿里巴巴的所有实时数据服务都迁移到了该平台。
经过一年的努力,Flink在2017年双十一全球购物节期间成功支持了阿里巴巴的实时数据服务,包括GMV仪表板和其他核心数据服务方案。
2018年,阿里云推出了基于Flink的实时计算产品,为中小企业提供云计算服务。阿里巴巴不仅要使用Flink解决自己的业务问题,还希望促进Flink开源社区的发展,并做出更多贡献。到2020年,全球几乎所有主流技术公司都将Flink用于实时计算。Flink已成为大数据行业中实时计算的事实上的标准。
Flink社区继续进行技术创新。在2020年双11全球购物节期间,基于Flink的流批一体化在天猫的核心营销决策系统中表现出色。此外,基于Apache Flink的流批一体化在搜索和推荐场景中成功完成了流批量索引和机器学习过程,证明了五年前我们选择Flink的决定取得了成功。
往期精选▼
Spark Shuffle调优之调节map端内存缓冲与reduce端内存占比
Flink中Checkpoint和Savepoint 的 3 个不同点
3种Flink State Backend | 你该用哪个?

回复 flink 获取Flink Forward 2020 PPT。

