文章目录
免费算力,白嫖党顶级薅羊毛!
愁笔记本差,又买不起台式机显卡的同学,请注意啦!今天cv调包侠分享一下自己这几天开始使用的阿里天池的免费GPU服务器,以及这篇文章介绍如何在天池的tesla p100 16gb显存的服务器上训练自己的深度学习视觉模型~我们以火灾浓烟检测为例子。
首先,大家可以看我Yolov5 吸烟检测文章与baseline,传送门,今天主要与大家分享一下国庆好礼~
国庆这几天呆在家里,可不能白费了,花点时间钻研一下新东西,我这几天尝试了百度AIstudio,Kaggle ,天池三个平台的免费算力,百度的大家都比较熟悉了,可惜小菜鸡不会paddle,又想跑自己的大模型,怎么办,怎么办,怎么办???
| 平台\ 信息 | 显卡 | 显存 |
|---|---|---|
| 百度AIstudio | Nvidia Teslav100 | 16GB |
| 阿里 天池 | Nvidia Teslap100 | 16GB |
| Kaggle | Tesla K80 | 12GB |
算力来说,百度的较好~,但是对于我们想用pytorch 和tensorflow ,以及Paddle还没入门的孩子来说,就建议来薅阿里天池的羊毛!因为Kaggle 速度很慢。
回到正题
一 阿里天池的使用篇
首先注册并进入阿里云实验室。

2、如何安装、卸载、更新包?如遇错误怎么办?
1)安装包:pip install some_package --user
2)卸载包:部分包有依赖,无法卸载
3)更新包:pip install -U some_package –user
如果导入过程出错,建议尝试重启kernel或刷新页面
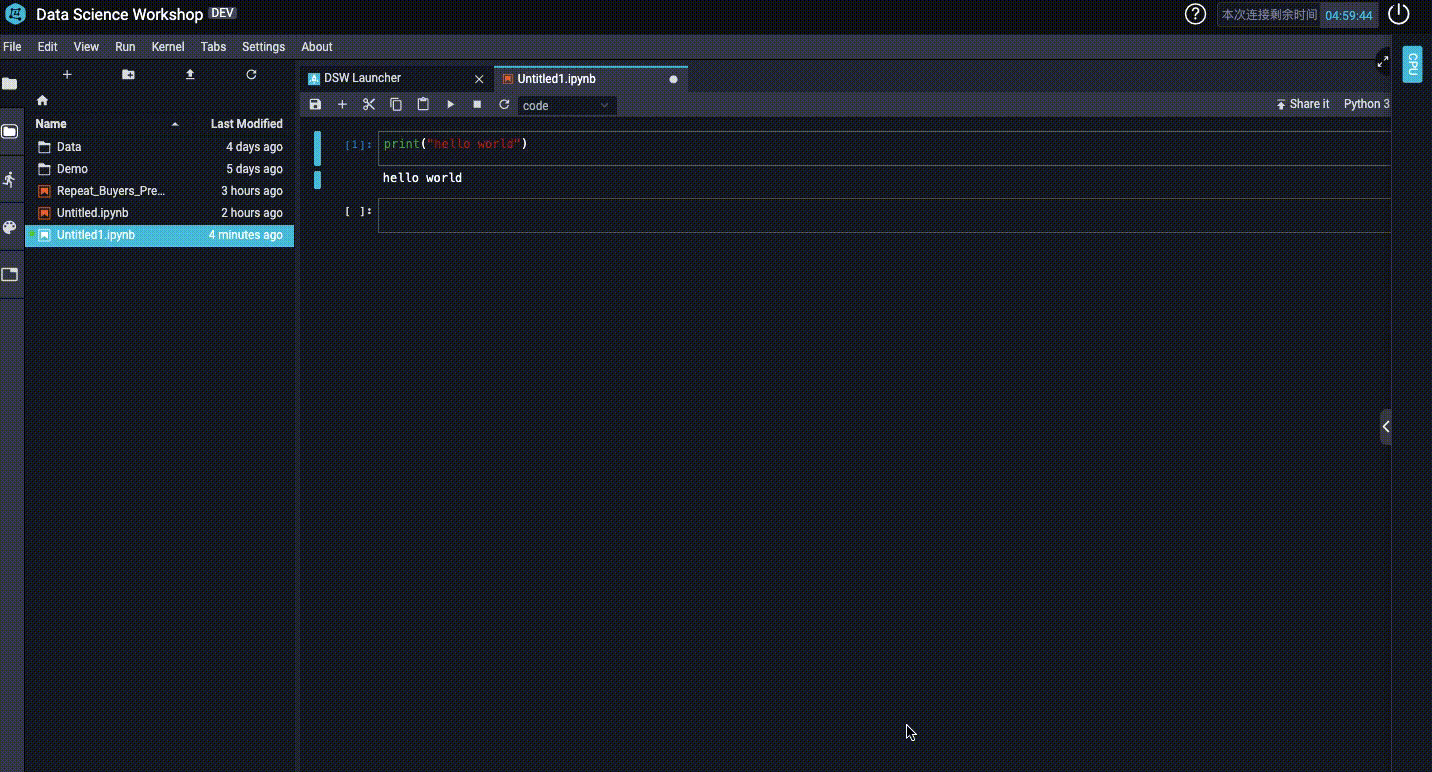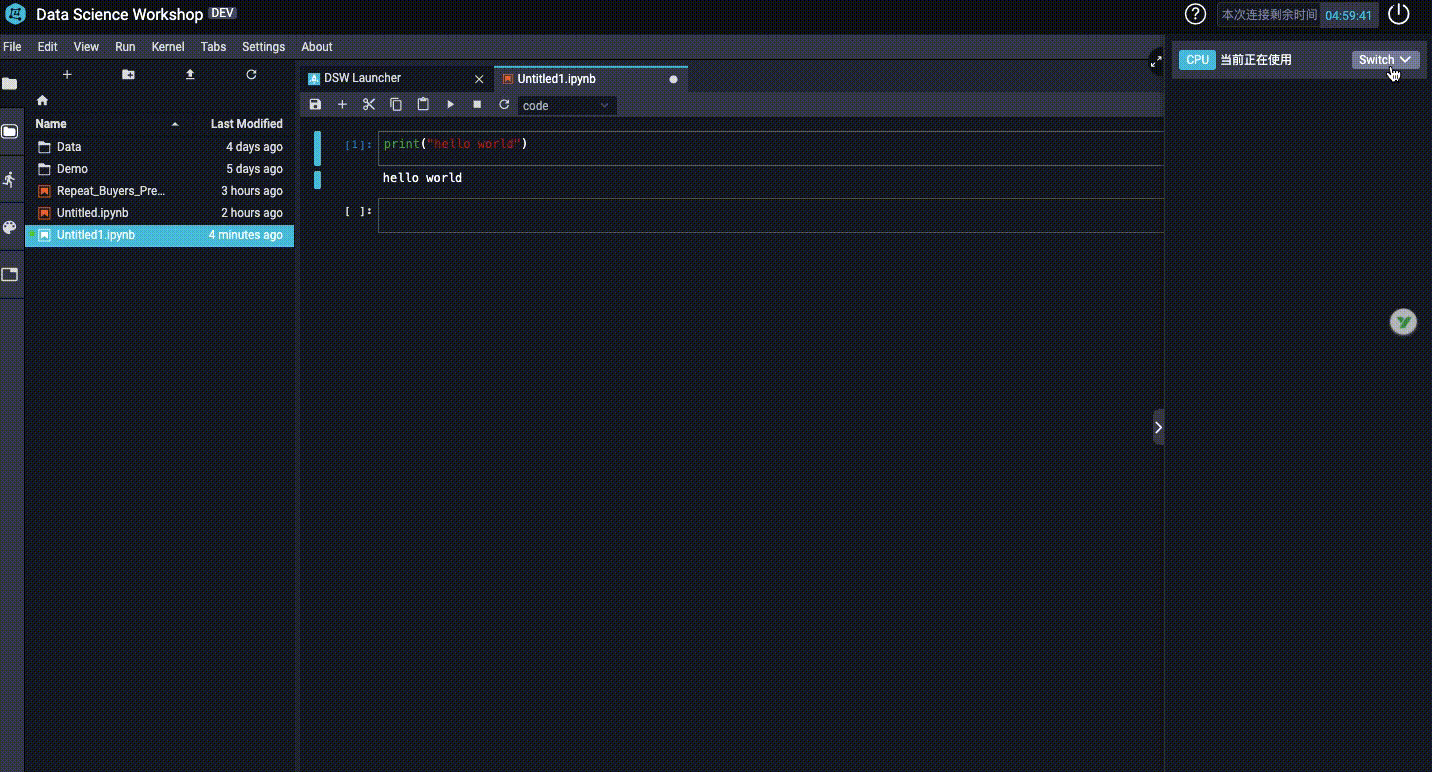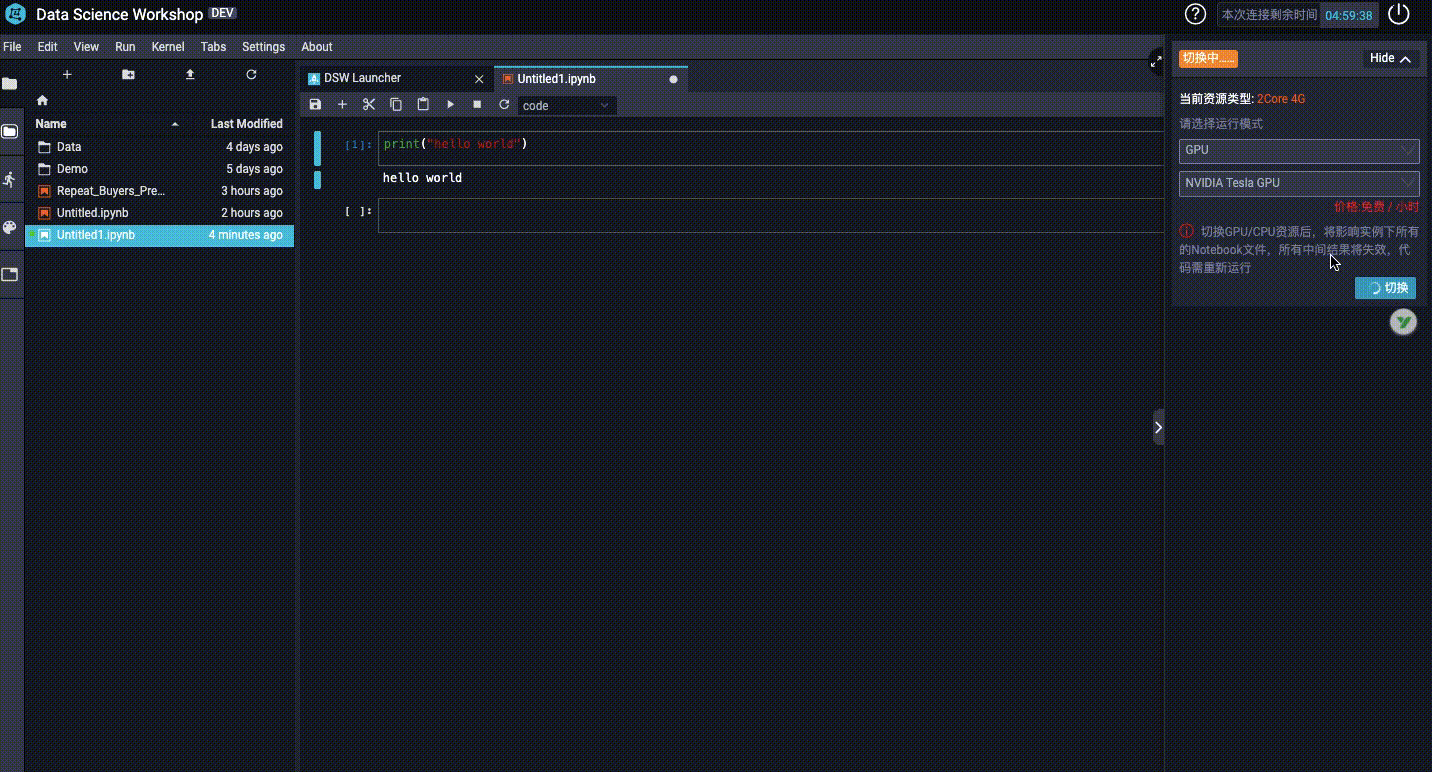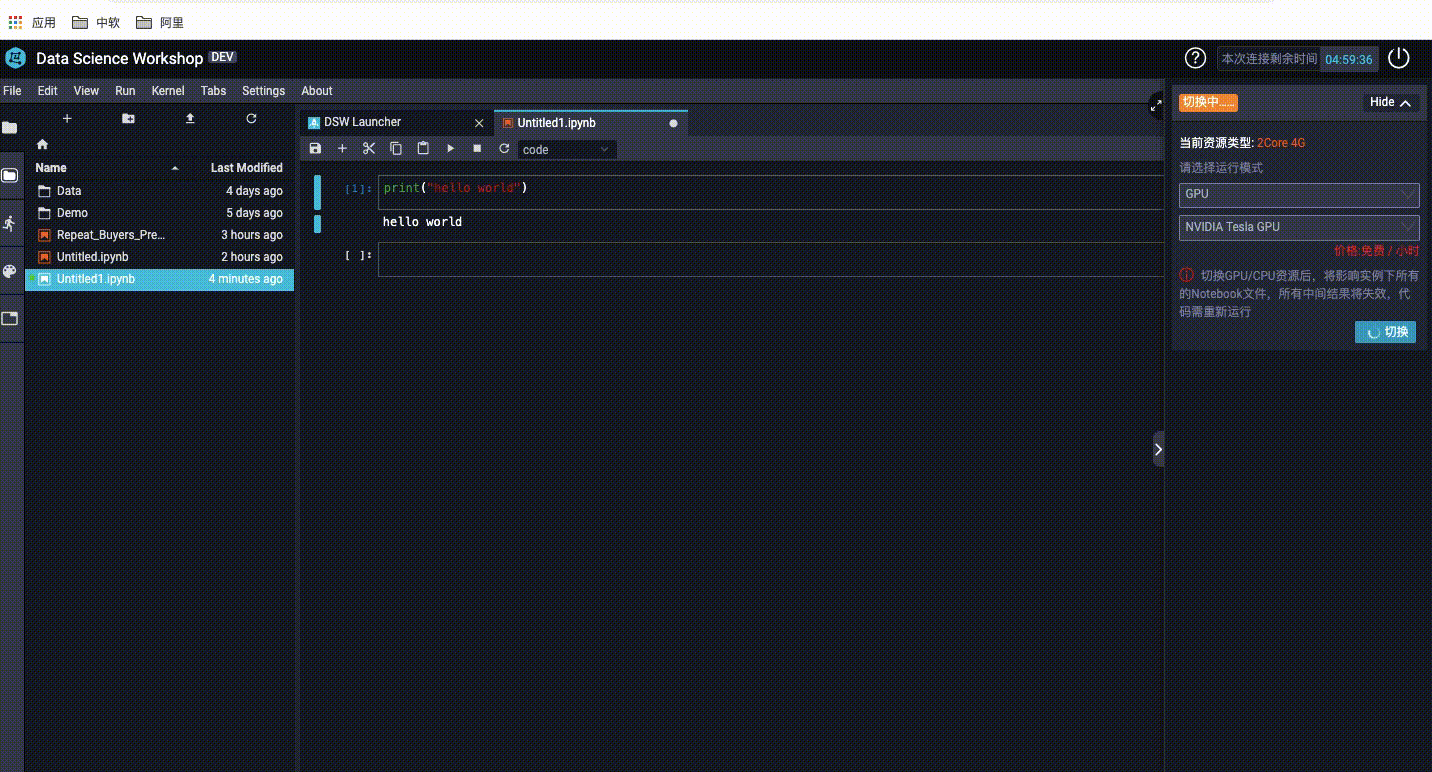
3、如何切换GPU和CPU?
二 开启我们在天池服务器的第一个项目: 火灾浓烟与吸烟检测
2.1 演示






2.2 介绍
本项目为基础baseline ,数据为5000的香烟图片与3000的火灾图片,为两类别检测(因为后续需要做校园等场景异常行为监控,所以将以前的吸烟检测也加入进来了);
图片如下(已放至公众号:Deep AI 视界 公众号回复:火灾检测):



三 模型训练
先clone 我的项目:https://github.com/CVUsers/Fire-Detect-by-YoloV5(欢迎star~)
或者 git clone https://github.com/CVUsers/Fire-Detect-by-YoloV5.git
到本地进行调试,跑通后再放到阿里云服务器加大模型直接跑~
然后公众号 DeepAI 视界回复:火灾检测
会拿到一份8000张左右的图片images.7z
解压到data下,data下的目录应为:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VBfQt1tS-1601784638378)(D:\CSDN\pic\天池\1601776984096.png)]](https://img-blog.csdnimg.cn/20201004121601728.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ2MDk4NTc0,size_16,color_FFFFFF,t_70#pic_center)
其中,train.txt ,labels,test.txt我已经给您写好,不用重新制作数据,若是需要重新制作数据,请参考我的另一篇文章:
令将yolov5预训练模型放至weights/下(我的网盘有)
需要注意的有几点:
1:labels中名字要与images中的图片名字对应(后缀不同),且要归一化成:id, x,y,w,h;
2:修改data下的smoke.yaml 为如下(已为您修改)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8Ne93a96-1601784638379)(D:\CSDN\pic\天池\1601777255275.png)]](https://img-blog.csdnimg.cn/20201004121632231.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ2MDk4NTc0,size_16,color_FFFFFF,t_70#pic_center)
3:修改models/ yolov5x.yaml 中的类别为你的类别(已为您修改);
4:train的args修改batchsize等参数
四 天池端训练
tips:您可以用小模型yolov5s进行测试,跑一个迭代没问题后,就可以改成yolov5x ;
然后将整个项目压缩成压缩包,进入阿里实验室,打开notebook,点击上传文件:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-R0YZYCCl-1601784638381)(D:\CSDN\pic\天池\1601778097520.png)]](https://img-blog.csdnimg.cn/20201004121648173.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ2MDk4NTc0,size_16,color_FFFFFF,t_70#pic_center)
然后在notebook右侧改成使用gpu:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BIrVkCmS-1601784638385)(D:\CSDN\pic\天池\1601778143859.png)]](https://img-blog.csdnimg.cn/20201004121705675.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ2MDk4NTc0,size_16,color_FFFFFF,t_70#pic_center)
检测是否为gpu环境:notebook左侧+号,新建一个terminal,输入nvidia-smi即可,若显示16gb就是gpu环境,如是cpu环境,会显示command not found
tips:若是由于自己操作失误,gpu被程序误占满,停不下来,就在终端输入 fuser -v .dev/nvidia* 看到占用显卡的进程,然后kill 掉他的编号即可
现在开始解压压缩包,我是7z压缩包(其他压缩包命令请自查):
notebook中输入:
!pip install py7zr
a = py7zr.SevenZipFile('./Fire-Detect-by-YoloV5','r')
a.extractall(path=r'./')
a.close()
print('over')
等待over(可能需要一些时间)后,双击解压好的文件夹进入项目
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ucfD6SpJ-1601784638388)(D:\CSDN\pic\天池\1601778826053.png)]](https://img-blog.csdnimg.cn/20201004121738792.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ2MDk4NTc0,size_16,color_FFFFFF,t_70#pic_center)
你可以左上角➕加号,新建python3的ipynb文件,然后输入:
%load train.py
Tips 此时,将main中的一行修改一下(因为是notebook版的参数解析方式):
opt = parser.parse_args()改成
opt = parser.parse_known_args()[0]
当前的pytorch版本是符合我们项目要求的,你需要安装一个opencv-python
终端输入:
pip install opencv-python==3.4.2.17
然后在我们的train.py 代码上按下shift+enter执行这个脚本,即可:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kUIdBpOW-1601784638389)(D:\CSDN\pic\天池\1601779323817.png)]](https://img-blog.csdnimg.cn/20201004121801797.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ2MDk4NTc0,size_16,color_FFFFFF,t_70#pic_center)
此图中,可看到模型参数分布与维度;一共是8.8*10^7次方参数
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hkqpIIKG-1601784638396)(D:\CSDN\pic\天池\1601779473179.png)]](https://img-blog.csdnimg.cn/20201004121817749.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ2MDk4NTc0,size_16,color_FFFFFF,t_70#pic_center)
等待训练结束,同时会将模型保存在weights/下
Tips:如果8小时的时长不够用,8小时后停止了迭代,那就重启实例,并修改train.py 的args中为:
–resume 这一行加一个default = True,将–weights的模型改成weights/last.pt ,然后执行
你就会发现,会继续原有模型训练~
然后训练结束后,将模型中的best.pt 右键download到本地(在云端测试也行,不过云端不能开摄像头,可以测试图片和视频),我以本地为例,将best.pt放到本地的weights/下,将detect.py 的参数:–source 改成0 运行即可。
if __name__ == '__main__':
check_git_status()
parser = argparse.ArgumentParser()
parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/coco128.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='', help='hyp.yaml path (optional)')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16)
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='train,test sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const='get_last', default=False,
help='resume from given path/to/last.pt, or most recent run if blank.')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--weights', type=str, default='', help='initial weights path')
parser.add_argument('--name', default='', help='renames results.txt to results_name.txt if supplied')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')
opt = parser.parse_args()
cfg,data,weights:前面看过了是一定要传的两个参;
hyp:超参数,是指定一些超参数用的(学习率啥的);
epochs: 轮数,默认300,需要指定;
batch-size:一次喂多少数据,yolov5x 16gb显存,数据量大只能开到12,所以可以不传按默认16;
img-size: 训练和测试数据集的图片尺寸(个人理解为分辨率),默认640,640nargs='+' 表示参数可设置一个或多个;
rect: 只要加上’–rect’程序就会将rect设为true(应该是训练时启用矩形训练);
resume: 断开后继续原有last.pt训练;
notest:only test final epoch,仅在最后测试,节省时间与资源(这样训练中间变化趋势应该就看不到了);
evolve:进化超参数(hyp),可以试试,但是加了这个,源码那边就不建议每次迭代完都保存模型了,可能是最后保存;
cache-images:cache images for faster training,加快训练的,可以试试;
name:renames results.txt to results_name.txt if supplied;
device:cuda device, i.e. 0 or 0,1,2,3 or cpu,我这默认已经用了tesla p100了,不用改;
single-cls:train as single-class dataset,暂时没用;
解释一下result.png里都是啥:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6Z2adUS9-1601784638398)(D:\CSDN\pic\天池\1601781211748.png)]](https://img-blog.csdnimg.cn/20201004121834360.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ2MDk4NTc0,size_16,color_FFFFFF,t_70#pic_center)
- GIoU:推测为GIoU损失函数均值,越小方框越准;
- Objectness:推测为目标检测loss均值,越小目标检测越准;
- Classification:推测为分类loss均值,越小分类越准;
- Precision:准确率(找对的/找到的);
- Recall:召回率(找对的/该找对的);
- [email protected] & [email protected]:0.95:这里说的挺好,总之就是AP是用Precision和Recall作为两轴作图后围成的面积,m表示平均,@后面的数表示判定iou为正负样本的阈值,@0.5:0.95表示阈值取0.5:0.05:0.95后取均值。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vNKqqNRV-1601784638399)(D:\CSDN\pic\天池\1601784586318.png)]](https://img-blog.csdnimg.cn/20201004121901304.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ2MDk4NTc0,size_16,color_FFFFFF,t_70#pic_center)
五 总结与技巧
总的来说,这阿里天池的服务器比较方便,网络速度也可以。
我已经准备长期入驻阿里云天池实验室,为以后去达摩院扫地做铺垫–_--,叫:cv调包侠,欢迎来fork~
总结一下上文的所有tips:
敲黑板:
tips:您可以用小模型yolov5s进行测试,跑一个迭代没问题后,就可以改成yolov5x放到服务器训练 ;
tips:若是由于自己操作失误,gpu被程序误占满,停不下来,就在终端输入 fuser -v .dev/nvidia* 看到占用显卡的进程,然后kill 掉他的编号即可
tips:参数解析要修改如下:
opt = parser.parse_args()改成
opt = parser.parse_known_args()[0]
Tips:如果8小时的时长不够用,8小时后停止了迭代,那就重启实例,并修改train.py 的args中为:
--resume 这一行加一个default = True,将--weights的模型改成weights/last.pt ,然后执行
你就会发现,会继续原有模型训练~
tips:可以开多个账号,在其他浏览器的页面上训练其他模型。
六 总结
欢迎关注个人公众号:DeepAI 视界 公众号回复火灾检测有好礼哟~
