我们之前做过一期基于Yolov5的口罩检测系统(手把手教你使用YOLOV5训练自己的目标检测模型-口罩检测-视频教程_dejahu的博客-CSDN博客),里面的代码是基于YOLOV5 6.0开发的,并且是适用其他数据集的,只需要修改数据集之后重新训练即可,非常方便,但是有些好兄弟是初学者,可能不太了解数据的处理,所以我们就这期视频做个衍生系列,主要是希望通过这些系列来教会大家如何训练和使用自己的数据集。
本期我们带来的内容是基于YOLOV5的火灾检测系统,火灾检测系统还是比较有实际意义的,也方便大家在背景描述中展开。废话不多说,还是先看效果。

考虑到有的朋友算力不足,我这里也提供了标注好的数据集和训练好的模型,获取方式有两种:
-
获取方式1:
在B站视频三连并关注后留下邮箱,我会每晚发送给大家,视频地址如下:
-
获取方式2:
直接在csdn中付费下载,资源地址如下:
需要远程调试的小伙伴可以加QQ 3045834499, 三连的好兄弟只49元就可以获取远程调试的服务。
下载代码
代码的下载地址是:[YOLOV5-fire-42: 基于YOLOV5的火灾检测系统 (gitee.com)](https://github.com/ultralytics/yolov5)

配置环境
不熟悉pycharm的anaconda的小伙伴请先看这篇csdn博客,了解pycharm和anaconda的基本操作
如何在pycharm中配置anaconda的虚拟环境_dejahu的博客-CSDN博客_如何在pycharm中配置anaconda
anaconda安装完成之后请切换到国内的源来提高下载速度 ,命令如下:
conda config --remove-key channels
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
pip config set global.index-url https://mirrors.ustc.edu.cn/pypi/web/simple
首先创建python3.8的虚拟环境,请在命令行中执行下列操作:
conda create -n yolo5 python==3.8.5
conda activate yolo5
pytorch安装(gpu版本和cpu版本的安装)
实际测试情况是YOLOv5在CPU和GPU的情况下均可使用,不过在CPU的条件下训练那个速度会令人发指,所以有条件的小伙伴一定要安装GPU版本的Pytorch,没有条件的小伙伴最好是租服务器来使用。
GPU版本安装的具体步骤可以参考这篇文章:2021年Windows下安装GPU版本的Tensorflow和Pytorch_dejahu的博客-CSDN博客
需要注意以下几点:
- 安装之前一定要先更新你的显卡驱动,去官网下载对应型号的驱动安装
- 30系显卡只能使用cuda11的版本
- 一定要创建虚拟环境,这样的话各个深度学习框架之间不发生冲突
我这里创建的是python3.8的环境,安装的Pytorch的版本是1.8.0,命令如下:
conda install pytorch==1.8.0 torchvision torchaudio cudatoolkit=10.2 # 注意这条命令指定Pytorch的版本和cuda的版本
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly # CPU的小伙伴直接执行这条命令即可
安装完毕之后,我们来测试一下GPU是否
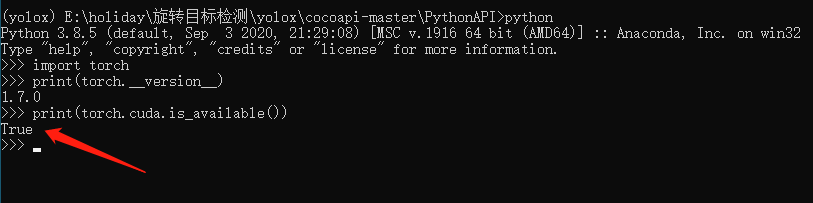
pycocotools的安装
后面我发现了windows下更简单的安装方法,大家可以使用下面这个指令来直接进行安装,不需要下载之后再来安装
pip install pycocotools-windows
其他包的安装
另外的话大家还需要安装程序其他所需的包,包括opencv,matplotlib这些包,不过这些包的安装比较简单,直接通过pip指令执行即可,我们cd到yolov5代码的目录下,直接执行下列指令即可完成包的安装。
pip install -r requirements.txt
pip install pyqt5
pip install labelme
数据处理
实现准备处理好的yolo格式的数据集,一般yolo格式的数据是一张图片对应一个txt格式的标注文件。
标注文件中记载了目标的类别 中心点坐标 和宽高信息,如下图所示:

记住这里的数据集位置,在后面的配置文件中我们将会使用到,比如我这里数据集的位置是:F:\sssssssssd\det\yolo\fire\fire_yolo_format
配置文件准备
-
数据配置文件的准备
配置文件是data目录下的
fire_data.yaml,只需要将这里的数据集位置修改为你本地的数据集位置即可。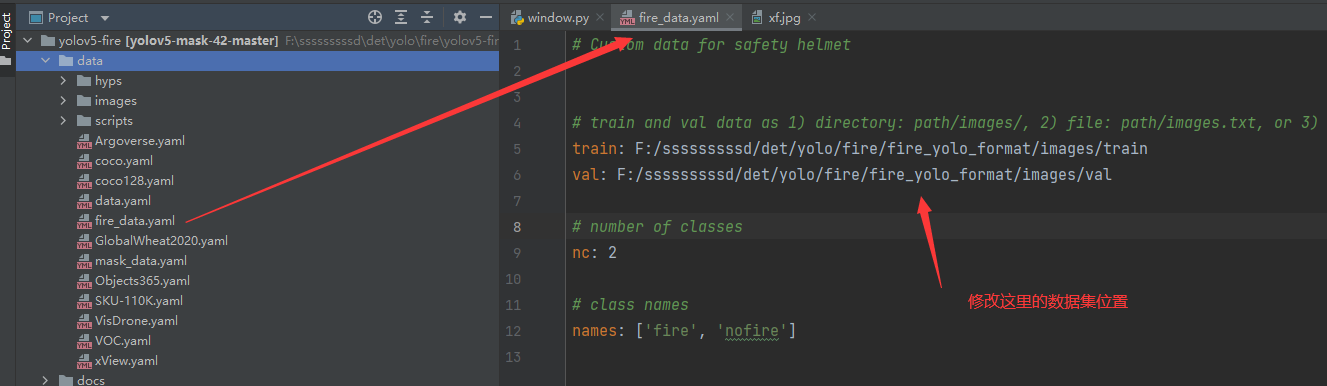
-
模型配置文件的准备
模型的配置文件主要有三个,分别是
mask_yolov5s.yaml、mask_yolov5m.yaml、mask_yolov5l.yaml,分别对应着yolo大中小三个模型,主要将配置文件中的nc修改为我们本次数据集对应的两个类别即可。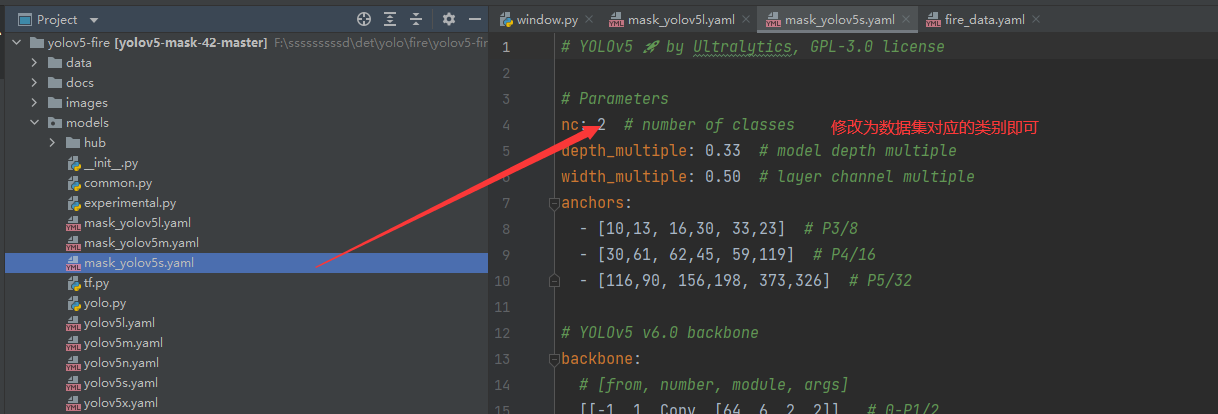
模型训练
模型训练的主文件是triain.py,下面的三条指令分别对应着小中大三个模型的训练,有GPU的同学可以将设备换为0,表示使用0号GPU卡,显存比较大的同学可以将batchsize调整为4或者16,训练起来更快。
python train.py --data fire_data.yaml --cfg mask_yolov5s.yaml --weights pretrained/yolov5s.pt --epoch 100 --batch-size 2 --device cpu
python train.py --data fire_data.yaml --cfg mask_yolov5l.yaml --weights pretrained/yolov5l.pt --epoch 100 --batch-size 2
python train.py --data fire_data.yaml --cfg mask_yolov5m.yaml --weights pretrained/yolov5m.pt --epoch 100 --batch-size 2
训练过程中会出现下面的进度条
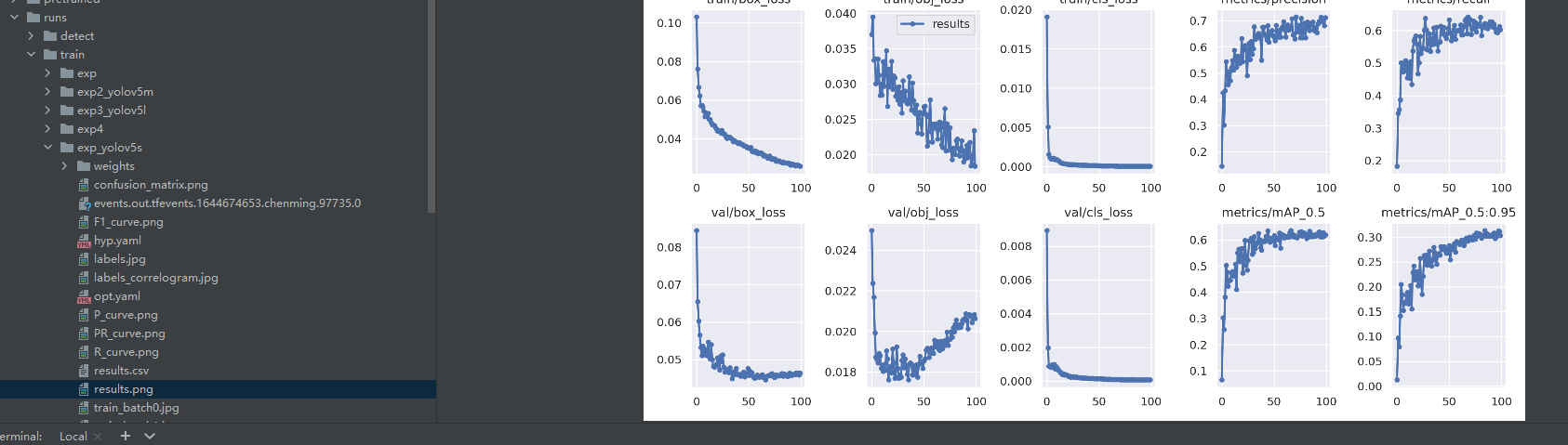
等待训练完成之后训练结果将会保存在runs/train目录下,里面有各种各样的示意图供大家使用。
模型使用
模型的使用全部集成在了detect.py目录下,你按照下面的指令指你要检测的内容即可
# 检测摄像头
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt --source 0 # webcam
# 检测图片文件
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt --source file.jpg # image
# 检测视频文件
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt --source file.mp4 # video
# 检测一个目录下的文件
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt path/ # directory
# 检测网络视频
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt 'https://youtu.be/NUsoVlDFqZg' # YouTube video
# 检测流媒体
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
比如以我们的口罩模型为例,如果我们执行python detect.py --weights runs/train/exp_yolov5s/weights/best.pt --source images/1_67.jpg的命令便可以得到这样的一张检测结果。

构建可视化界面
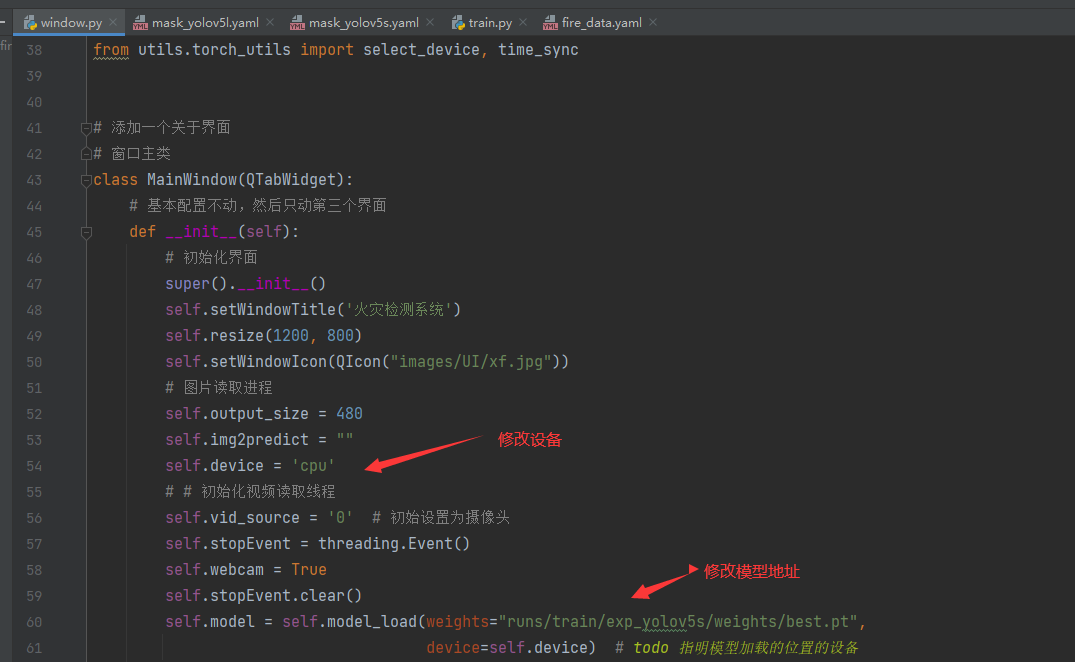
可视化界面的部分在window.py文件中,是通过pyqt5完成的界面设计,在启动界面前,你需要将模型替换成你训练好的模型,替换的位置在window.py的第60行,修改成你的模型地址即可,如果你有GPU的话,可以将device设置为0,表示使用第0行GPU,这样可以加快模型的识别速度嗷。
现在启动看看效果吧。
找到我
你可以通过这些方式来寻找我。
B站:肆十二-
CSDN:肆十二
知乎:肆十二
微博:肆十二-
现在关注以后就是老朋友喽!