一、配置邮件服务
1、安装sendmail服务
# yum -y install sendmail2、修改granfana.ini配置文件
# vim /etc/grafana/grafana.ini
#################################### SMTP / Emailing ##########################
[smtp]
;password =
;cert_file =
;key_file =
;skip_verify = false
;from_address = [email protected]
;from_name = Grafana
# EHLO identity in SMTP dialog (defaults to instance_name)
;ehlo_identity = dashboard.example.com
enabled = true
host = smtp.exmail.qq.com:465
user = 发件邮箱地址
password = GIliu.123
skip_verify = true
from_address = 发件邮箱地址
from_name = Grafana
3、在grafana上测试邮件发送
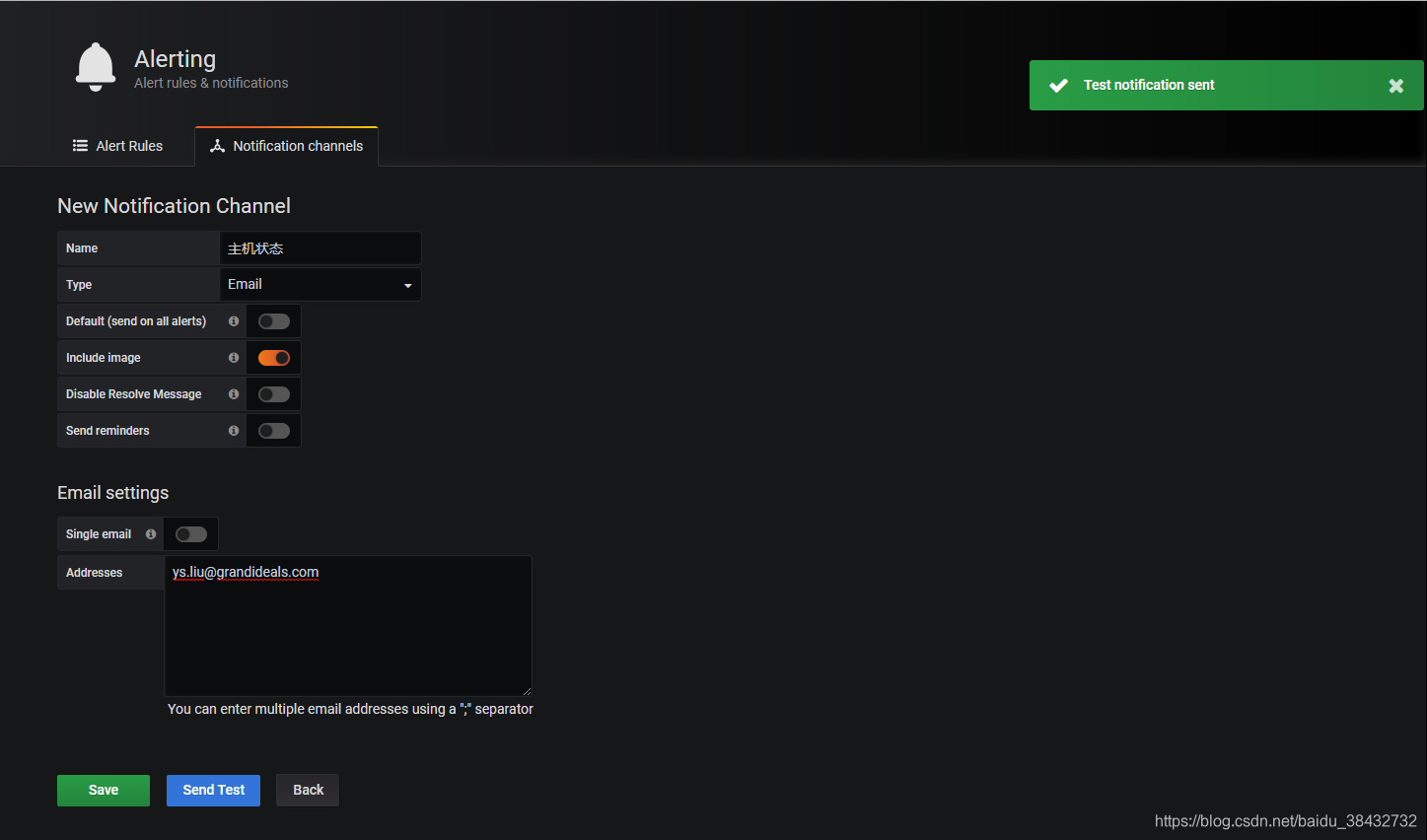
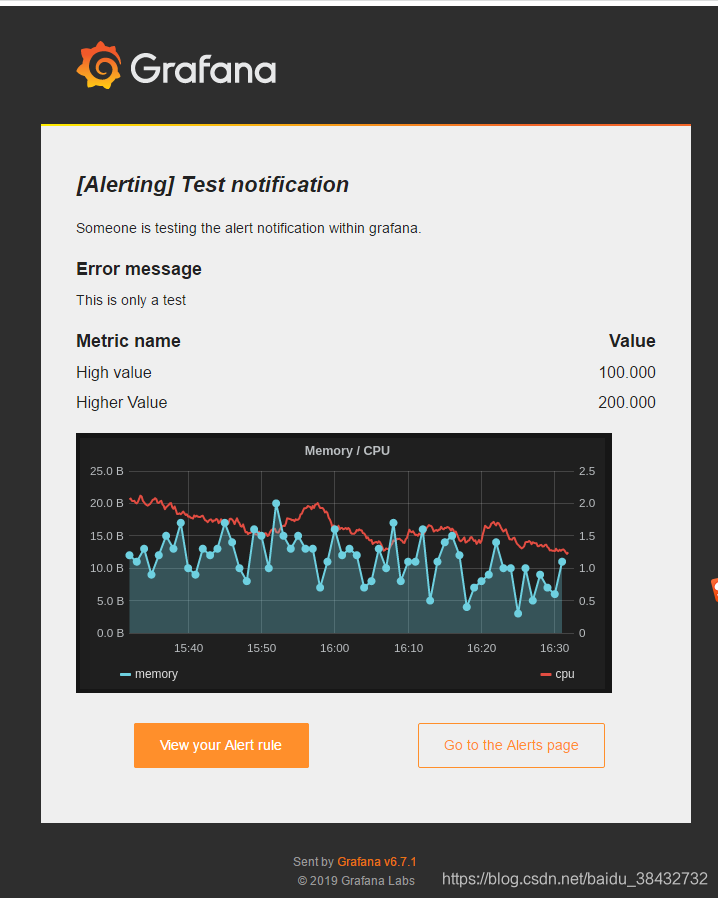
4、此时我们的邮箱就会收到如下邮件内容
二、alertmanage配置
# wget https://github.com/prometheus/alertmanager/releases/download/v0.21.0/alertmanager-0.21.0.linux-amd64.tar.gz
--2020-08-11 14:28:53-- https://github.com/prometheus/alertmanager/releases/download/v0.21.0/alertmanager-0.21.0.linux-amd64.tar.gz
Resolving github.com (github.com)... 13.250.177.223
Connecting to github.com (github.com)|13.250.177.223|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: https://github-production-release-asset-2e65be.s3.amazonaws.com/11452538/19587800-b097-11ea-99a2-bb9057dfed21?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20200811%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20200811T062854Z&X-Amz-Expires=300&X-Amz-Signature=e161ebb5efbd6a4784a8c1f603b3fe5a39e841d1fe4fc8681fb03dc59021d528&X-Amz-SignedHeaders=host&actor_id=0&repo_id=11452538&response-content-disposition=attachment%3B%20filename%3Dalertmanager-0.21.0.linux-amd64.tar.gz&response-content-type=application%2Foctet-stream [following]
--2020-08-11 14:28:54-- https://github-production-release-asset-2e65be.s3.amazonaws.com/11452538/19587800-b097-11ea-99a2-bb9057dfed21?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20200811%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20200811T062854Z&X-Amz-Expires=300&X-Amz-Signature=e161ebb5efbd6a4784a8c1f603b3fe5a39e841d1fe4fc8681fb03dc59021d528&X-Amz-SignedHeaders=host&actor_id=0&repo_id=11452538&response-content-disposition=attachment%3B%20filename%3Dalertmanager-0.21.0.linux-amd64.tar.gz&response-content-type=application%2Foctet-stream
Resolving github-production-release-asset-2e65be.s3.amazonaws.com (github-production-release-asset-2e65be.s3.amazonaws.com)... 52.216.162.227
Connecting to github-production-release-asset-2e65be.s3.amazonaws.com (github-production-release-asset-2e65be.s3.amazonaws.com)|52.216.162.227|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 25710888 (25M) [application/octet-stream]
Saving to: ‘alertmanager-0.21.0.linux-amd64.tar.gz’
100%[====================================================================================================================================================================================================================================>] 25,710,888 5.24MB/s in 5.1s
2020-08-11 14:29:00 (4.78 MB/s) - ‘alertmanager-0.21.0.linux-amd64.tar.gz’ saved [25710888/25710888]2、解压安装
# tar -xf alertmanager-0.21.0.linux-amd64.tar.gz -C ../
# cd ../
# mv alertmanager-0.21.0.linux-amd64/ alertmanager3、编辑alertmanager.yml文件
global:
resolve_timeout: 5m
smtp_smarthost: "smtp.exmail.qq.com:25"
smtp_from: "发件邮箱地址"
smtp_auth_username: "发件邮箱地址"
smtp_auth_password: "密码"
smtp_require_tls: false
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'mail'
receivers:
- name: 'mail'
mail_configs:
- to: '收件邮箱地址'
#inhibit_rules:
# - source_match:
# severity: 'critical'
# target_match:
# severity: 'warning'
# equal: ['alertname', 'dev', 'instance']
5、检查配置是否生效
# ./amtool check-config alertmanager.yml
Checking 'alertmanager.yml' SUCCESS
Found:
- global config
- route
- 0 inhibit rules
- 1 receivers
- 0 templates6、编写系统启动文件
# vim /usr/lib/systemd/system/alertmanager.service
[Unit]
Description=Prometheus
After=network.target
[Service]
# Type设置为notify时,服务会不断重启
Type=simple
User=root
ExecStart=/home/gridcloud/alermanager/alermanager --config.file=/home/gridcloud/alermanager/alermanager.yml
Restart=on-failure
[Install]
WantedBy=multi-user.target7、启动服务
# systemctl enable alertmanager
Created symlink from /etc/systemd/system/multi-user.target.wants/alertmanager.service to /usr/lib/systemd/system/alertmanager.service.
# systemctl start alertmanager
# systemctl status alertmanager
● alertmanager.service - Alertmanager
Loaded: loaded (/usr/lib/systemd/system/alertmanager.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2020-08-11 14:55:03 CST; 2s ago
Main PID: 17222 (alertmanager)
CGroup: /system.slice/alertmanager.service
└─17222 /home/gridcloud/alertmanager/alertmanager --config.file=/home/gridcloud/alertmanager/alertmanager.yml
Aug 11 14:55:03 ip-10-2-2-236.ap-southeast-1.compute.internal systemd[1]: Started Alertmanager.
Aug 11 14:55:03 ip-10-2-2-236.ap-southeast-1.compute.internal systemd[1]: Starting Alertmanager...
Aug 11 14:55:03 ip-10-2-2-236.ap-southeast-1.compute.internal alertmanager[17222]: level=info ts=2020-08-11T06:55:03.758Z caller=main.go:216 msg="Starting Alertmanager" version="(version=0.21.0, branch=HEAD, revision=4c6c03ebfe21009c546e4d1e9b92c371d67c021d)"
Aug 11 14:55:03 ip-10-2-2-236.ap-southeast-1.compute.internal alertmanager[17222]: level=info ts=2020-08-11T06:55:03.758Z caller=main.go:217 build_context="(go=go1.14.4, user=root@dee35927357f, date=20200617-08:54:02)"
Aug 11 14:55:03 ip-10-2-2-236.ap-southeast-1.compute.internal alertmanager[17222]: level=info ts=2020-08-11T06:55:03.759Z caller=cluster.go:161 component=cluster msg="setting advertise address explicitly" addr=10.2.2.236 port=9094
Aug 11 14:55:03 ip-10-2-2-236.ap-southeast-1.compute.internal alertmanager[17222]: level=info ts=2020-08-11T06:55:03.760Z caller=cluster.go:623 component=cluster msg="Waiting for gossip to settle..." interval=2s
Aug 11 14:55:03 ip-10-2-2-236.ap-southeast-1.compute.internal alertmanager[17222]: level=info ts=2020-08-11T06:55:03.780Z caller=coordinator.go:119 component=configuration msg="Loading configuration file" file=/home/gridcloud/alertmanager/alertmanager.yml
Aug 11 14:55:03 ip-10-2-2-236.ap-southeast-1.compute.internal alertmanager[17222]: level=info ts=2020-08-11T06:55:03.780Z caller=coordinator.go:131 component=configuration msg="Completed loading of configuration file" file=/home/gridcloud/alertmanager/alertmanager.yml
Aug 11 14:55:03 ip-10-2-2-236.ap-southeast-1.compute.internal alertmanager[17222]: level=info ts=2020-08-11T06:55:03.783Z caller=main.go:485 msg=Listening address=:9093
Aug 11 14:55:05 ip-10-2-2-236.ap-southeast-1.compute.internal alertmanager[17222]: level=info ts=2020-08-11T06:55:05.760Z caller=cluster.go:648 component=cluster msg="gossip not settled" polls=0 before=0 now=1 elapsed=2.000074543s8、修改prometheus的配置文件
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 0.0.0.0:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "rules/*.yml"
9、重启prometheus服务
# systemctl restart prometheus10、配置告警规则,以下是我是用的rule,第二个是其他人用的规则,我们可根据具体情况选择
# cat rules/host.yml
groups:
- name: host_alert
rules:
### 硬盘 ###
# 默认系统盘告警策略
- alert: 主机系统盘80%
expr: floor(100-((node_filesystem_avail{device!="rootfs", mountpoint="/"}*100)/(node_filesystem_size{device!="rootfs", mountpoint="/"}*0.95))) >= 80
for: 3m
labels:
severity: warning
annotations:
description: "[{
{ $labels.desc }}],告警值为:[{
{ $value }}%],告警初始时长为3分钟."
# 默认120G内数据盘告警策略
- alert: 主机数据盘90%
expr: (floor(100-((node_filesystem_avail{device!="rootfs", mountpoint="/data"}*100)/(node_filesystem_size{device!="rootfs", mountpoint="/data"}*0.95))) >= 90) and (node_filesystem_size{device!="rootfs", mountpoint="/data"}/1024/1024/1024 <= 120)
for: 3m
labels:
severity: warning
annotations:
description: "[{
{ $labels.desc }}],告警值为:[{
{ $value }}%],告警初始时长为3分钟."
# 默认120G以上数据盘告警策略
- alert: 主机数据盘不足20G
expr: (floor(node_filesystem_avail{device!="rootfs", mountpoint="/data"}/1024/1024/1024) <= 20) and (node_filesystem_size{device!="rootfs", mountpoint="/data"}/1024/1024/1024 > 120)
for: 3m
labels:
severity: warning
annotations:
description: "[{
{ $labels.desc }}],告警值为:[{
{ $value }}G],告警初始时长为3分钟."
### CPU ###
# 默认CPU使用率告警策略
- alert: 主机CPU90%
expr: floor(100 - ( avg ( irate(node_cpu{mode='idle', hostname!~'consumer_service.*|backup_hk.*|bigdata.*master.*|3rdPart|htc_management|product_category_backend|sa_cluster_s.*'}[5m]) ) by (job, instance, hostname, desc) * 100 )) >= 90
for: 3m
labels:
severity: warning
annotations:
description: "[{
{ $labels.desc }}],告警值为:[{
{ $value }}%],告警初始时长为3分钟."
# 持续时间较长的CPU使用率告警策略
- alert: 主机CPU90%
expr: floor(100 - ( avg ( irate(node_cpu{mode='idle', hostname=~'consumer_service.*|product_backend|sa_cluster_s.*'}[5m]) ) by (job, instance, hostname, desc) * 100 )) >= 90
for: 12m
labels:
severity: warning
annotations:
description: "[{
{ $labels.desc }}],告警值为:[{
{ $value }}%],告警初始时长为12分钟."
# 持续时间较长的CPU使用率告警策略
- alert: 主机CPU90%
expr: floor(100 - ( avg ( irate(node_cpu{mode='idle', hostname=~'bigdata.*master.*|3rdPart|backup_hk.*'}[5m]) ) by (job, instance, hostname, desc) * 100 )) >= 90
for: 48m
labels:
severity: warning
annotations:
description: "[{
{ $labels.desc }}],告警值为:[{
{ $value }}%],告警初始时长为48分钟."
### 内存 ###
# 默认内存使用率告警策略
- alert: 主机内存95%
expr: floor((node_memory_MemTotal - node_memory_MemFree - node_memory_Cached - node_memory_Buffers) / node_memory_MemTotal * 100) >= 95
for: 3m
labels:
severity: warning
annotations:
description: "[{
{ $labels.desc }}],告警值为:[{
{ $value }}%],告警初始时长为3分钟."
### 负载 ###
# 默认负载过高告警策略
- alert: 主机负载过高
expr: floor(node_load1{hostname!~"sa_cluster_s.*|bigdata.*master.*"}) >= 20
for: 3m
labels:
severity: warning
annotations:
description: "[{
{ $labels.desc }}],告警值为:[{
{ $value }}],告警初始时长为3分钟."
# 持续时间较长的负载过高告警策略
- alert: 主机负载过高
expr: floor(node_load1{hostname=~"sa_cluster_s.*|bigdata.*master.*"}) >= 20
for: 12m
labels:
severity: warning
annotations:
description: "[{
{ $labels.desc }}],告警值为:[{
{ $value }}],告警初始时长为12分钟."
groups:
- name: test-rules
rules:
- alert: InstanceDown
expr: up == 0
for: 2m
labels:
status: warning
annotations:
summary: "{
{$labels.instance}}: has been down"
description: "{
{$labels.instance}}: job {
{$labels.job}} has been down"
- name: base-monitor-rule
rules:
- alert: NodeCpuUsage
expr: (100 - (avg by (instance) (rate(node_cpu{job=~".*",mode="idle"}[2m])) * 100)) > 99
for: 15m
labels:
service_name: test
level: warning
annotations:
description: "{
{$labels.instance}}: CPU usage is above 99% (current value is: {
{ $value }}"
- alert: NodeMemUsage
expr: avg by (instance) ((1- (node_memory_MemFree{} + node_memory_Buffers{} + node_memory_Cached{})/node_memory_MemTotal{}) * 100) > 90
for: 15m
labels:
service_name: test
level: warning
annotations:
description: "{
{$labels.instance}}: MEM usage is above 90% (current value is: {
{ $value }}"
- alert: NodeDiskUsage
expr: (1 - node_filesystem_free{fstype!="rootfs",mountpoint!="",mountpoint!~"/(run|var|sys|dev).*"} / node_filesystem_size) * 100 > 80
for: 2m
labels:
service_name: test
level: warning
annotations:
description: "{
{$labels.instance}}: Disk usage is above 80% (current value is: {
{ $value }}"
- alert: NodeFDUsage
expr: avg by (instance) (node_filefd_allocated{} / node_filefd_maximum{}) * 100 > 80
for: 2m
labels:
service_name: test
level: warning
annotations:
description: "{
{$labels.instance}}: File Descriptor usage is above 80% (current value is: {
{ $value }}"
- alert: NodeLoad15
expr: avg by (instance) (node_load15{}) > 100
for: 2m
labels:
service_name: test
level: warning
annotations:
description: "{
{$labels.instance}}: Load15 is above 100 (current value is: {
{ $value }}"
- alert: NodeAgentStatus
expr: avg by (instance) (up{}) == 0
for: 2m
labels:
service_name: test
level: warning
annotations:
description: "{
{$labels.instance}}: Node Agent is down (current value is: {
{ $value }}"
- alert: NodeProcsBlocked
expr: avg by (instance) (node_procs_blocked{}) > 100
for: 2m
labels:
service_name: test
level: warning
annotations:
description: "{
{$labels.instance}}: Node Blocked Procs detected!(current value is: {
{ $value }}"
- alert: NodeTransmitRate
expr: avg by (instance) (floor(irate(node_network_transmit_bytes{device="eth0"}[2m]) / 1024 / 1024)) > 100
for: 2m
labels:
service_name: test
level: warning
annotations:
description: "{
{$labels.instance}}: Node Transmit Rate is above 100MB/s (current value is: {
{ $value }}"
- alert: NodeReceiveRate
expr: avg by (instance) (floor(irate(node_network_receive_bytes{device="eth0"}[2m]) / 1024 / 1024)) > 100
for: 2m
labels:
service_name: test
level: warning
annotations:
description: "{
{$labels.instance}}: Node Receive Rate is above 100MB/s (current value is: {
{ $value }}"
- alert: NodeDiskReadRate
expr: avg by (instance) (floor(irate(node_disk_bytes_read{}[2m]) / 1024 / 1024)) > 50
for: 2m
labels:
service_name: test
level: warning
annotations:
description: "{
{$labels.instance}}: Node Disk Read Rate is above 50MB/s (current value is: {
{ $value }}"
- alert: NodeDiskWriteRate
expr: avg by (instance) (floor(irate(node_disk_bytes_written{}[2m]) / 1024 / 1024)) > 50
for: 2m
labels:
service_name: test
level: warning
annotations:
description: "{
{$labels.instance}}: Node Disk Write Rate is above 50MB/s (current value is: {
{ $value }}"11、此时我们可以登录http://prometheus地址:9090/alerts查看rules


12、告警测试,查看我们的状态

13、此时我们就看到我们的邮箱收到了邮件
