-
一、Prometheus
-
二、exporter
-
2.1 node_exporter
-
2.2 mysqld_exporter
-
-
三、grafana
-
3.1 部署
-
3.2 配置数据源
-
3.3 配置监控模板
-
-
四、alertmanager
-
4.1 配置alertmanager服务
-
4.2 配置dingding告警
-
4.3 配置 rule
-
-
五、总结
一、Prometheus
# 1.下载
wget https://github.com/prometheus/prometheus/releases/download/v2.35.0/prometheus-2.35.0.linux-amd64.tar.gz
# 2.解压
tar xvpf prometheus-2.35.0.linux-amd64.tar.gz -C /usr/local
# 3.建软链
ln -s /usr/local/prometheus-2.35.0.linux-amd64 /usr/local/prometheus
# 4.建用户和目录并开权限
groupadd prometheus
useradd prometheus -g prometheus -s /sbin/nologin
mkdir -p /data/prometheus
chown prometheus.prometheus /data/prometheus -R
chown prometheus.prometheus /usr/local/prometheus/ -R
# 5.配置启动
echo '
[Unit]
Description=prometheus
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/prometheus/prometheus \
--config.file=/usr/local/prometheus/prometheus.yml \
--storage.tsdb.path=/data/prometheus \
--web.console.templates=/usr/local/prometheus/consoles \
--web.console.libraries=/usr/local/prometheus/console_libraries
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
RestartSec=60s
[Install]
WantedBy=multi-user.target
' > /usr/lib/systemd/system/prometheus.service
# 6.添加prometheus.yml配置
echo '
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
scheme: http
timeout: 10s
rule_files:
- /usr/local/prometheus/rules.d/*.rules
scrape_configs:
- job_name: prometheus
honor_timestamps: true
scrape_interval: 5s
scrape_timeout: 5s
metrics_path: /metrics
scheme: http
static_configs:
- targets:
- localhost:9090
- job_name: node-exporter
honor_timestamps: true
scrape_interval: 5s
scrape_timeout: 5s
metrics_path: /metrics
scheme: http
static_configs:
- targets:
- localhost:9100
- job_name: mysqld-exporter
honor_timestamps: true
scrape_interval: 5s
scrape_timeout: 5s
metrics_path: /metrics
scheme: http
static_configs:
- targets:
- localhost:9104
' > /usr/local/prometheus/prometheus.yml
# 7.启动
systemctl enable prometheus.service
systemctl start prometheus.service
# 8.确认开启
[root@mgr2 prometheus]# netstat -nltp|grep prometheus
tcp6 0 0 :::9090 :::* LISTEN 11028/prometheus
9.浏览器访问出现prometheus的管理后台
http://192.168.6.216:9090
以上单机版的prometheus服务端就部署完成了,接下来我们部署下node_export 和 mysqld_export 来采集系统和 MySQL 的监控数据。
二、exporter
exporter 是客户端采集模块,除了系统模块 node_exporter 之外,每个应用都有自己相应的模块,比如 MySQL 的 mysqld_exporter
建立一个 exporter 统一管理目录
mkdir -p /usr/local/prometheus_exporter
chown prometheus.prometheus /usr/local/prometheus_exporter -R2.1 node_exporter
用来监控系统指标的 exporter 包括内存、CPU、磁盘空间、磁盘IO、网络等一系列指标数据。
# 1.下载解压
wget https://github.com/prometheus/node_exporter/releases/download/v0.18.0/node_exporter-0.18.0.linux-amd64.tar.gz
tar xvpf node_exporter-0.18.0.linux-amd64.tar.gz
cd node_exporter-0.18.0.linux-amd64/
mv node_exporter /usr/local/prometheus_exporter/
chown prometheus:prometheus /usr/local/prometheus_exporter/ -R
# 2.配置启动服务
echo '
[Unit]
Description=node_exporter
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/prometheus_exporter/node_exporter
Restart=on-failure
RestartSec=60s
[Install]
WantedBy=multi-user.target
' > /usr/lib/systemd/system/node_exporter.service
# 5.启动
systemctl enable node_exporter.service
systemctl start node_exporter.service
# 6.确认开启
[root@mgr2 node_exporter]# netstat -nltp|grep node_exporter
tcp6 0 0 :::9100 :::* LISTEN 15654/node_exporter
# 7.确认采集到数据
[root@mgr2 prometheus]# curl http://192.168.6.216:9100/metrics
# TYPE node_cpu_seconds_total counter
node_cpu_seconds_total{cpu="0",mode="idle"} 273849.94
node_cpu_seconds_total{cpu="0",mode="iowait"} 607.22
node_cpu_seconds_total{cpu="0",mode="irq"} 0
node_cpu_seconds_total{cpu="0",mode="nice"} 84.82
node_cpu_seconds_total{cpu="0",mode="softirq"} 3.35
node_cpu_seconds_total{cpu="0",mode="steal"} 0
node_cpu_seconds_total{cpu="0",mode="system"} 5026.1
node_cpu_seconds_total{cpu="0",mode="user"} 3723.54
# HELP node_disk_io_now The number of I/Os currently in progress.
# TYPE node_disk_io_now gauge
node_disk_io_now{device="dm-0"} 0
node_disk_io_now{device="dm-1"} 02.2 mysqld_exporter
监控 MySQL 的 exporter ,包括连接数、同步状态,InnoDB状态、响应状态等
# 下载解压
wget https://github.com/prometheus/mysqld_exporter/releases/download/v0.11.0/mysqld_exporter-0.11.0.linux-amd64.tar.gz
tar xvpf mysqld_exporter-0.11.0.linux-amd64.tar.gz
cd mysqld_exporter-0.11.0.linux-amd64
mv mysqld_exporter /usr/local/prometheus_exporter/
chown prometheus:prometheus /usr/local/prometheus_exporter/ -R
# 3.创建监控用的账户权限,数据库是8.0版本
CREATE USER 'mysqlmonitor'@'127.0.0.1' IDENTIFIED BY 'mc.2022' WITH MAX_USER_CONNECTIONS 3;
GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'mysqlmonitor'@'127.0.0.1';
ALTER USER 'mysqlmonitor'@'127.0.0.1' IDENTIFIED WITH mysql_native_password BY 'mc.2022';
flush privileges;
# 4.配置启动服务
vi /usr/lib/systemd/system/mysqld_exporter.service
[Unit]
Description=mysqld_exporter
After=network.target
[Service]
Type=simple
User=prometheus
Environment='DATA_SOURCE_NAME=mysqlmonitor:mc.2022@tcp(127.0.0.1:3306)'
ExecStart=/usr/local/prometheus_exporter/mysqld_exporter \
--config.my-cnf='/data/GreatSQL/my.cnf' \
--collect.engine_innodb_status \
--collect.slave_status \
--web.listen-address=:9104 \
--web.telemetry-path=/metrics
Restart=on-failure
RestartSec=60s
[Install]
WantedBy=multi-user.target
# 5.启动
systemctl enable mysqld_exporter.service
systemctl start mysqld_exporter.service
# 6.确认开启
[root@mgr2 prometheus]# netstat -nltp|grep mysqld_export
tcp6 0 0 :::9104 :::* LISTEN 14639/mysqld_export
# 7.确认采集到数据
[root@mgr2 prometheus]# curl http://192.168.6.216:9104/metrics
# TYPE mysql_up gauge
mysql_up 1
......三、grafana
通过 grafana 我们可以将采集到的数据通过可视化的方式展现出来,对采集的数据进行展示和分类等。
grafana 的数据源既可以是 prometheus 也可以是zabbix、ES等、这是一个提供多种数据接口的数据展示软件。
3.1 部署
# 1.通过rpm安装
wget https://dl.grafana.com/enterprise/release/grafana-enterprise-8.5.3-1.x86_64.rpm
yum install grafana-enterprise-8.5.3-1.x86_64.rpm
# 2.备份先原来的配置
mv /etc/grafana/grafana.ini /etc/grafana/grafana.ini.`date +"%Y-%m-%d"`.bak
# 3.创建目录
mkdir -p /data/grafana
mkdir -p /data/logs/grafana
mkdir -p /usr/local/grafana/plugins
chown grafana.grafana /data/grafana
chown grafana.grafana /data/logs/grafana
chown grafana.grafana /usr/local/grafana/plugins
# 4.拷贝模板文件进行替换
echo '
app_mode = production
[paths]
data = /data/grafana
temp_data_lifetime = 24h
logs = /data/logs/grafana
plugins = /usr/local/grafana/plugins
[server]
protocol = http
http_port = 3000
domain = gkht
root_url = http://192.168.6.216:3000
enable_gzip = true
[database]
log_queries =
[remote_cache]
[session]
provider = file
[dataproxy]
[analytics]
reporting_enabled = false
check_for_updates = false
[security]
admin_user = admin
admin_password = admin
secret_key = SW2YcwTIb9zpOOhoPsMm
[snapshots]
[dashboards]
versions_to_keep = 10
[users]
default_theme = dark
[auth]
[auth.anonymous]
enabled = true
org_role = Viewer
[auth.github]
[auth.google]
[auth.generic_oauth]
[auth.grafana_com]
[auth.proxy]
[auth.basic]
[auth.ldap]
[smtp]
[emails]
[log]
mode = console file
level = info
[log.console]
[log.file]
log_rotate = true
daily_rotate = true
max_days = 30
[log.syslog]
[alerting]
enabled = true
execute_alerts = true
[explore]
[metrics]
enabled = true
interval_seconds = 10
[metrics.graphite]
[tracing.jaeger]
[grafana_com]
url = https://grafana.com
[external_image_storage]
[external_image_storage.s3]
[external_image_storage.webdav]
[external_image_storage.gcs]
[external_image_storage.azure_blob]
[external_image_storage.local]
[rendering]
[enterprise]
[panels]
' > /etc/grafana/grafana.ini
chown grafana.grafana /etc/grafana/grafana.ini
# 5.开启
systemctl enable grafana-server.service
systemctl start grafana-server.service
# 6.查看开启状态
[root@mgr2 opt]# netstat -nltp|grep grafana
tcp6 0 0 :::3000 :::* LISTEN 23647/grafana-serve
7.浏览器访问
http://192.168.6.216:3000/login

账户密码都是 admin 登陆后先改下管理员密码,这里演示就跳过,下面是主界面
3.2 配置数据源
1.设置,Data sources

2.Add data source

3.输入Prometheus
4.添加数据源信息
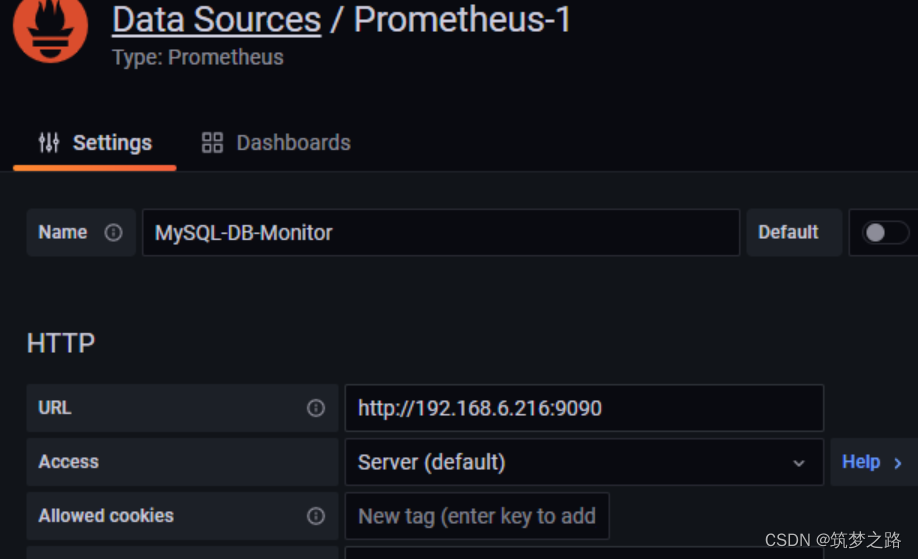
5.测试连接
6.返回数据源
3.3 配置监控模板
模板库:https://grafana.com/dashboards
node_exporter面板
选择数据源 Prometheus ,输入 exporter,选择活跃度高的。


1.选择导入 Import,.输入id值,然后load
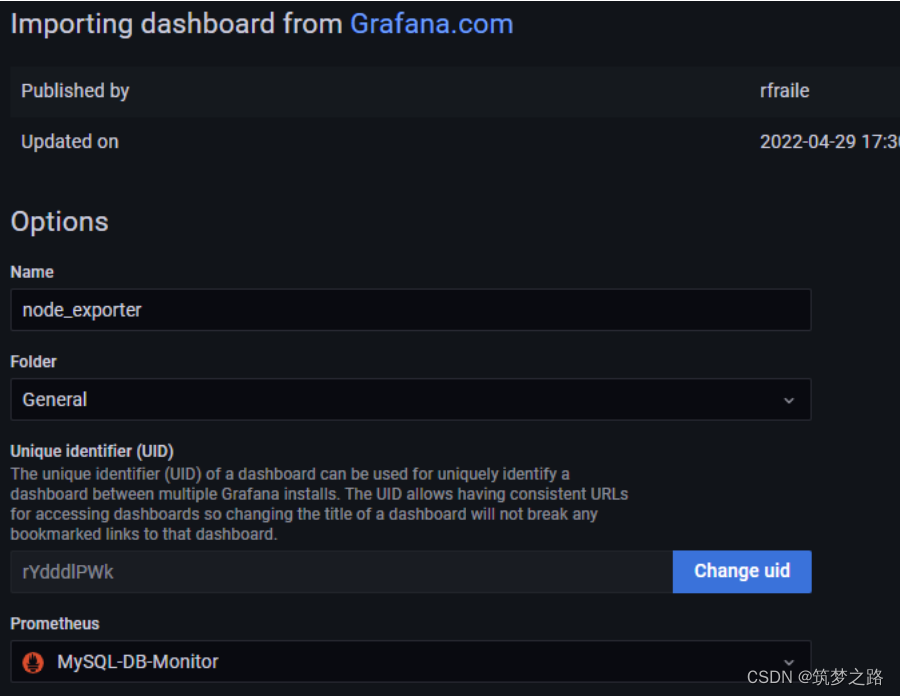
2.输入名称,选择数据源,点击导入
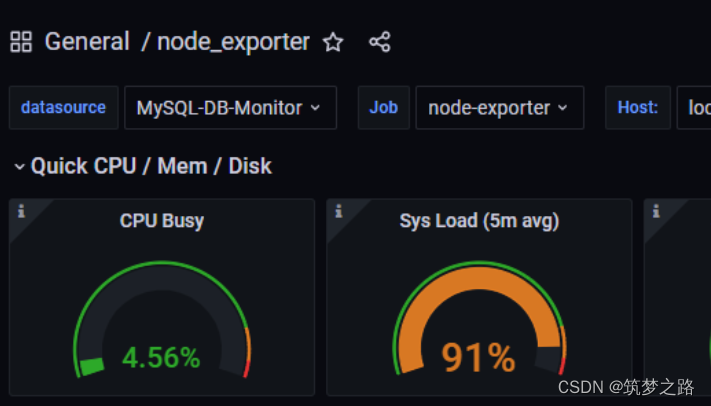
mysqld_exporter面板
还是像之前步骤一样,搜索 mysql 关键字,找到面板,拷贝id 7362,然后导入报存

四、alertmanager
alertmanager是普米的告警模块,可配置各种告警规则并将告警内容发送到微信、钉钉、邮箱等
4.1 配置alertmanager服务
# 1.下载
wget https://github.com/prometheus/alertmanager/releases/download/v0.17.0/alertmanager-0.17.0.linux-amd64.tar.gz
# 2.解压并拷贝文件
tar xvpf alertmanager-0.17.0.linux-amd64.tar.gz -C /usr/local/ln -s /usr/local/alertmanager-0.17.0.linux-amd64 /usr/local/alertmanager
# 3.创建数据目录并赋权
mkdir -p /data/alertmanager
chown prometheus:prometheus /data/alertmanager -R
chown prometheus:prometheus /usr/local/alertmanager -R
# 4.配置启动脚本
echo '
[Unit]
Description=alertmanager
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/alertmanager/alertmanager \
--config.file=/usr/local/alertmanager/alertmanager.yml \
--storage.path=/data/alertmanager \
--data.retention=120h
Restart=on-failure
RestartSec=60s
[Install]
WantedBy=multi-user.target
' > /usr/lib/systemd/system/alertmanager.service
# 5.启动
systemctl enable alertmanager.service
systemctl start alertmanager.service
# 6.查看开启情况
[root@mgr2 alertmanager]# netstat -nltp|grep alertmanager
tcp6 0 0 :::9093 :::* LISTEN 30369/alertmanager
tcp6 0 0 :::9094 :::* LISTEN 30369/alertmanager4.2 配置dingding告警
4.2.1 创建dingding告警机器人
1.钉钉创建一个群组,取名 告警
2.点击右上角的 设置
3.点击 智能群助手
4.添加机器人
5.点击设置

6.选择自定义

7.点击 添加
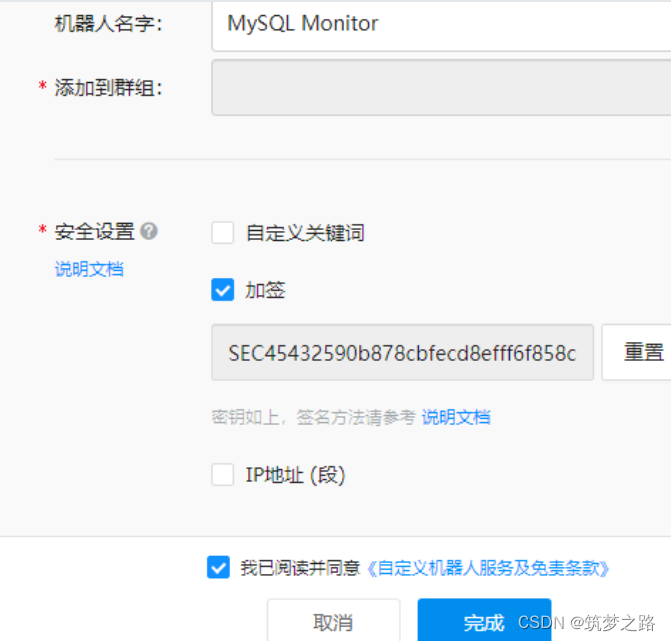
8.设置下 机器人 和 安全设置 ,点击完成
9.最后确认信息,点击完成
10.设置后,群消息会弹出欢迎消息
4.2.2 安装钉钉告警插件
# 1.下载
wget https://github.com/timonwong/prometheus-webhook-dingtalk/releases/download/v2.0.0/prometheus-webhook-dingtalk-2.0.0.linux-amd64.tar.gz
# 2.解压
tar xvpf prometheus-webhook-dingtalk-2.0.0.linux-amd64.tar.gz
mv prometheus-webhook-dingtalk-2.0.0.linux-amd64 /usr/local/
ln -s /usr/local/prometheus-webhook-dingtalk-2.0.0.linux-amd64 /usr/local/prometheus-webhook-dingtalk
# 3.配置config.yml
# 拷贝个模板文件
# url 和 secret 是我们创建告警机器人的时候出现的 webook 和安全设置的"加签"
cp config.example.yml config.yml
[root@mgr2 prometheus-webhook-dingtalk]# cat config.yml
templates:
- contrib/templates/legacy/template.tmpl
targets:
webhook1:
url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx
secret: SEC000000000000000000000
# 4.配置启动服务
echo '
[Unit]
Description=prometheus-webhook-dingtalk
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/prometheus-webhook-dingtalk/prometheus-webhook-dingtalk \
--config.file='/usr/local/prometheus-webhook-dingtalk/config.yml'
Restart=on-failure
RestartSec=60s
[Install]
WantedBy=multi-user.target
' > /usr/lib/systemd/system/prometheus-webhook-dingtalk.service
# 5.赋权
chown prometheus.prometheus /usr/local/prometheus-webhook-dingtalk -R
# 6.启动
systemctl enable prometheus-webhook-dingtalk.service
systemctl start prometheus-webhook-dingtalk.service
# 7.确认开启了
[root@mgr2 prometheus-webhook-dingtalk]# ps -aux|grep prometheus-webhook-dingtalk
prometh+ 23162 0.0 0.3 716116 5768 ? Ssl 15:23 0:00 /usr/local/prometheus-webhook-dingtalk/prometheus-webhook-dingtalk --config.file=/usr/local/prometheus-webhook-dingtalk/config.yml :::* LISTEN 15654/node_exporter4.3 配置 rule
prometheus.yml 有个rule_files 模块会加载我们的自定义配置信息
# 1.创建目录
mkdir -p /usr/local/prometheus/rules.d/
# 2.配置告警规则信息
[root@mgr2 rules.d]# cat test.rules
groups:
- name: OsStatsAlert
rules:
- alert: Out of Disk Space
expr: ( 1 - (node_filesystem_avail_bytes{fstype=~"ext[34]|xfs"} / node_filesystem_size_bytes{fstype=~"ext[234]|btrfs|xfs|zfs"}) ) * 100 > 15
for: 1m
labels:
team: node
annotations:
summary: "{
{$labels.instance}}: 文件系统空间使用率过高"
description: "{
{$labels.instance}}: 文件系统空间使用率超过 15% (当前使用率: {
{ $value }})"
- name: MySQLStatsAlert
rules:
- alert: MySQL is down
expr: mysql_up == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Instance {
{ $labels.instance }} MySQL is down"
description: "MySQL database is down."
# 3.重启
systemctl restart prometheus
systemctl restart alertmanager4.关闭MySQL进程,观察告警信息
systemctl stop [email protected]5.提示告警信息
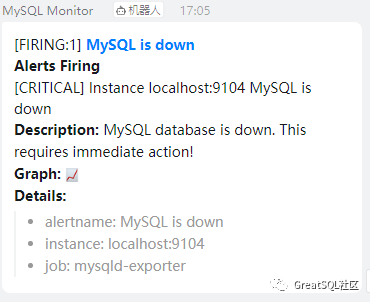
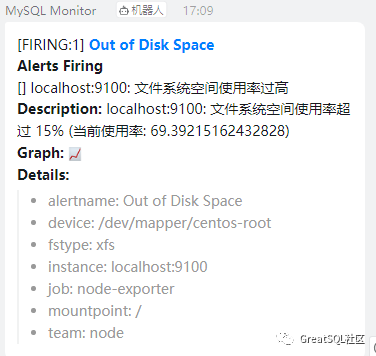
6.异常恢复后也会进行告警通知
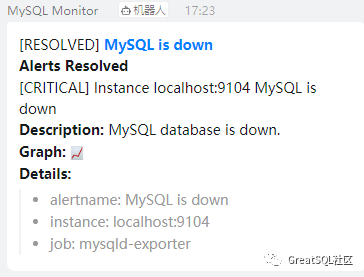
五、总结
以上基于Prometheus+Grafana+钉钉简单部署了一个告警系统,可以结合实际情况自行进行扩展,在生产上Prometheus一般采用集群方式,防止单点故障,同时也可与consul结合做服务自动发现,减少手动配置环节。