论文题目:CoRRN: Cooperative Reflection Removal Network
发表:IEEE TRANSACA TIONS ON P A TTERN ANAL YSIS AND MACHINE INTELLIGENCE
作者:Renjie Wan等
1、目的
去除反射和恢复背景
2、背景
许多基于非学习的方法采用两阶段:
(1)定位反射区域(例如,通过对背景和反射边缘进行分类)
(2)使用Levin等人提出的方法基于边缘信息恢复背景层。
但是,定位反射区域本身是一项非常具有挑战性的任务,因此现有方法主要依赖于一些启发式观察,或者必须涉及用户交互,这在许多情况下并不适用。
本文提出了使用一个共享编码器网络的协作反射去除网络(CoRRN),全称Cooperative Reflection Removal
Network。该模型由三个子网络组成:用于提取背景信息的上下文编码网络(CencN)、用于估计背景梯度的梯度解码器网络(GdecN)和用于估计背景和反射的图像解码器网络(IdecN)。 IdecN和GdecN共享CencN提取的特征信息。 这种特征共享策略被认为可以提高学习效率和预测准确性。 另一方面,在IdecN和GdecN之间添加了特征增强层,以部分抑制GdecN中存在于梯度特征中的反射伪像。 最后,除了GdecN的梯度约束外,还基于梯度水平统计量为IdecN引入了新的统计损失,以更好地消除局部强反射。
3、方法
提出了一种具有特征共享策略的网络,通过集成图像上下文信息和多尺度梯度信息,在一个协作和统一的框架中解决该问题。为了消除某些局部区域中存在的强烈反射,我们通过考虑背景与反射之间的梯度级别统计来提出统计损失。
CoRRN整体网络结构:

提出了一个具有多尺度引导学习策略的统一反射移除网络。它由三个协作子网组成,提高了学习效率和预测精度。
(1)GdecN采用CencN较浅层的信息作为输入并估算∇B。它可以从多个尺度提取图像梯度信息,并指导整个图像重建过程。
(2)IdecN将来自CencN较深层的特征信息作为输入,并通过使用多上下文信息提取背景特征表示估计B和R。
(3)CencN较浅的层中保留反射相关的细节,在较深的卷积层中学习的滤波器倾向于捕获与背景相关的信息。(CencN前面:保留反射信息 后面:与背景有关)
(4)Feature enhancement layer:本文在IdecN和GdecN之间添加了内核大小为7×7的特征增强层,以将具有反射的特征映射到具有相对较少反射的特征空间。
(5)Multi-scale guided inference:在梯度域中可以更好地区分具有较大梯度值的背景像素和具有较小梯度值的反射像素。因此将这种梯度先验嵌入到图像解码器网络中,以提高最终解决方案的稳定性。通过将GdecN中每个转置的卷积层的输出与IdecN中转置的卷积层的输出串联在一起,将传统的单尺度梯度嵌入方案扩展为多尺度方案。(背景:梯度大 反射:梯度小)
(6)Feature extraction layers A/B:直接采用CencN的最后一层作为IdecN的输入,以避免 来自反射的干扰。IdecN包含两个用于提取multi-上下文和尺度不变特征的特征提取层。
3.1数据准备
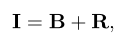 I:混合图像,B:背景层,R:反射层
I:混合图像,B:背景层,R:反射层
通过设置B =αBo和R =βRo来采用线性加法加权方案,其中Bo代表自然图像数据集中的原始背景图像,Ro代表来自“ RID”的反射图像,α和β为 用于平衡Bo和Ro组合的混合系数。 在训练阶段,我们将合成混合图像I作为整个网络的输入,将加权背景图像B和加权反射图像R用作相应的地面实况。
为了确保足够的训练数据,分别在[0.8,1]和[0.1,0.5]中随机采样α和β,然后我们通过两种不同的操作进一步增强生成的图像:(1)旋转:将图像随机旋转90◦,180◦或270◦
(2)翻转:水平翻转图像的概率为0.5。总的来说,训练数据集包括14754张图像。
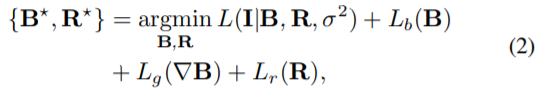
(1) 这里argmin 是使后面的式子达到最小值时变量的取值,同理argmax 就是使后面这个式子达到最大值时变量的取值。本文的意思就是L达到最小时B,R的取值
(2) 最大后验估计是根据经验数据获得对难以观察的量的点估计。与最大似然估计类似,但是不同就在于,最大后验估计融入了要估计量的先验分布。
Lb,Lg和Lr分别是对B,∇B和R实施的先验。 式(2)中的多任务学习框架由于能够探索B、R、∇B的估计量之间的内在相关性,已经被许多以前的方法所采用。我们将这种多任务学习框架嵌入基于U-Net结构的合作模型中。与主要采用梯度先验或内容先验的先前方法不同,我们的模型从大规模训练数据集中学习B,R和∇B的先验,然后将它们隐式地嵌入到估计过程中。 我们的模型将混合图像作为输入,并包含三个协作子网。 这三个合作网络在∇B的指导下估算B和R,可以通过使用多个损失函数根据其对应的地面真实进行训练。 给定混合图像I,整个预测过程: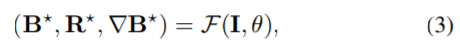
其中F是θ要训练的网络,其θ包含要学习的所有CNN参数,B*,R和∇B是对应于其ground truth B,R和∇B的估计结果。为了使每个估计任务都可以利用其他任务的信息,这三个协作网络彼此共享卷积层。整个网络是在CencN的基础上构建的,以提取具有全局结构和场景高级语义信息的上下文信息。对于GdecN,它采用CencN较浅层的信息作为输入并估算∇B。它可以从多个尺度提取图像梯度信息,并指导整个图像重建过程。 IdecN将来自CencN较深层的特征信息作为输入,并通过使用多上下文信息提取背景特征表示估计B和R。
3.2CencN
在较深的卷积层中学习的滤波器倾向于捕获与背景相关的信息,而与反射相关的细节保留在较浅的层中。
3.3GdecN
GdecN旨在学习从I到∇B的映射。 如上图,CencN的较浅层包含更多与整个图像的小细节有关的局部信息。 为了在接收场大小和可用图像信息之间取得平衡,我们使用CencN的第四层作为GdecN的输入,以充分利用图像细节来估计梯度。 在GdecN中,对CencN的特征进行上采样并组合以重建输出梯度,而不会产生反射干扰。 为了更好地保留清晰的细节并避免梯度消失的问题,将CencN的特征以相同的空间分辨率链接到其在GdecN中对应的图层。 下图中:GdecN成功地从反射中消除梯度,并保留属于背景的梯度。
3.4 IdecN
我们直接采用CencN的最后一层作为IdecN的输入,以避免 来自反射的干扰。 如标为“特征提取层A/B”的部分。IdecN包含两个用于提取multi-上下文和尺度不变特征的特征提取层,以及五个转置的卷积层以逐步对特征图进行上采样。采用来自 Inception-ResNet-v2中的“ Reduction-A/B”作为IdecN的‘特征提取层A/B”,这两个模型由于其多尺寸内核而能够提取尺度不变和多上下文特征。 但是,由于池化层导致的特征减少,因此很少将它们用于图像到图像的问题。本文进行了两项修改:
(1)将原始模型中的池化层由1×1和7×7的两个卷积层替代。
(2)将所有卷积的步幅减小到1。
3.5 Multi-scale guidance
观察到一层具有较大的梯度值而另一层具有较小的梯度值,在现有的层分离问题(例如,反射去除和固有图像分解)中广泛采用了梯度特征。 该观察结果表明,在梯度域中可以更好地区分具有较大梯度值的背景像素和具有较小梯度值的反射像素。 因此,我们也将这种梯度先验嵌入到图像解码器网络中,以提高最终解决方案的稳定性。 由于我们网络中使用了多尺度策略,我们通过将GdecN中每个转置的卷积层的输出与IdecN中转置的卷积层的输出串联在一起,将传统的单尺度梯度嵌入方案扩展为多尺度方案。在上图为“Multi-scale guided inference”。
但是,如果直接使用GdecN的特征图,则仍会显示与反射相关的明显伪像,尤其是对于那些来自GdecN初始阶段的特征图。 它可能导致最终估计结果中的残留边缘。 本文在IdecN和GdecN之间添加了内核大小为7×7的特征增强层,以将具有反射的特征映射到具有相对较少反射的特征空间,称为“Feature enhancement layer”。
3.6损失函数
SSIM+Statistic Loss
4、结果
本文提出了一个合作网络,可以有效地消除单个图像的反射。 不同于将梯度推理和图像推理视为两个单独的过程或两流并发模型的常规管道,本文的网络将它们统一为一个协作框架,该框架集成了高级图像上下文 信息和多尺度的低级功能。
局限性
1)饱和的反射。由于在具有饱和反射的区域中背景信息的丢失,反射去除问题已退化为图像修复问题,对于所有反射去除方法而言,这已被视为非常具有挑战性的情况。例如,当白灯泡区域中的背景信息完全丢失时,几乎所有方法都无法有效消除反射。但是,本文的方法仍然比其他方法表现更好。
(2)颜色偏移。在我们的网络中有许多卷积层的情况下,我们的方法在某些特定情况下(尤其是明信片数据集)会遇到颜色偏移问题。但是,可以通过许多现有的色彩平衡方法轻松缓解此类问题。例如,将估计图像中的颜色信息重新缩放为ground truth。重新缩放后的结果变得更好。
(3)数据生成。需要进一步提高反射图像的捕获设置和场景的多样性。这些问题可能会限制本文训练数据集的泛化能力。