文章目录
随机森林(Random Forest)是一个集成算法,多棵决策树就组成了一个森林,下面具体讲一下这个算法和应用的源码。
(1)随机森林算法介绍
随机森林是以决策树作为基础模型的集成算法。随机森林是机器学习模型中用于分类和回归的最成功的模型之一。通过组合大量的决策树来降低过拟合的风险。与决策树一样,随机森林处理分类特征,扩展到多类分类设置,不需要特征缩放,并且能够捕获非线性和特征交互。
随机森林分别训练一系列的决策树,所以训练过程是并行的。因算法中加入随机过程,所以每个决策树又有少量区别。通过合并每个树的预测结果来减少预测的方差,提高在测试集上的性能表现。
随机性体现
1.每次迭代时,对原始数据进行二次抽样来获得不同的训练数据
2.对于每个树节点,考虑不同的随机特征子集来进行分裂
除此之外,决策时的训练过程和单独决策树训练过程相同。
对新实例进行预测时,随机森林需要整合其各个决策树的预测结果。回归和分类问题的整合的方式略有不同。分类问题采取投票制,每个决策树投票给一个类别,获得最多投票的类别为最终结果。回归问题每个树得到的预测结果为实数,最终的预测结果为各个树预测结果的平均值。
Spark的随机森林算法支持二分类、多分类以及回归的随机森林算法,适用于连续特征以及类别特征。
(2)随机森林应用场景
分类任务:
1、广告系统的点击率预测
2、推荐系统的二次rerank排序
3、金融行业可以用随机森林做贷款风险评估
4、保险行业可以用随机森林做险种推广预测
5、医疗行业可以用随机森林生成辅助诊断处置模型
回归任务
1、预测一个孩子的身高
2、电商网站的商品销量预测
随机森林是由多颗决策树组成,决策能做的随机森林也都能做,并且效果更好。
(3) Spark随机森林训练和预测过程
随机森林分别训练一组决策树,因此训练可以并行完成。该算法将随机性注入训练过程,以使每个决策树略有不同。结合每棵树的预测可以减少预测的方差,提高测试数据的性能。
训练
注入训练过程的随机性包括:
在每次迭代时对原始数据集进行二次采样,以获得不同的训练集(例如,bootstrapping)
考虑在每个树节点处分割的不同随机特征子集
除了这些随机化之外,决策树训练的方式与单个决策树的方式相同
预测
要对新实例进行预测,随机森林必须整合各个决策树的预测。对于分类和回归,这种整合的方式不同
分类
多数票原则。每棵树的预测都算作一个类的投票。预计该标签是获得最多选票的类别
回归
平均。每棵树预测一个真实的值。预测标签是各个树预测的平均值
(4) Spark随机森林模型参数详解
随机森林的参数比较多,我们实际工作中经常会调整参数值,让模型达到一个最优的状态,除了调参的方法,还有就是通过手工改进每个特征的计算公式,增加数据特征,不断的优化模型。参数调优是实际工作中不可或缺的一个必要环节,让我们看一下都有哪些参数:
类型1:整数型
含义:设置检查点间隔(>=1),或不设置检查点(-1)
类型2:字符串型
含义:每次分裂候选特征数量
类型3:字符串型
含义:特征列名
类型4:字符串型
含义:计算信息增益的准则(不区分大小写)
类型5:字符串型
含义:计算信息增益的准则(不区分大小写)
类型6:字符串型
含义:标签列名
类型7:整数型
含义:连续特征离散化的最大数量,以及选择每个节点分裂特征的方式
类型8:整数型
含义:树的最大深度(>=0)
决策树最大深度max_depth, 默认可以不输入,如果不输入的话,决策树在建立子树的时候不会限制子树的深度。一般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间
参数效果:值越大,决策树越复杂,越容易过拟合
类型9:双精度型
含义:分裂节点时所需最小信息增益
类型10:整数型
含义:分裂后自节点最少包含的实例数量
类型11:整数型
含义:训练的树的数量
类型12:字符串型
含义:预测结果列名
类型13:字符串型
含义:类别条件概率预测结果列名
类型14:字符串型
含义:原始预测
类型15:长整型
含义:随机种子
类型16:双精度型
含义:学习一棵决策树使用的训练数据比例,范围[0,1]
类型17:双精度数组型
含义:多分类预测的阀值,以调整预测结果在各个类别的概率
上面的参数有的对准确率影响很大,有的比较小。其中maxDepth最大深度这个参数对精准度影响很大,但设置过高容易过拟合。应该根据实际情况设置一个合理的值,但一般不超过20。
(5) Spark随机森林源码实战
训练数据格式和上面讲的决策树是一样的,随机森林可以用来做二值分类,也可以多分类,还可以用它来做回归,用来做回归的应用场景,比如做销量预测,也能起到非常好的效果,虽然做销量预测用时间序列算法比较多,但随机森林的效果不逊色于时间序列,这得在参数调优和特征工程调优上下功夫。下面的代码演示了如何训练数据模型,根据模型预测特征属于哪个分类,并且演示了模型如何做持久化和加载的完整过程。

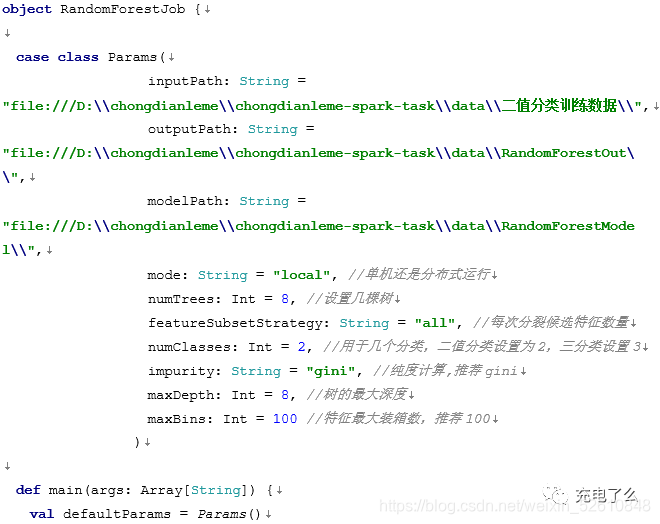







上面讲的随机森林算法是有多棵决策树组成的,是一个集成算法,属于Bagging词袋模型,我们看下它是如何工作的。
工作原理
基于Bagging的随机森林(Random Forest)是决策树集合。在随机森林中,我们收集了许多决策树(被称为“森林”)。为了根据属性对新对象进行分类,每个树都给出分类,然后对这些树的结果进行“投票”,最终选择投票得数最多的哪一类别。
每棵树按以下方法构建:
如果取 N 例训练样本作为来训练每棵树,则随机抽取1例样本,再有放回地进行下一次抽样。每次抽样得到的 N 个样本作为一棵树的训练数据。
如果存在 M 个输入变量(特征值),则指定一个数字 m(远小于 M),使得在每个节点处,随机地从 M 中选择 m 个特征,并使用这些m 个特征来对节点进行最佳分割。在森林生长过程中,m 的值保持不变。
每棵树都尽可能自由生长。没有修剪。
随机森林的优势
该算法可以解决两类问题,即分类和回归,并在两个方面进行了不错的估计。
最令我兴奋的随机森林的好处之一是处理具有更高维度的大数据集的能力。它可以处理数千个输入变量并识别最重要的变量,因此它被视为降维方法之一。此外,模型输出变量的重要性, 这可以是一个非常方便的功能(在一些随机数据集上)。
它有一种估算缺失数据的有效方法,并在大部分数据丢失时保持准确性。
它具有平衡类不平衡的数据集中的错误的方法。
上述功能可以扩展到未标记的数据,从而导致无监督的聚类,数据视图和异常值检测。
随机森林涉及输入数据的采样,替换称为自举采样。这里有三分之一的数据不用于培训,可用于测试。这些被称为袋外样品。对这些袋外样品的估计误差称为 袋外误差。通过Out of bag进行误差估计的研究,证明了袋外估计与使用与训练集相同大小的测试集一样准确。因此,使用out-of-bag误差估计消除了对预留测试集的需要。
随机森林的缺点
它确实在分类方面做得很好,但不如回归问题好,因为它没有给出精确的连续性预测。在回归的情况下,它不会超出训练数据的范围进行预测,并且它们可能过度拟合特别嘈杂的数据集。
随机森林可以感觉像统计建模者的黑盒子方法 - 你几乎无法控制模型的作用。你最多可以尝试不同的参数和随机种子!
在实际使用中还发现Spark随机森林有一个问题, Spark默认的随机森林的二值分类预测只返回0和1,不能返回概率值。比如预测广告被点击的概率,如果都是1的话哪个排在前面,哪个排在后面呢?我们需要更严谨的排序,必须是一个连续的小数值。因此,需要对原始的Spark随机森林算法做二次开发,让它能返回一个支持概率的数值。
改源码一般来说会比较复杂,因为再改之前,得能看懂它的源码。否则你不知道从哪儿下手。看懂后,找到最关键的需要修改的函数后,尽可能较小改动来实现你的业务功能,以免改动较多产生别的bug。下面我们讲一下如果做二次开发,使随机森林能满足我们的需求。
(6)Spark随机森林训练和预测过程
Spark随机森林改成支持概率值只需要改动一个类treeEnsembleModels.scala即可。
修改原来的两个函数如下:
/**
-
Predict values for a single data point using the model trained.
-
@param features array representing a single data point
-
@return predicted category from the trained model
*/
def predict(features: Vector): Double = {
(algo, combiningStrategy) match {
case (Regression, Sum) =>
predictBySumming(features)
case (Regression, Average) =>
predictBySumming(features) / sumWeights
case (Classification, Sum) => // binary classification
val prediction = predictBySumming(features)
// TODO: predicted labels are +1 or -1 for GBT. Need a better way to store this info.
if (prediction > 0.0) 1.0 else 0.0
case (Classification, Vote) =>
predictByVoting(features)
case _ =>
throw new IllegalArgumentException(
"TreeEnsembleModel given unsupported (algo, combiningStrategy) combination: " +
s"($algo, $combiningStrategy).")
}
}
/**
- Classifies a single data point based> */
private def predictByVoting(features: Vector): Double = {
val votes = mutable.Map.empty[Int, Double]
trees.view.zip(treeWeights).foreach { case (tree, weight) =>
val prediction = tree.predict(features).toInt
votes(prediction) = votes.getOrElse(prediction, 0.0) + weight
}
votes.maxBy(_._2)._1
}
修改后的两个函数:
def predictChongDianLeMe(features: Vector): Double = {
(algo, combiningStrategy) match {
case (Regression, Sum) =>
predictBySumming(features)
case (Regression, Average) =>
predictBySumming(features) / sumWeights
case (Classification, Sum) => // binary classification
val prediction = predictBySumming(features)
// TODO: predicted labels are +1 or -1 for GBT. Need a better way to store this info.
if (prediction > 0.0) 1.0 else 0.0
case (Classification, Vote) =>
//我们用的是基于投票的分类算法,关键改这里。用我们自己实现的投票算法。
predictByVotingChongDianLeMe(features)
case _ =>
throw new IllegalArgumentException(
"TreeEnsembleModel given unsupported (algo, combiningStrategy) combination: " +
s"($algo, $combiningStrategy).")
}
}
private def predictByVotingChongDianLeMe(features: Vector): Double = {
val votes = mutable.Map.empty[Int, Double]
trees.view.zip(treeWeights).foreach { case (tree, weight) =>
val prediction = tree.predict(features).toInt
votes(prediction) = votes.getOrElse(prediction, 0.0) + weight
}
//通过filter筛选找到投票结果后的投赞成票的树的记录
val zVotes = votes.filter(p => p._1==1)
var zTrees = 0.0
if (zVotes.size > 0) {
zTrees = zVotes.get(1).get
}
//返回投赞成票的树的数量zTrees,我们训练设置树的个数是总数total,zTrees*1.0/total=概率,就是广告被点击的一个概率小数值。
zTrees
}
这样我们就修改完代码,预测函数返回的是投赞成票的树的数量zTrees,如果我们在调用端的时候改成我们的概率值,我们训练设置树的个数是总数total,zTrees*1.0/total=概率,就是广告被点击的一个概率小数值。当然你也可以不改成小数,就按这个zTrees的赞成票数量来排序也是可以的。修改完之后需要对项目编译打包。Spark的工程非常大,要是把源码环境都调好了,不是那么容易。实际上会遇到很多的问题,才能把环境搞好。另外一个就是修改完代码,打包的话如果之前没搞过,也得摸索下。把编译打好的jar包替换掉线上集群的对应的jar包即可。
(7) 随机森林和GBDT的联系和区别
上面讲的随机森林是基于Bagging的词袋模型,同样在Spak里面有多棵树组成集成算法还有GradientBoostedTrees算法,GradientBoostedTrees可以简称为GBDT,它也是集成算法,属于Boosting集成算法,但它和Bagging有什么区别呢?
Bagging的方式算是比较简单的,训练多个模型,利用每个模型进行投票,每个模型的权重都一样,对于分类问题,取总票数最多作为分类,对于回归,取平均值。利用多个弱分类器,集成一个性能高的分类器。典型代表是随机森林。随机森林在训练每个模型的时,增加随机的因素,对特征和样本进行随机抽样,然后把各颗树训练的结果集成融合起来。随机森林可以进行并行训练多颗树。
Boosting的方式也是训练多个决策树模型,是一种迭代的算法模型,在训练过程中更加关注错分的样本,对于越是容易错分的样本,后续的模型训练越要花更多精力去关注,提高上一次分错的数据权重,越在意那些分错的数据。在集成融合时,每次训练的模型权重也会不一样,最终通过加权的方式融合成最终的模型。Adaboost、GBDT采用的都是boosting的思想。
总结
此文章有对应的配套视频,除了随机森林,其它更多精彩文章请大家下载充电了么app,可获取千万免费好课和文章,配套新书教材请看陈敬雷新书:《分布式机器学习实战》(人工智能科学与技术丛书)
【新书介绍】
《分布式机器学习实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】
新书特色:深入浅出,逐步讲解分布式机器学习的框架及应用配套个性化推荐算法系统、人脸识别、对话机器人等实战项目
【新书介绍视频】
分布式机器学习实战(人工智能科学与技术丛书)新书【陈敬雷】
视频特色:重点对新书进行介绍,最新前沿技术热点剖析,技术职业规划建议!听完此课你对人工智能领域将有一个崭新的技术视野!职业发展也将有更加清晰的认识!
【精品课程】
《分布式机器学习实战》大数据人工智能AI专家级精品课程
【免费体验视频】:
视频特色: 本系列专家级精品课有对应的配套书籍《分布式机器学习实战》,精品课和书籍可以互补式学习,彼此相互补充,大大提高了学习效率。本系列课和书籍是以分布式机器学习为主线,并对其依赖的大数据技术做了详细介绍,之后对目前主流的分布式机器学习框架和算法进行重点讲解,本系列课和书籍侧重实战,最后讲几个工业级的系统实战项目给大家。 课程核心内容有互联网公司大数据和人工智能那些事、大数据算法系统架构、大数据基础、Python编程、Java编程、Scala编程、Docker容器、Mahout分布式机器学习平台、Spark分布式机器学习平台、分布式深度学习框架和神经网络算法、自然语言处理算法、工业级完整系统实战(推荐算法系统实战、人脸识别实战、对话机器人实战)、就业/面试技巧/职业生涯规划/职业晋升指导等内容。
【充电了么公司介绍】
充电了么App是专注上班族职业培训充电学习的在线教育平台。
专注工作职业技能提升和学习,提高工作效率,带来经济效益!今天你充电了么?
充电了么官网
http://www.chongdianleme.com/
充电了么App官网下载地址
https://a.app.qq.com/o/simple.jsp?pkgname=com.charged.app
功能特色如下:
【全行业职位】 - 专注职场上班族职业技能提升
覆盖所有行业和职位,不管你是上班族,高管,还是创业都有你要学习的视频和文章。其中大数据智能AI、区块链、深度学习是互联网一线工业级的实战经验。
除了专业技能学习,还有通用职场技能,比如企业管理、股权激励和设计、职业生涯规划、社交礼仪、沟通技巧、演讲技巧、开会技巧、发邮件技巧、工作压力如何放松、人脉关系等等,全方位提高你的专业水平和整体素质。
【牛人课堂】 - 学习牛人的工作经验
1.智能个性化引擎:
海量视频课程,覆盖所有行业、所有职位,通过不同行业职位的技能词偏好挖掘分析,智能匹配你目前职位最感兴趣的技能学习课程。
2.听课全网搜索
输入关键词搜索海量视频课程,应有尽有,总有适合你的课程。
3.听课播放详情
视频播放详情,除了播放当前视频,更有相关视频课程和文章阅读,对某个技能知识点强化,让你轻松成为某个领域的资深专家。
【精品阅读】 - 技能文章兴趣阅读
1.个性化阅读引擎:
千万级文章阅读,覆盖所有行业、所有职位,通过不同行业职位的技能词偏好挖掘分析,智能匹配你目前职位最感兴趣的技能学习文章。
2.阅读全网搜索
输入关键词搜索海量文章阅读,应有尽有,总有你感兴趣的技能学习文章。
【机器人老师】 - 个人提升趣味学习
基于搜索引擎和智能深度学习训练,为您打造更懂你的机器人老师,用自然语言和机器人老师聊天学习,寓教于乐,高效学习,快乐人生。
【精短课程】 - 高效学习知识
海量精短牛人课程,满足你的时间碎片化学习,快速提高某个技能知识点。