一、简介
论文:Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
微软13年提出的计算文本相似度的深度学习模型,核心思想是将query和doc映射到到共同维度的语义空间中,通过最大化query和doc语义向量之间的余弦相似度,从而训练得到隐含语义模型,达到检索的目的。DSSM有很广泛的应用,比如:搜索引擎检索,广告相关性,问答系统,机器翻译等。
网络框架如下:
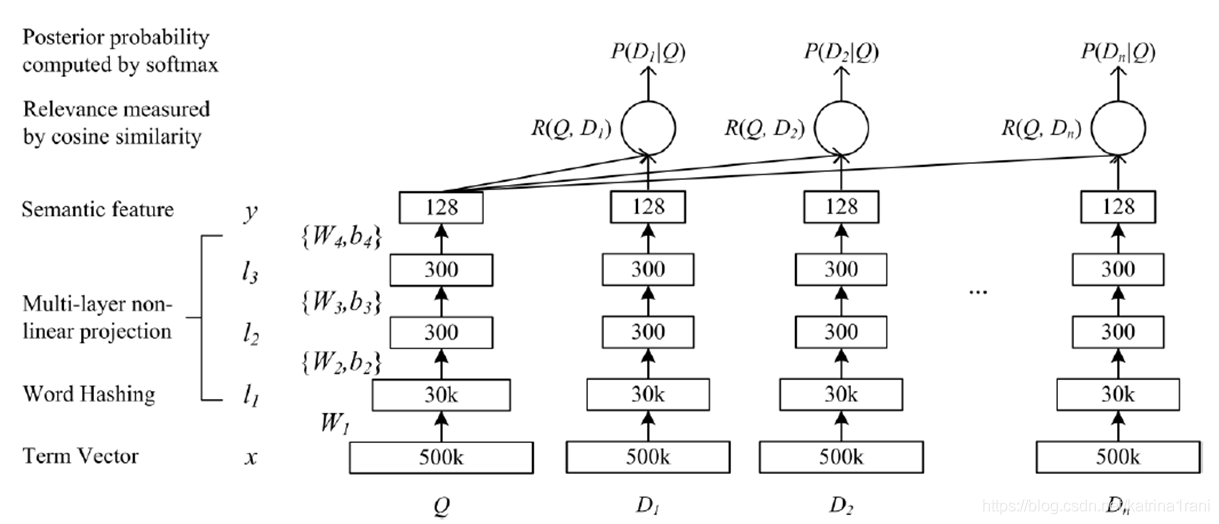
二、 原理
对输入文本的one-hot向量,通过Word Hashing达到降维的效果,接下来送到传统的神经网络抽取语义特征,计算语义特征之间的相似度。
2.1 Word hashing
需要注意的是原论文中的DSSM处理的数据是英文数据,对于英文数据来说,英文单词的数量是很庞大的,可以看作无限集合,但是26个英文字母对应的ngram集合就是有限的集合。论文采用对单词进行切分为ngram形式,从而达到一个初步降维的效果。
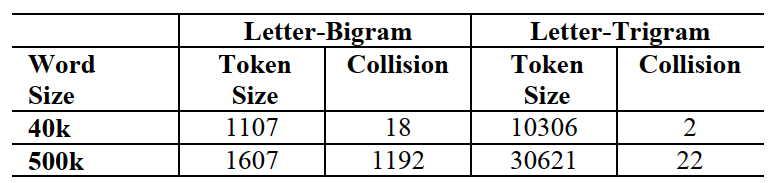
例如,对于单词good,首先添加前后标记“#good#”,进一步切分为trigram形式,[ #go, goo, ood, od#]。这样可能面临一个问题,可能有的单词对应的ngram word hashing结果是相同的,会有冲突,作者进行了统计,得到如下结论:
1. word hashing能有效达到降维效果
2. 冲突的比例很少
另外Word Hashing还有个优点是:基于词的特征表示比较难处理新词,字母的 ngram可以有效表示,鲁棒性较强。
2.2 全连接层
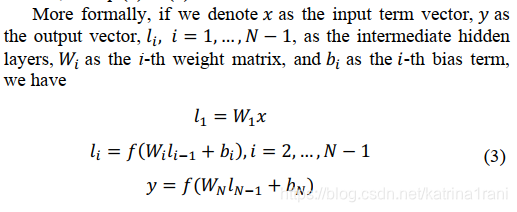
采用全连接, 通过输入乘W权重,再加上bias;激活函数采用了tanh激活函数:
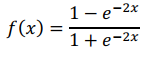
经过N层全连接层之后得到y值,即通过全连接层抽取特征得到的向量值
2.3 相似度计算
相似度计算:
最后通过余弦相似度计算query和document之间的相似度:
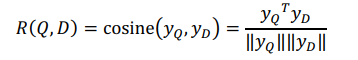
概率值计算:
最后通过softmax进行归一化:
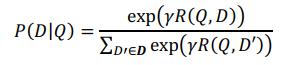
这里需要注意一下, 这里添加了个![]() 作为平滑因子,这里这个平滑因子很重要,控制值的大小,
作为平滑因子,这里这个平滑因子很重要,控制值的大小,![]() 越大,正例值越大,负例值越小,对训练阶段有影响。 对训练梯度影响比较大,有时候收敛比较快,有时候会导致过拟合。
越大,正例值越大,负例值越小,对训练阶段有影响。 对训练梯度影响比较大,有时候收敛比较快,有时候会导致过拟合。
2.4 损失函数
损失函数采用了对数损失函数,且只对正例数据最大化:
![]()
这里采用对数损失函数的原因,是因为前面使用了概率计算,这样在训练阶段通过极大似然估计来最小化损失函数,模型通过梯度下降来优化。
三、实验效果
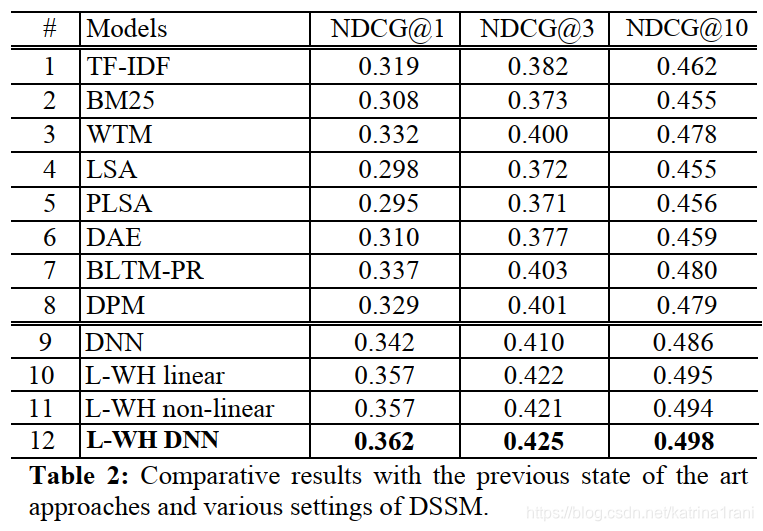
四、优缺点:
DSSM算法有以下优缺点:
优点:
- 解决了LSA、LDA、Autoencoder等方法存在的一个最大的问题:字典爆炸(导致计算复杂度非常高),因为在英文单词中,词的数量可能是没有限制的,但是字母 ngram的数量通常是有限的
- 基于词的特征表示比较难处理新词,字母的 ngram可以有效表示,鲁棒性较强
- 使用有监督方法,优化语义embedding的映射问题
- 省去了人工的特征工程
缺点:
- word hashing可能造成冲突
- DSSM采用了词袋模型,损失了上下文信息
- 在排序中,搜索引擎的排序由多种因素决定,由于用户点击时doc的排名越靠前,点击的概率就越大,如果仅仅用点击来判断是否为正负样本,噪声比较大,难以收敛
五、扩展
中文处理
大家注意到,论文中是对英文数据进行处理,包括Word Hashing 只对英文有效,对于中文反而会起到反作用,引起维度爆炸。但是作者利用DL得到特征表示,最后通过余弦计算相似度的思想是可以借鉴的。 这里想起来要说一点,论文提到可以通过存储特征表示的y值,从而达到降低线上时间成本。
这里我们对于中文的使用过程中,通常将DNN替换成BiLSTM+attention或者BERT,输入端直接用词向量作为输入即可。
模型变种
对DSSM的优化出现了很多的变种,有CNN-DSSM,LSTM-DSSM,MV-DSSM等。大多对隐藏层做了一些修改,原论文如下:
CNN-DSSM:http://www.iro.umontreal.ca/~lisa/pointeurs/ir0895-he-2.pdf
LSTM-DSSM:https://arxiv.org/pdf/1412.6629.pdf
MV-DSSM:https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/frp1159-songA.pdf
七、参考链接:
DSSM论文阅读与总结 https://zhuanlan.zhihu.com/p/53326791
DSSM(以及CNN-DSSM,LSTM-DSSM) https://blog.csdn.net/jokerxsy/article/details/107169406
DSSM算法-计算文本相似度 https://www.cnblogs.com/wmx24/p/10157154.html
基于深度学习的语义匹配若干模型DSSM,ESIM, BIMPM, ABCNN https://blog.csdn.net/pengmingpengming/article/details/88534968
才疏学浅,如哪里有错误,请指出,谢谢!
部分参考其它博文,如有侵权,请联系我!