关于simnet提出背景以及可以应用的地方,机器之心这篇文章里已经说得非常详细了。https://www.jiqizhixin.com/articles/2017-06-15-5
本文主要是记录一下自己使用simnet做语义匹配任务的流程,并对代码各个模块的功能进行整理和解释。
一、模型结构
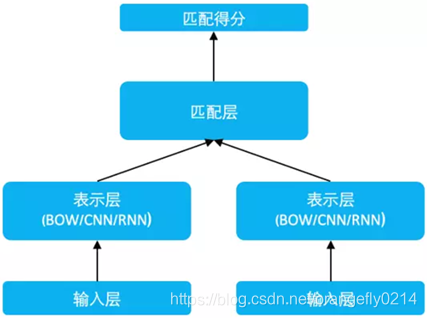
SimNet 框架如上图所示,主要分为输入层、表示层和匹配层。
各个层的功能:
1.输入层
该层通过 look up table 将文本词序列转换为 word embedding 序列。
2.表示层
该层主要功能是由词到句的表示构建,或者说将序列的孤立的词语的 embedding 表示,转换为具有全局信息的一个或多个低维稠密的语义向量。最简单的是 Bag of Words(BOW)的累加方法,除此之外,我们还在 SimNet 框架下研发了对应的序列卷积网络(CNN)、循环神经网络(RNN)等多种表示技术。当然,在得到句子的表示向量后,也可以继续累加更多层全连接网络,进一步提升表示效果。
3.匹配层
该层利用文本的表示向量进行交互计算,根据应用的场景不同,有两种匹配算法。
Representation-based Match和Interaction-based Match。
而在Representation-based Match有两种计算方式:

且通常选用的都是Representation-based Match的方法。
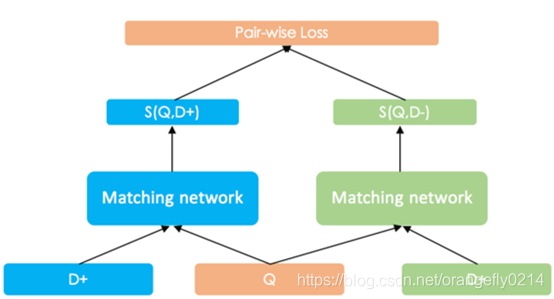
若采用pair-wise Ranking Loss 来进行 SimNet 的训练。以网页搜索任务为例,假设搜索查询文本为 Q,相关的一篇文档为 D+,不相关的一篇文档为 D-,二者经过 SimNet 网络得到的和 Q 的匹配度得分分别为 S(Q,D+) 和 S(Q,D-),而训练的优化目标就是使得 S(Q,D+)>S(Q,D-)。
实际中,我们一般采用 Max-Margin 的 Hinge Loss:
max{0,margin-(S(Q,D+)-S(Q,D-))}
二、运用
使用这个开源代码来完成语义匹配任务通常需要以下几个步骤:
1. 首先我们需要将需要计算匹配度的句对进行转换,变成tfrecord的格式。
2.搭建网络。
3.读取数据进行训练
4.进行测试。
simnet中提供了多种网络供选择,并且也有不同的loss可以选择进行优化,这里我们只选用pointwise格式的数据,用MLPCnn网络,SoftmaxWithLoss的损失函数来构建我们特定的模型。
MPLCNN网络的结构:
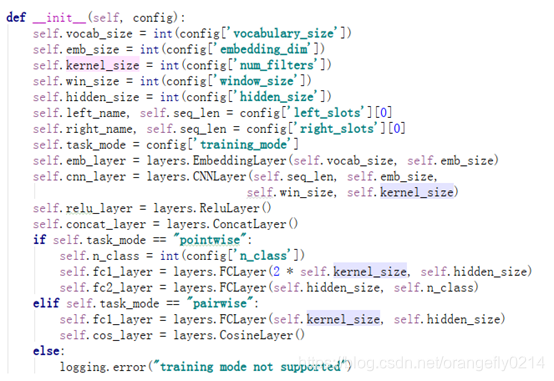
输入-输入进行embedding-embedding结果进CNN-CNN结果经过relu-relu出来后对左右进行concat-concat后接全连接层(
如果是pointwise,现将左右结果进行concat,然后通过fc1,然后通过relu,再通过fc2,输出pred(全连接层实际上是X*W+b的一个计算。
如果是pairwise,则relu出来后不需要讲左右进行concat,直接将relu出来的左右结果经过fc1,fc1的输出结果经过cosine Layer然后输出预测值)
代码如下:
# coding:utf-8
from collections import Counter
import logging
import numpy
import time
import sys
import os
import json
import tensorflow as tf
import traceback
import math
fwords = "data/word2id.json"
forigin_train_corpus = "data/train.sample"
forigin_test_corpus = "data/test.sample"
ftrain_pointwise = "data/kesci_train_pointwise.txt"
ftest_pointwise = "data/kesci_test_pointwise.txt"
ftrain_pointwise_data = "kesci_train_pointwise.data"
ftest_pointwise_data = "kesci_test_pointwise.data"
############################################################
# 0: 转换数据格式
def data2pointwise(fin, fout, fwords):
word2id = json.load(open(fwords, "r"))
with open(fin, "r") as fr, open(fout, "w") as fw:
for line in fr:
line = line.strip().split(",")
q = [word2id[w] for w in line[1].split() if w in word2id]
d = [word2id[w] for w in line[3].split() if w in word2id]
if len(q) < 5 or len(d) < 5:
continue
q = list(map(str, q))
d = list(map(str, d))
fw.write(" ".join(q) + "\t" + " ".join(d) + "\t" + line[4] + "\n")
print(u"将原始数据转换为simnet输入格式:")
data2pointwise(forigin_train_corpus, ftrain_pointwise, fwords)
data2pointwise(forigin_test_corpus, ftest_pointwise, fwords)
##################################################################
# 1:转换tfrecord格式
def int_feature(v):
return tf.train.Feature(int64_list=tf.train.Int64List(value=v))
def parse_text_match_pointwise_pad_data(line, func_args):
seq_len = func_args[0]
pad_id = func_args[1]
group = line.strip().split("\t")
label = [0, 0]
all_ids = []
for i in [0, 1]:
tmp_ids = [int(t) for t in group[i].strip().split(" ")]
if len(tmp_ids) < seq_len:
pad_len = seq_len - len(tmp_ids)
tmp_ids = tmp_ids + [pad_id] * pad_len
all_ids.append(tmp_ids[:seq_len])
label[int(group[2])] = 1
example = tf.train.Example(features=tf.train.Features(
feature={"label": int_feature(label),
"left": int_feature(all_ids[0]),
"right": int_feature(all_ids[1])}))
return example
def write_data_to_tf(filename, func, func_args, writer):
with open(filename) as fin_data:
for line in fin_data:
example = func(line, func_args)
if not example:
continue
writer.write(example.SerializeToString())
print(u"将输入格式转换为tfrecord格式:train")
local_writer = tf.python_io.TFRecordWriter(ftrain_pointwise_data)
write_data_to_tf(ftrain_pointwise, parse_text_match_pointwise_pad_data, [40,0],local_writer)
local_writer.close()
print(u"将输入格式转换为tfrecord格式:test")
local_writer = tf.python_io.TFRecordWriter(ftest_pointwise_data)
write_data_to_tf(ftest_pointwise, parse_text_match_pointwise_pad_data, [40,0],local_writer)
local_writer.close()
#加载config文件
def load_config(config_file):
"""
load config
"""
with open(config_file, "r") as f:
try:
conf = json.load(f)
except Exception:
logging.error("load json file %s error" % config_file)
conf_dict = {}
unused = [conf_dict.update(conf[k]) for k in conf]
logging.debug("\n".join(
["%s=%s" % (u, conf_dict[u]) for u in conf_dict]))
return conf_dict
#2. 网络部分:构建MLPCNN
class ConcatLayer(object):
"""
a layer class: concat layer
"""
def __init__(self):
"""
init function
"""
pass
def ops(self, blobs, concat_size):
"""
operation
"""
return tf.reshape(tf.concat(blobs, 1), [-1, concat_size])
class CosineLayer(object):
"""
a layer class: cosine layer
"""
def __init__(self):
"""
init function
"""
pass
def ops(self, input_a, input_b):
"""
operation
"""
norm_a = tf.nn.l2_normalize(input_a, dim=1)
norm_b = tf.nn.l2_normalize(input_b, dim=1)
cos_sim = tf.expand_dims(tf.reduce_sum(tf.multiply(norm_a, norm_b), 1), -1)
return cos_sim
class FCLayer(object):
"""
a layer class: a fc layer implementation in tensorflow
"""
def __init__(self, num_in, num_out):
"""
init function
"""
self.num_in = num_in
self.num_out = num_out
self.weight = tf.Variable(tf.random_normal([num_in, num_out]))
self.bias = tf.Variable(tf.random_normal([num_out]))
def ops(self, input_x):
"""
operation
"""
out_without_bias = tf.matmul(input_x, self.weight)
output = tf.nn.bias_add(out_without_bias, self.bias)
return output
class ReluLayer(object):
"""
a layer class: relu Activation function
"""
def __init__(self):
"""
init function
"""
pass
def ops(self, input_x):
"""
operation
"""
return tf.nn.relu(input_x)
class EmbeddingLayer(object):
"""
a layer class: embedding layer
"""
def __init__(self, vocab_size, emb_dim):
"""
init function
"""
self.vocab_size = vocab_size
self.emb_dim = emb_dim
init_scope = math.sqrt(6.0 / (vocab_size + emb_dim))
emb_shape = [self.vocab_size, self.emb_dim]
self.embedding = tf.Variable(tf.random_uniform(
emb_shape, -init_scope, init_scope))
def ops(self, input_x):
"""
operation
"""
return tf.nn.embedding_lookup(self.embedding, input_x)
class CNNLayer(object):
"""
a layer class: A CNN layer implementation in tensorflow
"""
def __init__(self, seq_len,
emb_dim, win_size, kernel_size):
"""
init function
"""
self.max_seq_len = seq_len
self.emb_dim = emb_dim
self.win_size = win_size
self.kernel_size = kernel_size
filter_shape = [self.win_size, self.emb_dim, 1, self.kernel_size]
self.conv_w = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1),
name="conv")
self.bias = tf.Variable(tf.constant(0.1, shape=[self.kernel_size]),
name="bias")
def ops(self, emb):
"""
operation
"""
emb_expanded = tf.expand_dims(emb, -1)
conv = tf.nn.conv2d(emb_expanded, self.conv_w,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv_op")
h = tf.nn.bias_add(conv, self.bias)
pool = tf.nn.max_pool(h,
ksize=[1, self.max_seq_len - self.win_size + 1,
1, 1],
strides=[1, 1, 1, 1],
padding="VALID",
name="pool")
pool_flat = tf.reshape(pool, [-1, self.kernel_size])
return pool_flat
class MLPCnn(object):
"""
mlp cnn init function
"""
def __init__(self, config):
self.vocab_size = int(config['vocabulary_size'])
self.emb_size = int(config['embedding_dim'])
self.kernel_size = int(config['num_filters'])
self.win_size = int(config['window_size'])
self.hidden_size = int(config['hidden_size'])
self.left_name, self.seq_len = config['left_slots'][0]
self.right_name, self.seq_len = config['right_slots'][0]
self.task_mode = config['training_mode']
self.emb_layer = EmbeddingLayer(self.vocab_size, self.emb_size)
self.cnn_layer = CNNLayer(self.seq_len, self.emb_size,
self.win_size, self.kernel_size)
self.relu_layer =ReluLayer()
self.concat_layer =ConcatLayer()
if self.task_mode == "pointwise":
self.n_class = int(config['n_class'])
self.fc1_layer = FCLayer(2 * self.kernel_size, self.hidden_size)
self.fc2_layer = FCLayer(self.hidden_size, self.n_class) #pointwise的计算方式直接是通过FC层后加一个W*x+b进行拟合匹配分数
elif self.task_mode == "pairwise":
self.fc1_layer = FCLayer(self.kernel_size, self.hidden_size) #pairwise的计算方式是将FC层的左右输出通过计算cosine获得匹配分数
self.cos_layer = CosineLayer()
else:
logging.error("training mode not supported")
def predict(self, left_slots, right_slots):
"""
predict graph of this net
"""
left = left_slots[self.left_name] #左边输入
right = right_slots[self.right_name] #右边输入
left_emb = self.emb_layer.ops(left) #左边输入做embedding
right_emb = self.emb_layer.ops(right) #右边输入做embedding
left_cnn = self.cnn_layer.ops(left_emb) #左边embedding后进cnn
right_cnn = self.cnn_layer.ops(right_emb)
left_relu = self.relu_layer.ops(left_cnn) #cnn层出来后进入RELU层
right_relu = self.relu_layer.ops(right_cnn)
if self.task_mode == "pointwise":
concat = self.concat_layer.ops([left_relu, right_relu], self.kernel_size * 2)
concat_fc = self.fc1_layer.ops(concat)
concat_relu = self.relu_layer.ops(concat_fc) #将concat_fc通过relu函数
pred = self.fc2_layer.ops(concat_relu) #再将结果*W+b得到预测输出结果
else:
hid1_left = self.fc1_layer.ops(left_relu)
hid1_right = self.fc1_layer.ops(right_relu)
left_relu2 = self.relu_layer.ops(hid1_left)
right_relu2 = self.relu_layer.ops(hid1_right)
pred = self.cos_layer.ops(left_relu2, right_relu2)
return pred
#loss计算:返回label和logits之间的交叉熵
class SoftmaxWithLoss(object):
"""
a layer class: softmax loss
"""
def __init__(self):
"""
init function
"""
pass
def ops(self, pred, label):
"""
operation:计算label和logits之间的交叉熵
"""
return tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred,
labels=label))
# 3:训练
#
def get_all_files(train_data_file):
"""
get all files
"""
train_file = []
train_path = train_data_file
if os.path.isdir(train_path):
data_parts = os.listdir(train_path)
for part in data_parts:
train_file.append(os.path.join(train_path, part))
else:
train_file.append(train_path)
return train_file
def load_batch_ops(example, batch_size, shuffle):
"""
load batch ops
"""
if not shuffle:
return tf.train.batch([example],
batch_size = batch_size,
num_threads = 1,
capacity = 10000 + 2 * batch_size)
else:
return tf.train.shuffle_batch([example],
batch_size = batch_size,
num_threads = 1,
capacity = 10000 + 2 * batch_size,
min_after_dequeue = 10000)
#获取PointwisePadding的数据
class TFPointwisePaddingData(object):
"""
for pointwise padding data
"""
def __init__(self, config):
self.filelist = get_all_files(config["train_file"]) #获取训练路径下的所有训练文件数据
self.batch_size = int(config["batch_size"])
self.epochs = int(config["num_epochs"])
if int(config["shuffle"]) == 0:
shuffle = False
else:
shuffle = True
self.shuffle = shuffle
self.reader = None
self.file_queue = None
self.left_slots = dict(config["left_slots"])
self.right_slots = dict(config["right_slots"])
def ops(self):
"""
gen data
"""
self.file_queue = tf.train.string_input_producer(self.filelist,
num_epochs=self.epochs) #将训练数据文件加到队列中
self.reader = tf.TFRecordReader()
_, example = self.reader.read(self.file_queue)
batch_examples = load_batch_ops(example, self.batch_size, self.shuffle) #获取批数据
features_types = {"label": tf.FixedLenFeature([2], tf.int64)}
[features_types.update({u: tf.FixedLenFeature([v], tf.int64)})
for (u, v) in self.left_slots.items()]
[features_types.update({u: tf.FixedLenFeature([v], tf.int64)})
for (u, v) in self.right_slots.items()]
features = tf.parse_example(batch_examples, features=features_types)
return dict([(k, features[k]) for k in self.left_slots.keys()]), \
dict([(k, features[k]) for k in self.right_slots.keys()]), \
features["label"]
#获取PairwisePadding的数据
class TFPairwisePaddingData(object):
"""
for pairwise padding data
"""
def __init__(self, config):
self.filelist = get_all_files(config["train_file"])
self.batch_size = int(config["batch_size"])
self.epochs = int(config["num_epochs"])
if int(config["shuffle"]) == 0:
shuffle = False
else:
shuffle = True
self.shuffle = shuffle
self.reader = None
self.file_queue = None
self.left_slots = dict(config["left_slots"])
self.right_slots = dict(config["right_slots"])
def ops(self):
"""
produce data
"""
self.file_queue = tf.train.string_input_producer(self.filelist,
num_epochs=self.epochs)
self.reader = tf.TFRecordReader()
_, example = self.reader.read(self.file_queue)
batch_examples = load_batch_ops(example, self.batch_size, self.shuffle)
features_types = {}
[features_types.update({u: tf.FixedLenFeature([v], tf.int64)})
for (u, v) in self.left_slots.items()]
[features_types.update({"pos_" + u: tf.FixedLenFeature([v], tf.int64)})
for (u, v) in self.right_slots.items()]
[features_types.update({"neg_" + u: tf.FixedLenFeature([v], tf.int64)})
for (u, v) in self.right_slots.items()]
features = tf.parse_example(batch_examples, features=features_types)
return dict([(k, features[k]) for k in self.left_slots.keys()]), \
dict([(k, features["pos_" + k]) for k in self.right_slots.keys()]), \
dict([(k, features["neg_" + k]) for k in self.right_slots.keys()])
#训练时调用的函数
def run_trainer(loss, optimizer, config):
"""
run classification training function handle
"""
thread_num = int(config["thread_num"])
model_path = config["model_path"]
model_file = config["model_prefix"]
print_iter = int(config["print_iter"])
data_size = int(config["data_size"])
batch_size = int(config["batch_size"])
epoch_iter = int(data_size / batch_size)
avg_cost = 0.0
saver = tf.train.Saver(max_to_keep=None)
init = tf.group(tf.global_variables_initializer(),
tf.local_variables_initializer())
with tf.Session(config=tf.ConfigProto(intra_op_parallelism_threads=thread_num,
inter_op_parallelism_threads=thread_num)) \
as sess:
sess.run(init)
coord = tf.train.Coordinator()
read_thread = tf.train.start_queue_runners(sess=sess, coord=coord)
step = 0
epoch_num = 1
start_time = time.time()
while not coord.should_stop():
try:
step += 1
c, _ = sess.run([loss, optimizer])
avg_cost += c
if step % print_iter == 0:
print("loss: %f" % ((avg_cost / print_iter)))
avg_cost = 0.0
if step % epoch_iter == 0:
end_time = time.time()
print("save model epoch%d, used time: %d" % (epoch_num,
end_time - start_time))
save_path = saver.save(sess,
"%s/%s.epoch%d" % (model_path, model_file, epoch_num))
epoch_num += 1
start_time = time.time()
except tf.errors.OutOfRangeError:
save_path = saver.save(sess, "%s/%s.final" % (model_path, model_file))
coord.request_stop()
coord.join(read_thread)
sess.close()
#训练
def train(conf_dict):
"""
train
"""
training_mode = conf_dict["training_mode"]
net = MLPCnn(config) #获得配置文件中需要的训练网络
datafeed =TFPointwisePaddingData(conf_dict) #获取pairwise格式的数据
input_l, input_r, label_y = datafeed.ops()
pred = net.predict(input_l, input_r) #预测匹配分数
output_prob = tf.nn.softmax(pred, -1, name="output_prob")
loss = SoftmaxWithLoss().ops(pred, label_y) #通过交叉熵损失进行优化
# define optimizer
lr = float(conf_dict["learning_rate"])
optimizer = tf.train.AdamOptimizer(learning_rate=lr).minimize(loss) #优化器
# run_trainer
run_trainer(loss, optimizer, conf_dict)#训练
#预测阶段
def run_predict(pred, label, config):
"""
run classification predict function handle
"""
mean_acc = 0.0
saver = tf.train.Saver()
mode = config["training_mode"]
label_index = tf.argmax(label, 1)
pred_prob = tf.nn.softmax(pred, -1)
score = tf.reduce_max(pred_prob, -1)
pred_index = tf.argmax(pred_prob, 1)
correct_pred = tf.equal(pred_index, label_index)
acc = tf.reduce_mean(tf.cast(correct_pred, "float"))
modelfile = config["test_model_file"]
result_file = open(config["test_result"], "w")
step = 0
init = tf.group(tf.global_variables_initializer(),
tf.local_variables_initializer())
with tf.Session(config=tf.ConfigProto(intra_op_parallelism_threads=1)) \
as sess:
sess.run(init)
saver.restore(sess, modelfile)
coord = tf.train.Coordinator()
read_thread = tf.train.start_queue_runners(sess=sess, coord=coord)
while not coord.should_stop():
step += 1
try:
ground, pi, a, prob = sess.run([label_index, pred_index, acc, score])
mean_acc += a
for i in range(len(prob)):
result_file.write("%d\t%d\t%f\n" % (ground[i], pi[i], prob[i]))
except tf.errors.OutOfRangeError:
coord.request_stop()
coord.join(read_thread)
sess.close()
result_file.close()
mean_acc = mean_acc / step
print("accuracy: %4.2f" % (mean_acc * 100))
def predict(conf_dict):
"""
predict
"""
net = MLPCnn(config)
conf_dict.update({"num_epochs": "1", "batch_size": "1",
"shuffle": "0", "train_file": conf_dict["test_file"]})
test_datafeed = TFPointwisePaddingData(conf_dict)
test_l, test_r, test_y = test_datafeed.ops() #获得测试时需要输入的TFPointwisePaddingData
# test network
pred = net.predict(test_l, test_r)
run_predict(pred, test_y, conf_dict)
if __name__ == '__main__':
task_conf='cnn-pointwise2.json'
config = load_config(task_conf)
train(config)
predict(config)三、源码各部分功能总结
源码:https://github.com/baidu/AnyQ/tree/master/tools/simnet/train/tf
使用源码时,我们所需要的参数必须通过examples文件下的json文件进行配置,来选取不同的网络结构,损失函数和参数类型。
另外的6种网络结构:
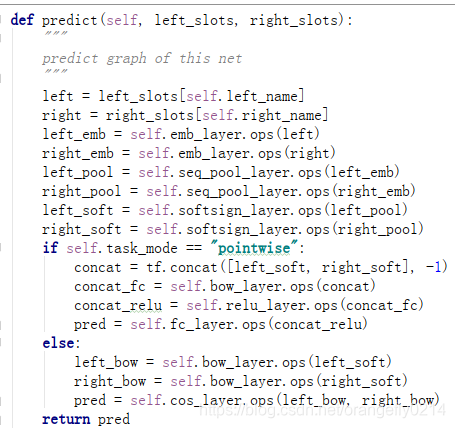
1. bow:
softsign激活函数值Softsign 是 Tanh 激活函数的另一个替代选择
像 Tanh 一样,Softsign 是反对称、去中心、可微分,并返回-1 和 1 之间的值。其更平坦的曲线与更慢的下降导数表明它可以更高效地学习,比tanh更好的解决梯度消失的问题。另一方面,导数的计算比 Tanh 更麻烦;
2. knrm网络

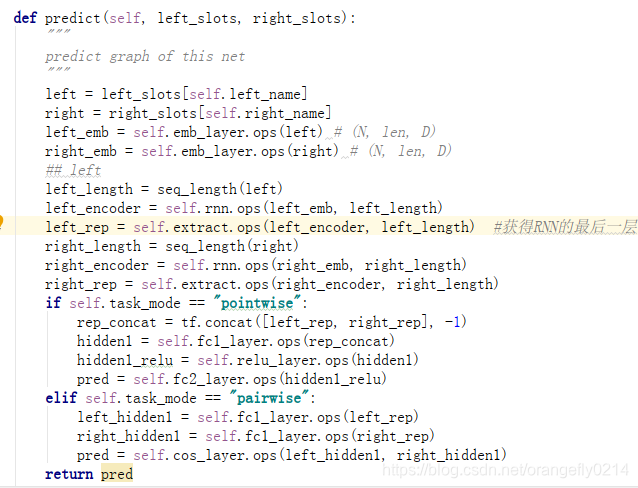
3. LSTM网络
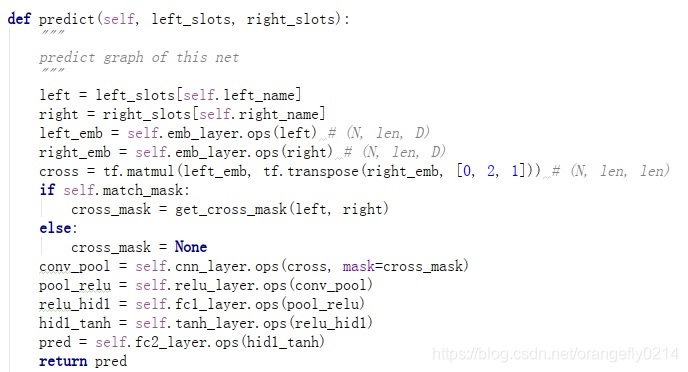
4. matchpyramid网络
5. mm_dnn网络:双向LSTM+dynamicDNNlayer

6. MVLSTM网络

通过源码的代码我们可以看到每种网络结构都是有哪些层堆积起来的。
知道每个模块的功能,并选用合理的网络结构和损失函数,我们通过配置相关的json参数文件,就可以获得自己的模型,并完成相关语义匹配任务。