一、简介
来自论文:《Attention is all you need》
由google团队在2017年发表于NIPS,Transformer 是一种新的、基于 attention 机制来实现的特征提取器,可用于代替 CNN 和 RNN 来提取序列的特征。 在该论文中 Transformer 用于 encoder - decoder 架构。事实上 Transformer 可以单独应用于 encoder 或者单独应用于 decoder 。
Transformer相比较LSTM等循环神经网络模型的优点:
- 可以直接捕获序列中的长距离依赖关系;
- 模型并行度高,使得训练时间大幅度降低。
二、结构
1.Transformer = 编码器 + 解码器
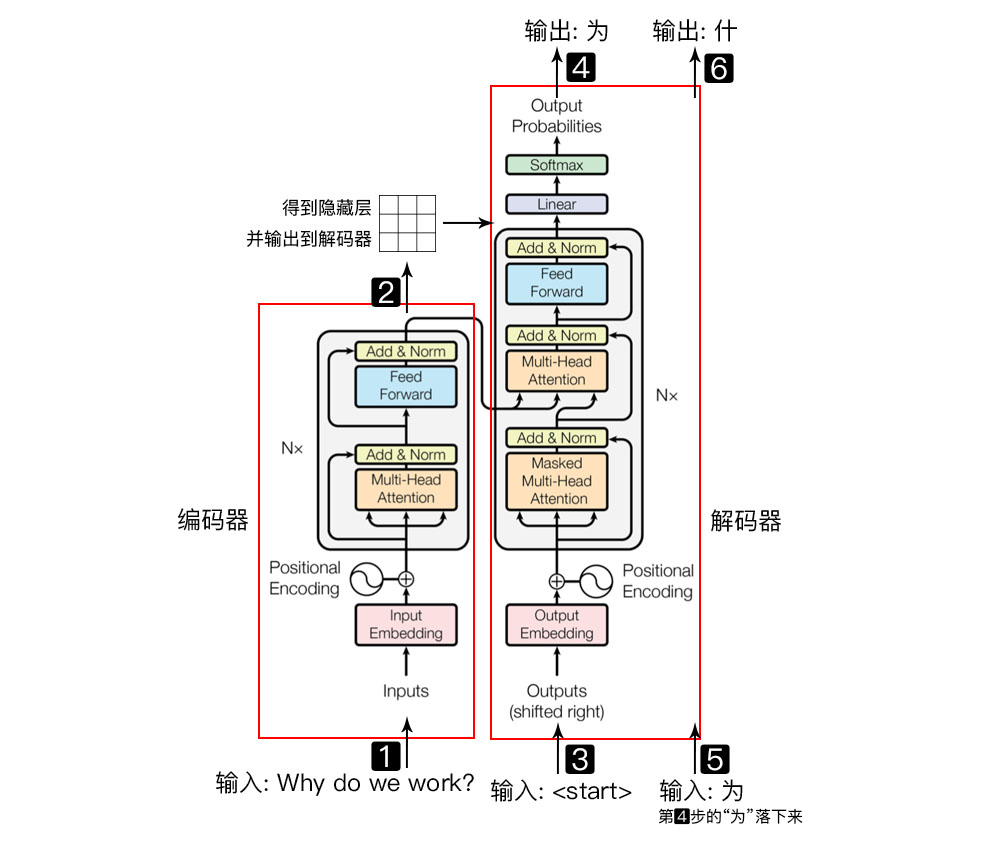
- 输入自然语言序列到编码器: Why do we work?(为什么要工作);
- 编码器输出的隐藏层, 再输入到解码器;
- 输入$<start>$(起始)符号到解码器;
- 得到第一个字"为";
- 将得到的第一个字"为"落下来再输入到解码器;
- 得到第二个字"什";
- 将得到的第二字再落下来, 直到解码器输出$<end>$(终止符), 即序列生成完成.
2.编码器
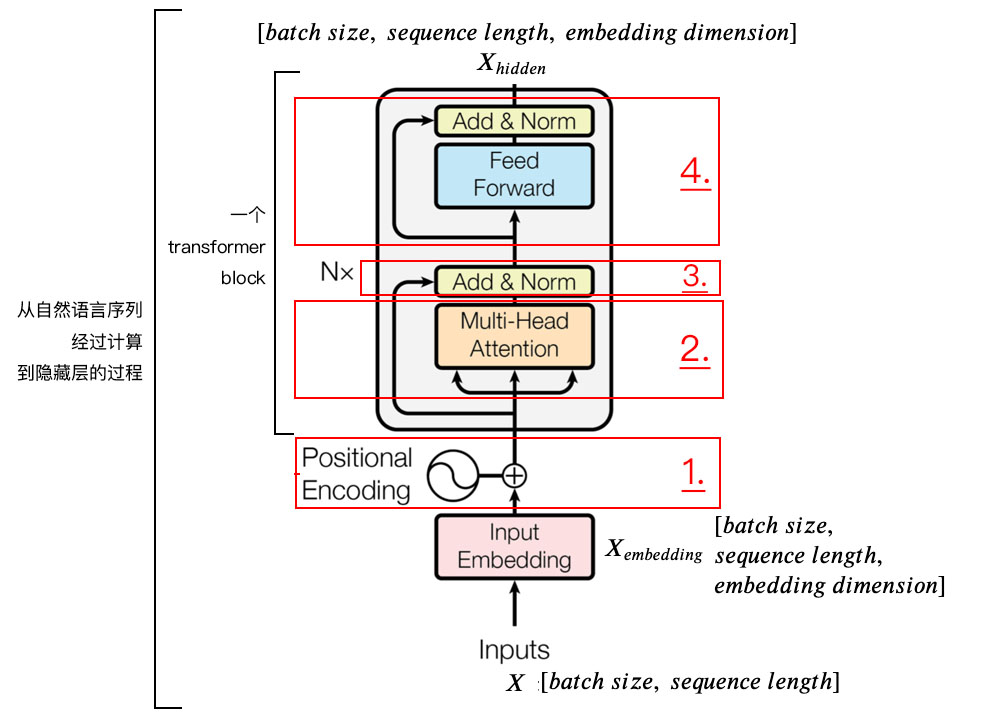
整体结构:
1) 字向量与位置编码:
$$X = EmbeddingLookup(X) + PositionalEncoding$$
$$X \in \mathbb{R}^{batch \ size \ * \ seq. \ len. \ * \ embed. \ dim.} $$
2) 自注意力机制:
$$Q = Linear(X) = XW_{Q}$$
$$K = Linear(X) = XW_{K} \tag{eq.3}$$
$$V = Linear(X) = XW_{V}$$
$$X_{attention} = SelfAttention(Q, \ K, \ V) \tag{eq.4}$$
3) 残差连接与Layer Normalization
$$X_{attention} = X + X_{attention} \tag{eq. 5}$$
$$X_{attention} = LayerNorm(X_{attention}) \tag{eq. 6}$$
4) $FeedForward$, 其实就是两层线性映射并用激活函数激活, 比如说$ReLU$:
$$X_{hidden} = Activate(Linear(Linear(X_{attention}))) \tag{eq. 7}$$
5) 重复3):
$$X_{hidden} = X_{attention} + X_{hidden}$$
$$X_{hidden} = LayerNorm(X_{hidden})$$
$$X_{hidden} \in \mathbb{R}^{batch \ size \ * \ seq. \ len. \ * \ embed. \ dim.} $$
2.1 positional encoding位置嵌入(或位置编码)
由于transformer模型没有循环神经网络的迭代操作, 所以我们必须提供每个字的位置信息给transformer, 才能识别出语言中的顺序关系.
现在定义一个位置嵌入的概念, 也就是positional encoding, 位置嵌入的维度为[max sequence length, embedding dimension], 嵌入的维度同词向量的维度, max sequence length属于超参数, 指的是限定的最大单个句长.
注意, 我们一般以字为单位训练transformer模型, 也就是说我们不用分词了, 首先我们要初始化字向量为[vocab size, embedding dimension], vocab size为总共的字库数量, embedding dimension为字向量的维度, 也是每个字的数学表达.
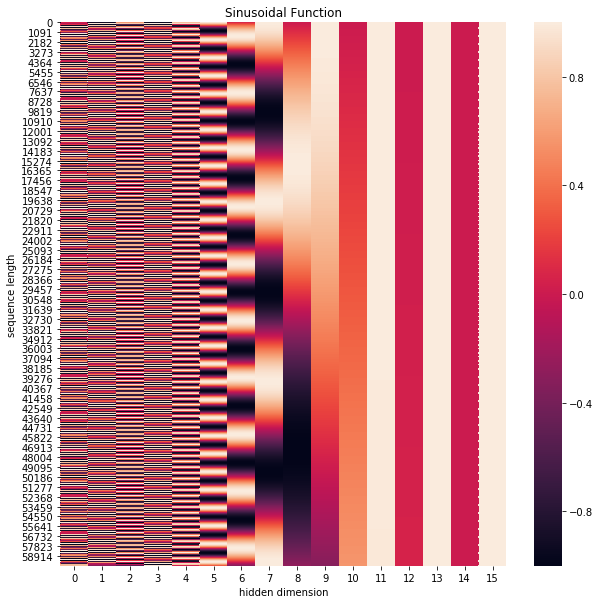
在这里论文中使用了$sine$和$cosine$函数的线性变换来提供给模型位置信息:
- $$PE_{(pos,2i)} = sin(pos / 10000^{2i/d_{/text{model}}})$$
- $$PE_{(pos,2i+1)} = cos(pos / 10000^{2i/d_{\text{model}}})$$
上式中$pos$指的是句中字的位置, 取值范围是[0, max sequence length), i指的是词向量的维度, 取值范围是[0, embedding dimension), 上面有$sin$和$cos$一组公式, 也就是对应着embedding dimension维度的一组奇数和偶数的序号的维度, 例如0, 1一组, 2, 3一组, 分别用上面的$sin$和$cos$函数做处理, 从而产生不同的周期性变化, 而位置嵌入在embedding dimension维度上随着维度序号增大, 周期变化会越来越慢, 而产生一种包含位置信息的纹理, 就像论文原文中第六页讲的, 位置嵌入函数的周期从$2 \pi$到$10000 * 2 \pi$变化, 而每一个位置在embedding dimension维度上都会得到不同周期的$sin$和$cos$函数的取值组合, 从而产生独一的纹理位置信息, 模型从而学到位置之间的依赖关系和自然语言的时序特性.
下面画一下位置嵌入, 可见纵向观察, 随着embedding dimension增大, 位置嵌入函数呈现不同的周期变化.