1、高斯模糊
1.1 numpy 实现高斯模糊
代码如下:
import cv2 as cv
import numpy as np
#截断函数
def clamp(pv):
if pv > 255:
return 255
else:
return pv
#高斯滤波
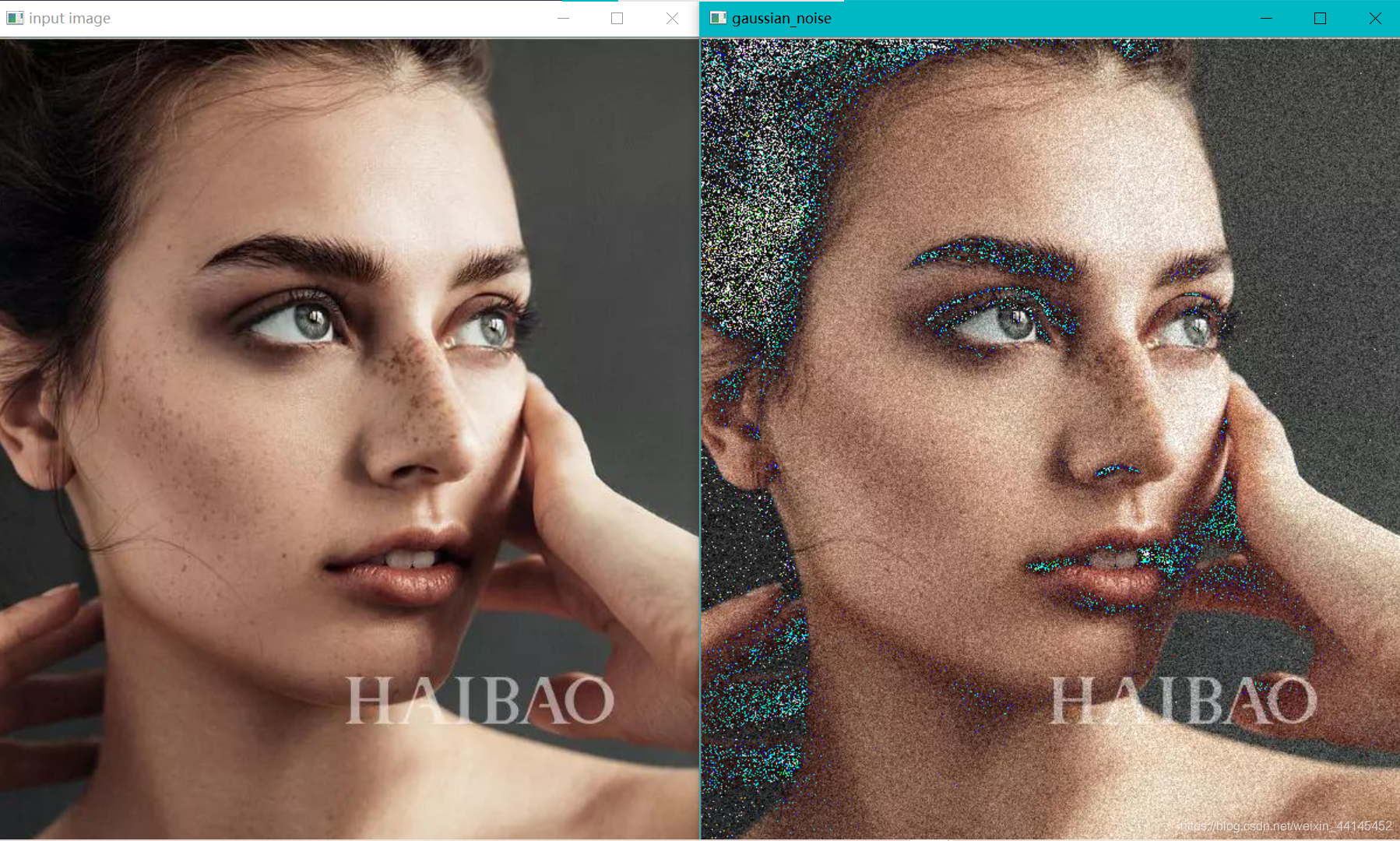
def gaussian_noise(image):
h, w, c = image.shape
for row in range(h):
for col in range(w):
s = np.random.normal(0, 20, 3)#0是矩阵中所有随机数的平均值,20是标准差,3是形状(1行3列)
b = image[row, col, 0] #blue
g = image[row, col, 1] # green
r = image[row, col, 2] # red
image[row, col, 0] = clamp(b + s[0])
image[row, col, 1] = clamp(g + s[0])
image[row, col, 2] = clamp(r + s[0])
cv.imshow("gaussian_noise", image)
src = cv.imread("C:/Users/lenovo/Desktop/opencv/daima/banknum/template-matching-ocr/images/quzao.jpg") #读取图片位置
cv.namedWindow("input image", cv.WINDOW_AUTOSIZE)
cv.imshow("input image", src)
t1 = cv.getTickCount()
gaussian_noise(src)
t2 = cv.getTickCount()
time = (t2 - t1)/cv.getTickFrequency()
print(time)
cv.waitKey(0)
cv.destroyAllWindows()
numpy实现时间较慢,大约5,6秒
运行截图:
 np.random.normal()正态分布
np.random.normal()正态分布
高斯分布的概率密度函数
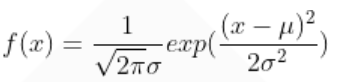
numpy中
numpy.random.normal(loc=0.0, scale=1.0, size=None)
参数的意义为:
loc:float概率分布的均值,对应着整个分布的中心center
scale:float概率分布的标准差,对应于分布的宽度,scale越大越矮胖,scale 越小,越瘦高
size:int or tuple of ints
输出的shape,默认为None,只输出一个值
我们更经常会用到np.random.randn(size)所谓标准正太分布(μ=0, σ=1),对应于np.random.normal(loc=0, scale=1, size)
1.2 opencv实现高斯模糊
实现方法:GaussianBlur
处理结果=cv2.GaussianBlur(原始图像src,核函数大小ksize,sigmaX)
核函数大小ksize:(N,N)必须是奇数
sigmaX:控制x方向方差,控制权重,一般取0,它自己去计算方差。y轴方差和x一致
 代码如下:
代码如下:
import cv2 as cv
src = cv.imread("C:/Users/lenovo/Desktop/opencv/daima/banknum/template-matching-ocr/images/quzao.jpg") #读取图片位置
cv.namedWindow("input image", cv.WINDOW_AUTOSIZE)
cv.imshow("input image", src)
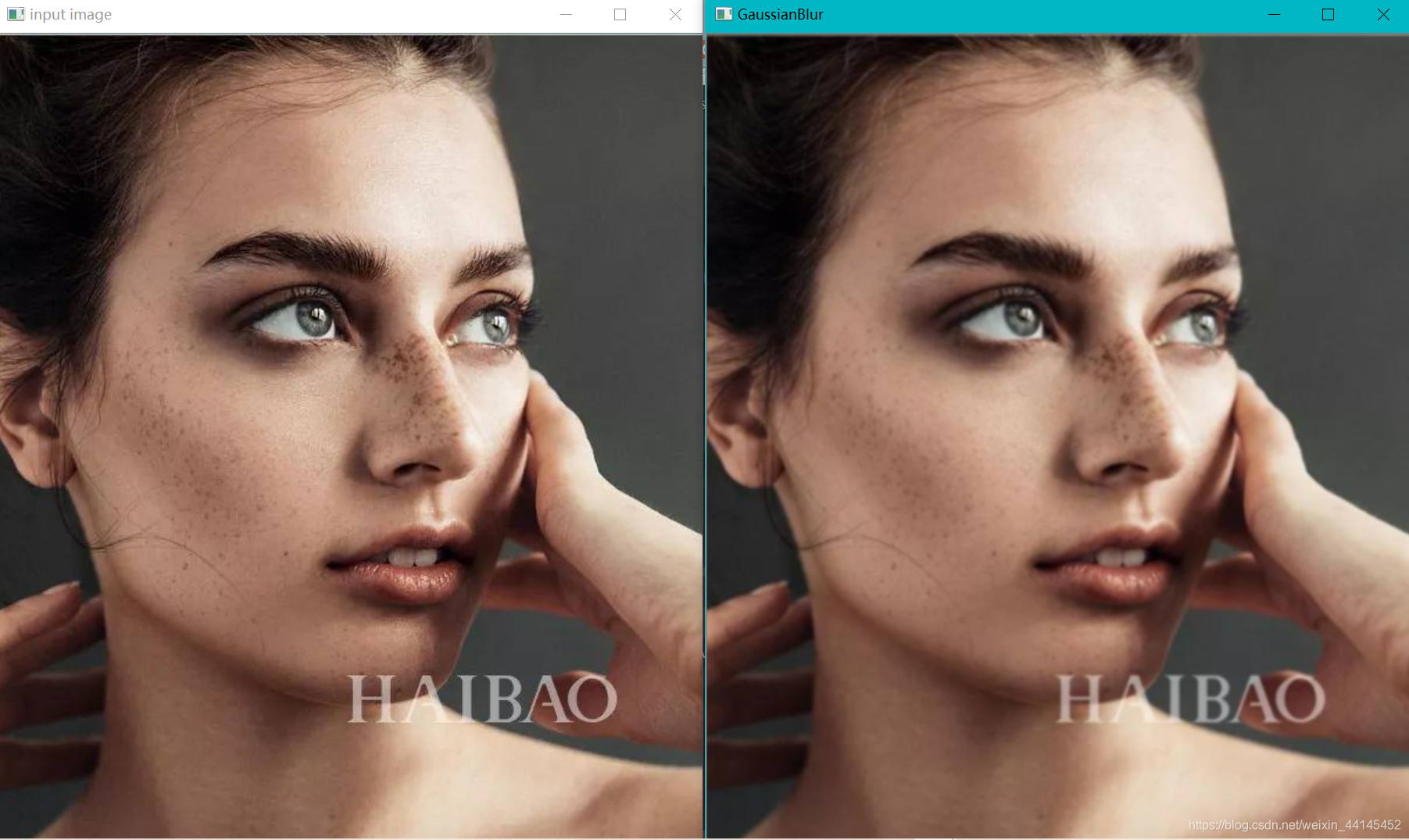
dst = cv.GaussianBlur(src, (5, 5), 0)
cv.imshow("GaussianBlur", dst)
cv.waitKey(0)
cv.destroyAllWindows()
运行截图:
 dst = cv.GaussianBlur(src, (0, 0), 15)时
dst = cv.GaussianBlur(src, (0, 0), 15)时
import cv2 as cv
src = cv.imread("C:/Users/lenovo/Desktop/opencv/daima/banknum/template-matching-ocr/images/quzao.jpg") #读取图片位置
cv.namedWindow("input image", cv.WINDOW_AUTOSIZE)
cv.imshow("input image", src)
dst = cv.GaussianBlur(src, (5, 5), 0)
cv.imshow("GaussianBlur", dst)
cv.waitKey(0)
cv.destroyAllWindows()
运行截图:
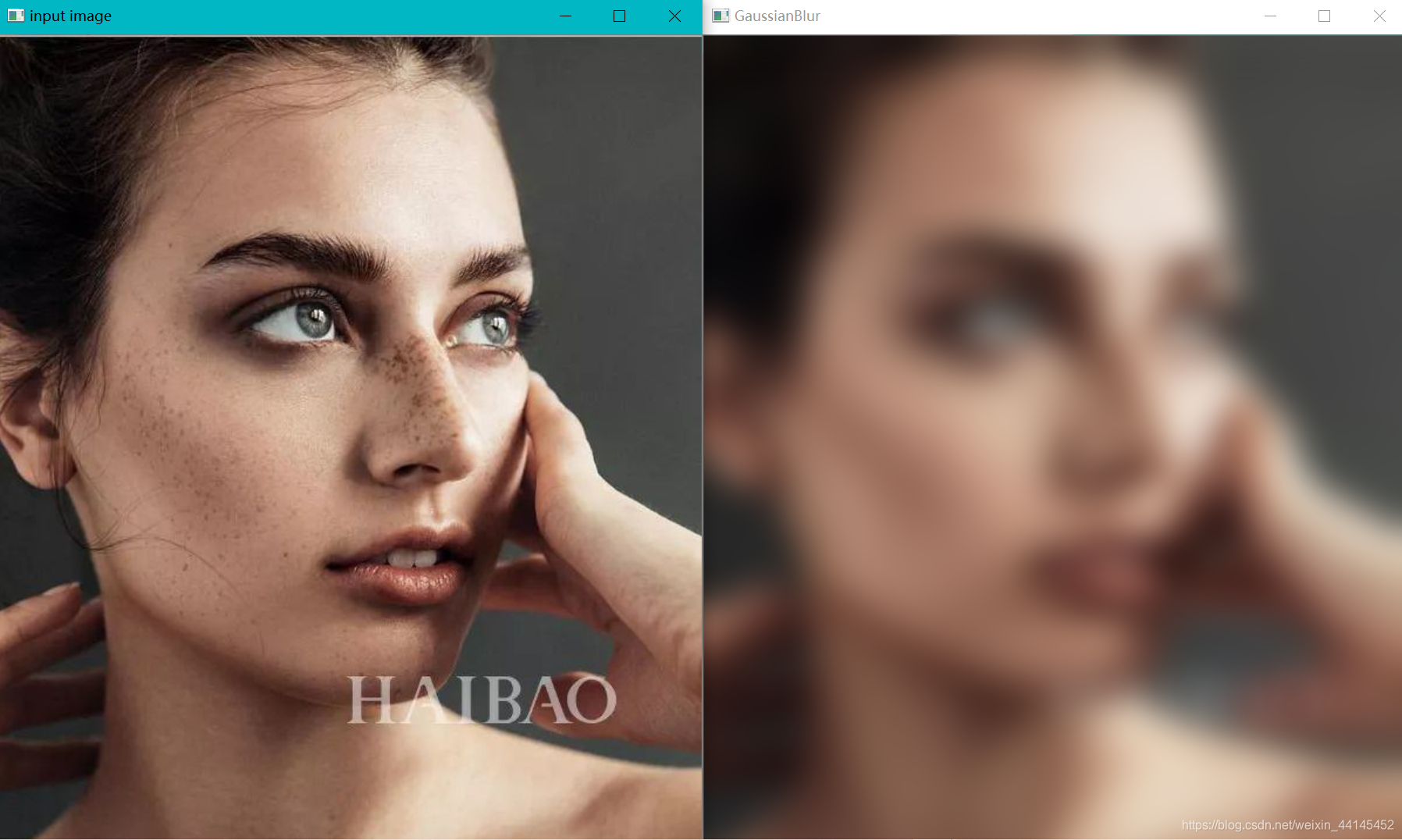 这种情况我们称之为 “毛玻璃”,它的轮廓还在,但她很模糊,因为它考虑到每个像素的权重,它当前的权重是最大的没有被平均。它还保留了图像的基本特征,比均值模糊要好一些。(均值模糊表示背锅)
这种情况我们称之为 “毛玻璃”,它的轮廓还在,但她很模糊,因为它考虑到每个像素的权重,它当前的权重是最大的没有被平均。它还保留了图像的基本特征,比均值模糊要好一些。(均值模糊表示背锅)
2、边缘保留滤波EPF
之前介绍了无论是均值还是高斯都是属于模糊卷积,它们都有一个共同的特点就是模糊之后图像的边缘信息不复存在,受到了破坏。有一种滤波方法有能力通过卷积处理实现图像模糊的同时对图像边缘不会造成破坏,滤波之后的输出完整的保存了图像整体边缘(轮廓)信息,这类卷积滤波算法被称为边缘保留滤波算法(EPF)。
实现方法:高斯双边,均值迁移
使用场景:做图像滤镜。
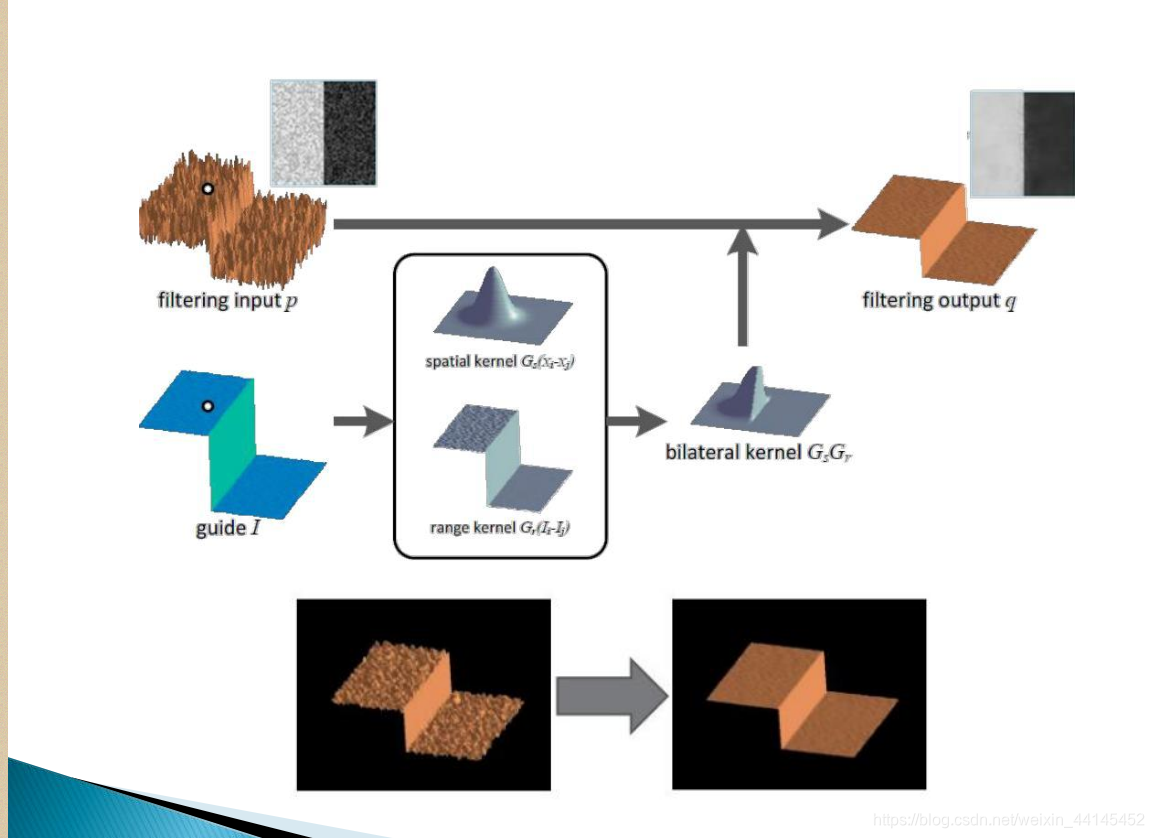 大白话讲解原理:首先对左边(黑白色图)进行高斯滤波,
大白话讲解原理:首先对左边(黑白色图)进行高斯滤波,
高斯滤波为下图,取值范围可以叫做空域

如果当前点与周围像素值差异较大如下图,范围可以叫为值域

则进行截断。得到

最后得到右图(黑巴色)。
高斯滤波参人为添加,像素差多少截断人为设计。
2.1 高斯 双边模糊原理
高斯滤波(空间临近)是将二维高斯正态分布放在图像矩阵上做卷积运算。考虑的是邻域内像素值的空间距离关系。通过在核大小范围内,各个点到中心点的空间临近度计算出对应的权值,并将计算好的核与图像矩阵作卷积。最后,图像经过滤波后达到平滑的效果,而图像上的边缘也会有一定程度的平滑,使得整个图像变得模糊,边缘得不到保存。
双边滤波基本思想:将高斯滤波(空间临近)中通过各个点到中心点的空间临近度计算的各个权值进行优化,将其优化为空间临近度计算的权值 和 像素值相似度计算的权值的乘积,优化后的权值再与图像作卷积运算。从而达到保边去噪的效果。
高斯双边模糊
dst=cv2.bilateralFilter(src, d, sigmaColor, sigmaSpace[, dst[, borderType]])
src:输入图像
d:过滤时周围每个像素领域的直径
sigmaColor:在color space中过滤sigma。参数越大,临近像素将会在越远的地方mix。
sigmaSpace:在coordinate space中过滤sigma。参数越大,那些颜色足够相近的的颜色的影响越大。
值域和空域的两个方差sigma可以简单的设置为相等,小于10,无太大效果,大于150效果太强,像卡通片似的。
讲解
滤波器尺寸d:大于5将较慢(5 forreal-time)d 是像素邻域“直径”。
Sigma_color较大,则在邻域中的像素值相差较大的像素点也会用来平均。
Sigma_space较大,则虽然离得较远,但是,只要值相近,就会互相影响。
将sigma_sapce设置较大,sigma_color设置较小,可获得较好的效果(椒盐噪声)。
双边滤波的内在想法是:在图像的值域(range)上做传统滤波器在空域(domain)上做的工作。空域滤波对空间上邻近的点进行加权平均,加权系数随着距离的增加而减少;值域滤波则是对像素值相近的点进行加权平均,加权系数随着值差的增大而减少。同时考虑对空间域与值域进行滤波的意义:将对图像进行平滑化的范围限制在值域较小的部分(也就是 光度/色彩差异较小的部分),如此便能够达到边缘保存的目的。(文字部分有借鉴别人的)
import cv2 as cv
import numpy as np
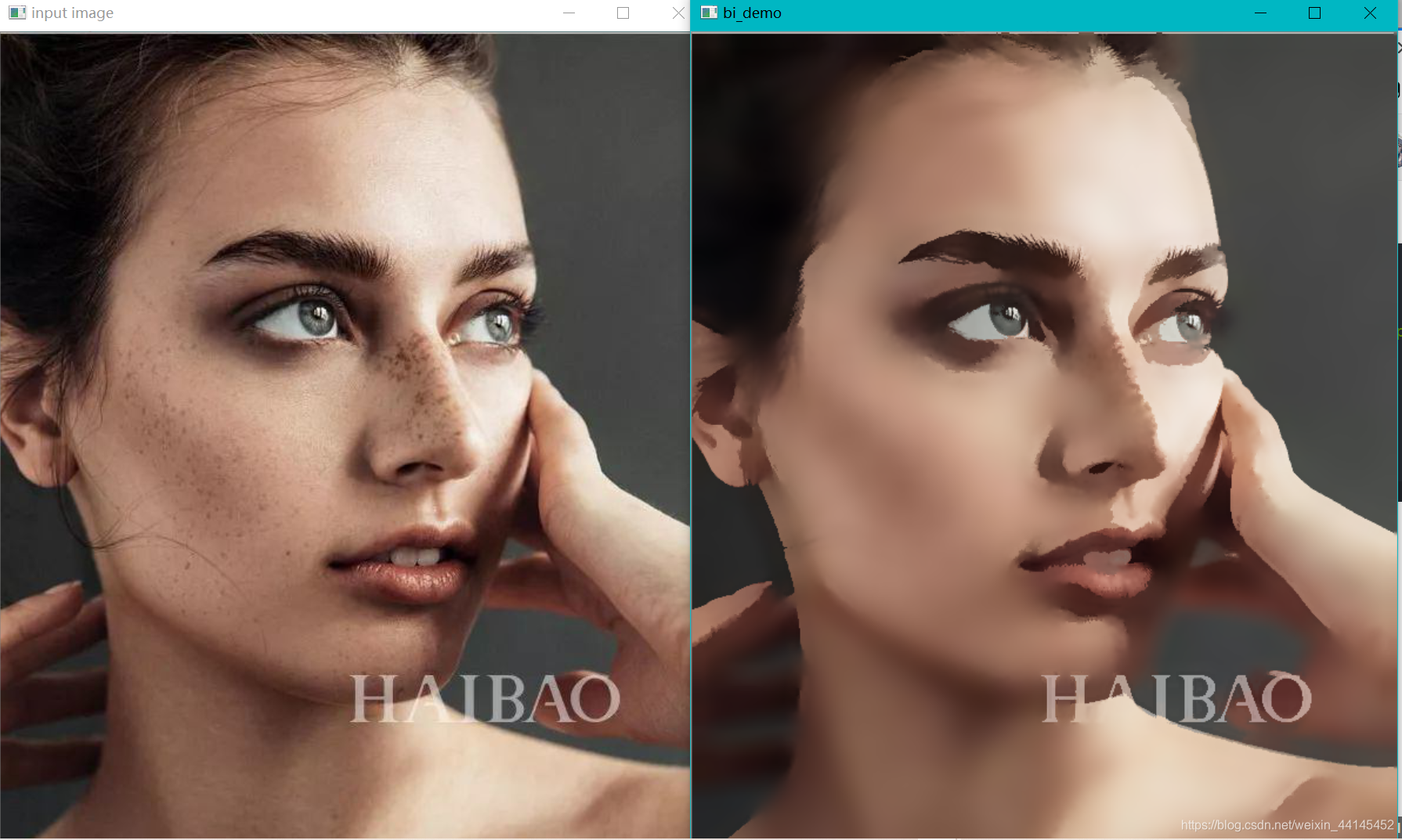
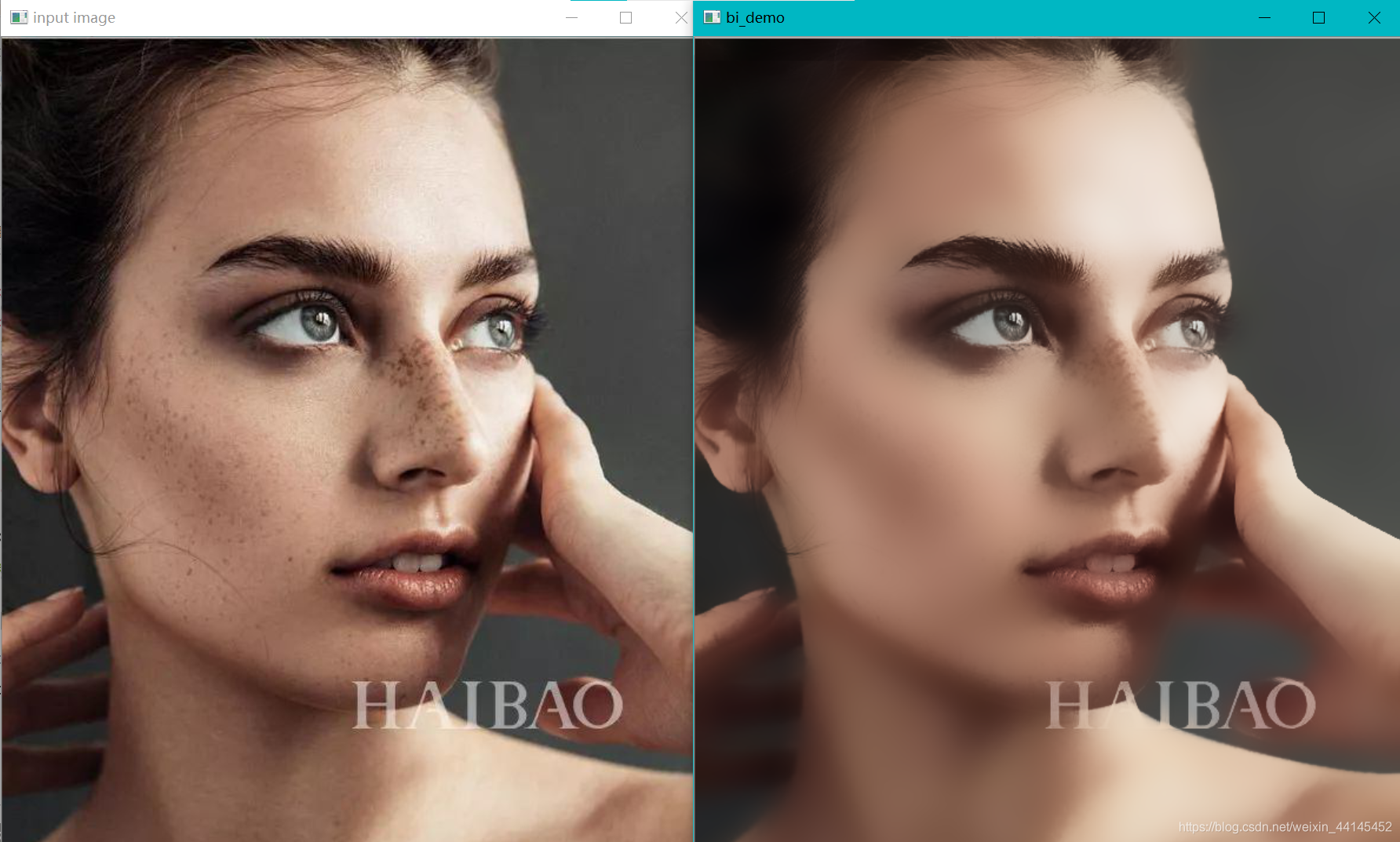
#高斯双边 更接近于磨皮效果
def bi_demo(image):
dst = cv.bilateralFilter(image, 0, 100, 15)
cv.imshow("bi_demo", dst)
src = cv.imread("C:/Users/lenovo/Desktop/opencv/daima/banknum/template-matching-ocr/images/quzao.jpg") #读取图片位置
cv.namedWindow("input image", cv.WINDOW_AUTOSIZE)
cv.imshow("input image", src)
bi_demo(src)
cv.waitKey(0)
cv.destroyAllWindows()
运行截图:
2.2 均值偏移
meanShfit均值漂移算法是一种通用的聚类算法,它的基本原理是:对于给定的一定数量样本,任选其中一个样本,以该样本为中心点划定一个圆形区域,求取该圆形区域内样本的质心,即密度最大处的点,再以该点为中心继续执行上述迭代过程,直至最终收敛。
dst = cv2.pyrMeanShiftFiltering(image, sp, sr,maxLevel,termcrit)
sp:漂移物理空间半径大小;
sr:漂移色彩空间半径大小;
maxLevel:定义金字塔的最大层数
termcrit:漂移迭代终止条件,可以设置为迭代次数满足终止,迭代目标与中心点偏差满足终止,或者两者的结合
步骤:
- 迭代空间构建:
以输入图像上src上任一点P0为圆心,建立物理空间上半径为sp,色彩空间上半径为sr的球形空间,物理空间上坐标2个—x、y,色彩空间上坐标3个—R、G、B(或HSV),构成一个5维的空间球体。
其中物理空间的范围x和y是图像的长和宽,色彩空间的范围R、G、B分别是0~255。 - 求取迭代空间的向量并移动迭代空间球体后重新计算向量,直至收敛:
在1中构建的球形空间中,求得所有点相对于中心点的色彩向量之和后,移动迭代空间的中心点到该向量的终点,并再次计算该球形空间中所有点的向量之和,如此迭代,直到在最后一个空间球体中所求得的向量和的终点就是该空间球体的中心点Pn,迭代结束。 - 更新输出图像dst上对应的初始原点P0的色彩值为本轮迭代的终点Pn的色彩值,如此完成一个点的色彩均值漂移。
- 对输入图像src上其他点,依次执行步骤1,、2、3,遍历完所有点位后,整个均值偏移色彩滤波完成,
import cv2 as cv
import numpy as np
#均值迁移 可能会过度模糊,有种油画的效果
def shift_demo(image):
dst = cv.pyrMeanShiftFiltering(image, 10, 50)
cv.imshow("bi_demo", dst)
src = cv.imread("C:/Users/lenovo/Desktop/opencv/daima/banknum/template-matching-ocr/images/quzao.jpg") #读取图片位置
cv.namedWindow("input image", cv.WINDOW_AUTOSIZE)
cv.imshow("input image", src)
shift_demo(src)
cv.waitKey(0)
cv.destroyAllWindows()
运行截图: