全部笔记的汇总贴:《深度学习》花书-读书笔记汇总贴
《深度学习》PDF免费下载:《深度学习》
一、概率
直接与事件发生的频率相联系,被称为频率派概率(frequentist probability);
涉及到确定性水平,被称为贝叶斯概率(Bayesian probability)。
二、随机变量
随机变量可以是离散的或者连续的。
三、概率分布
用来描述随机变量或一簇随机变量在每一个可能取到的状态的可能性大小。我们描述概率分布的方式取决于随机变量是离散的还是连续的。
离散型变量的概率分布可以用概率质量函数来描述;当我们研究的对象是连续型随机变量时,我们用概率密度函数来描述它的概率分布。
四、边缘概率
我们知道了一组变量的联合概率分布,但想要了解其中一个子集的概率分布。这种定义在子集上的概率分布被称为边缘概率分布(marginal probability distribution)。
五、条件概率
在很多情况下,我们感兴趣的是某个事件,在给定其他事件发生时出现的概率,这种概率叫做条件概率。
六、条件概率的链式法则
P ( a , b , c ) = P ( a ∣ b , c ) P ( b , c ) = P ( a ∣ b , c ) P ( b ∣ c ) P ( c ) P(a,b,c)=P(a|b,c)P(b,c)=P(a|b,c)P(b|c)P(c) P(a,b,c)=P(a∣b,c)P(b,c)=P(a∣b,c)P(b∣c)P(c)
七、独立性和条件独立性
两个随机变量 x x x和 y y y,如果它们的概率分布可以表示成两个因子的乘积形式,并且一个因子只包含 x x x另一个因子只包含 y y y,我们就称这两个随机变量是相互独立的(independent)。
x ⊥ y x\bot y x⊥y
如果关于 x x x和 y y y的条件概率分布对于 z z z的每一个值都可以写成乘积的形式,那么这两个随机变量 x x x和 y y y在给定随机变量 z z z时是条件独立的(conditionally independent)。 x ⊥ y ∣ z x\bot y|z x⊥y∣z
八、期望、方差和协方差
协方差(covariance)在某种意义上给出了两个变量线性相关性的强度以及这些变量的尺度: C o v ( f ( x ) , g ( y ) ) = E [ ( f ( x ) − E [ f ( x ) ] ) ( g ( y ) − E [ g ( y ) ] ) ] Cov(f(x),g(y))=E[(f(x)-E[f(x)])(g(y)-E[g(y)])] Cov(f(x),g(y))=E[(f(x)−E[f(x)])(g(y)−E[g(y)])]

九、常用概率分布
- Bernoulli 分布
- Multinoulli 分布(multinoulli distribution)或者范畴分布(categorical dis-tribution)
- 正态分布(normal distribution)或者高斯分布(Gaussian distribution)
- 指数分布(exponential distribution)
- Laplace 分布(Laplace distribution)
- Dirac 分布或经验分布(empirical distribution)
- 混合分布(mixture distribution)(GMM高斯混合模型)
十、常用函数的有用性质
logistic sigmoid 函数: σ ( x ) = 1 1 + exp ( − x ) \sigma(x)=\frac1{1+\exp(-x)} σ(x)=1+exp(−x)1
softplus 函数(softplus function): ζ ( x ) = log ( 1 + exp ( x ) ) \zeta (x)=\log(1+\exp(x)) ζ(x)=log(1+exp(x))
一些常用性质:
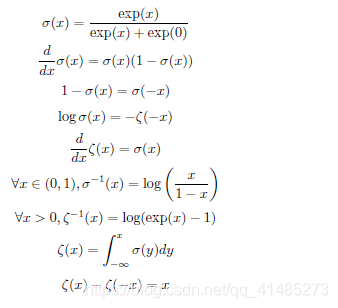
十一、贝叶斯规则
P ( x ∣ y ) = P ( x ) P ( y ∣ x ) P ( y ) P(x|y)=\frac{P(x)P(y|x)}{P(y)} P(x∣y)=P(y)P(x)P(y∣x)
十二、连续型变量的技术细节
十三、信息论
主要研究的是对一个信号包含信息的多少进行量化。
我们用KL 散度(Kullback-Leibler (KL) divergence)来衡量两个分布的差异: D K L ( P ∣ ∣ Q ) = E x ∼ P [ log P ( x ) Q ( x ) ] = E x ∼ P [ log P ( x ) − log Q ( x ) ] D_{KL}(P||Q)=E_{x\sim P}\Big[\log\frac{P(x)}{Q(x)}\Big]=E_{x\sim P}\Big[\log{P(x)}-\log{Q(x)}\Big] DKL(P∣∣Q)=Ex∼P[logQ(x)P(x)]=Ex∼P[logP(x)−logQ(x)]
KL 散度有很多有用的性质,最重要的是它是非负的。KL 散度为 0 当且仅当 P P P和 Q Q Q在离散型变量的情况下是相同的分布,或者在连续型变量的情况下是 ‘‘几乎处处’’ 相同的。
十四、结构化概率模型
有两种主要的结构化概率模型:有向的和无向的。有向或者无向不是概率分布的特性;它是概率分布的一种特殊描述(description)所具有的特性,而任何概率分布都可以用这两种方式进行描述。
下一章传送门:花书读书笔记(三)-数值计算